
跨模態搜尋(cross-modal/media retrieval)
跨模態搜尋研究的基本內容是尋找不同模態樣本之間的關係,實現利用某一種模態樣本,搜尋近似語義的其他模態樣本。
本文實現了論文《Joint Feature Selection and Subspace Learning for Cross-Modal Retrieval》(PAMI2016)和論文《Simple to Complex Cross-modal Learning to Rank》(arxiv.org 2017.2)。並對實現的結果進行了一些討論。
2、演算法內容2.1 論文《Joint Feature Selection and SubspaceLearning for Cross-Modal Retrieval》(JFSSL)(PAMI2016)
程式碼連線:https://github.com/2012013382/JFSSL-Cross-Modal-Retrieval
此論文是對於論文《Spectral Regression for Efficient Regularized Subspace Learning》(ICCV2007)和論文《L21Regularized Correntropy for Robust Feature Selection》的結合。其主要的目的是為了最優化目標函式(1)。
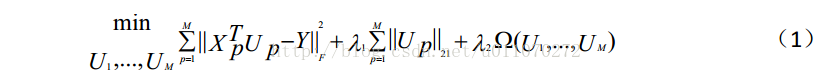
其中,M為模態的類別數,在此,我們只考慮圖片和文字之間互相搜尋的情況,因此M=2;Up表示對應模態的對映矩陣;Xp表示輸入的訓練樣本;Y表示樣本的標籤;第三項為模態間/模態內相似度函式;lambda1和lambda2為兩個設定的閾值。
最優化這個目標函式的目的就是為了得到對映矩陣Up。通過對映矩陣,便可以將不同模態的特徵資料對映到相同的子空間中,再通過cosine相似度度量,即可得到不同模態資料之間的相似度。
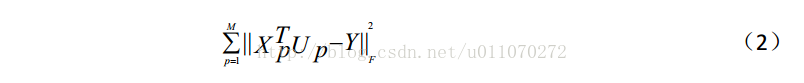
如公式(2)所示,它的形式是一個基本的均方誤差,最小化這個均方誤差,便可以使得對映矩陣朝著理想的方向變化。
公式( 1) 的第二項為一個 L2,1 範數約束項, 它的存在實現了對於輸入樣本的特徵選擇, 可以達到防止過擬合的目的。 通過調整lambda1的值, 可以調整該約束的
影響程度。 在具體的實現中, 利用了“ 凸優化” 的內容, 對該項進行了合理的轉化, 使得整個目標函式保持凸函式的性質。

第三項是多模態的圖約束項,它能夠使得子空間中,不同模態但類別相同的樣本儘量靠近;相同模態類別相同的樣本也儘量靠近。

由於目標函式(1)是一個凸函式,因此可以直接進行求導,並且使導數為0,此時得到的對映矩陣Up,即為最優的對映矩陣。
2.2 論文《Simple to Complex Cross-modal Learning to Rank》(SCCLR)(arxiv.org 2017.2)
該論文的想法來自於論文《A Self-paced Multiple-instance Learning Framework for Co-saliency Detection》(SMLFCD)(ICCV 2015),原文提出了一種尋找多張圖片相似部分的方法,如圖1所示。

其中,第一行為四張原圖,第二行為四張圖片的相似部分,第三行為演算法SMLFCD的結果。論文SCCLR的作者認為,上述方法既然可以挖掘圖片之間的相似成分,自然也可以將其遷移到多模態的相似成分挖掘工作上,因此仿照演算法SMLFCD,作者設計了演算法SCCLR。該演算法的基本思路為:利用從簡單樣本到複雜樣本的學習思想,提高最終的學習效果。具體來說,利用一種圖片搜尋相似主題的文字,雖然均為同一類別,但是同類別的文字與該圖片的相似度依然有差異,利用這個差異可以設定不同樣本對對映矩陣更新的影響程度,從而得到更好的結果。作者建立了目標函式(5)。

其中,W表示待求的對映矩陣,v為一個屬於[0 1]的權重值,它表示了不同的樣本對對映矩陣的影響程度,l()為一個hinge loss,具體形式如(6)所示。其中,S()表示不同模態資料經過對映函式對映之後的值,通過sigmoid函式之後進行cosine similarity,所得到的相似度值。x和z分別為不同模態的輸入樣本,相同的下標表示了xk和zk為最相似的樣本。“三角”為一個margin,它的存在使得相同下表的不同模態之間的相似度與其他非相同下標的不同模態之間的相似度存在margin大小的差距。

(5)中的第二項是對於v的約束項,用於選擇合適的權重向量,其具體形式為(7)。

2.3 基於演算法SMLFCD對演算法JSFFL進行小改進對於目標函式(5),作者將其分為兩個部分進行了分別的交叉迭代優化,即將公式(7)a從原式(5)中,分離出來,從而得到最終的結果。
上述提高的從簡單樣本到複雜樣本的學習過程,同樣可以應用到演算法JSFFL中,只需要根據原演算法中均方誤差的大小,為每個樣本分配一個相應的權重值,誤差越小,分配的權重值越大,這樣就可以實現上述思想與演算法JSFFL的結合。
3、實驗結果
3.1 實驗資料
來自於維基百科的資料集,有2173個訓練集和693個測試集,每個樣本有一張圖片和其對應的一個文字段落,總共有10個類別,樣本類別並不均勻。
3.2 實驗環境及工具
Windows8.1+4BG記憶體+intel i5處理器+matlab2016a。
3.3 結果及分析如表1所示,為實現演算法JFSSL的結果。

最終的評判標準使用的是MAP引數,該標準可以綜合評價結果的準去率與召回率,其值越大,表明結果越好,最大值為1。
其中,表1中的base line表示資料集按照3.1中所提到的方式進行劃分,演算法JFSSL在其上面的結果。實際上在作者的工作中,並沒有將資料集按照上述方法進行劃分,而是劃分了1300個訓練集和1566個測試集,且每一類的訓練集均為130個,這樣的做法使得訓練樣本的類別變得均衡,從而也提高了最終的效果。原文中作者的結果為0.3063(Image query)和0.2275(Text query),有表1的第二列可知,實驗結果與作者的結果基本一致。
如表2所示,表示的是演算法JFSSL的目標函式中各項的實際作用。
由結果可知,兩項約束均能夠使得結果變好,但是該資料集的樣本特徵維數較少(圖片(128)文字(10)),使得L2,1範數的應該對於結果的提升並沒有特別明顯。當去除第二項,保留第三項時,可以看到想過並沒有變好,甚至還變差了,這主要是因為當目標函式缺乏約束項時,最後一項的存在,使得對映矩陣的變化不收約束,從而使結果變差。
本文也實現了演算法SCCLR,該論文號稱是目前該問題上結果最好的論文,但是我一直對於該論文的理論存在質疑。質疑主要有兩個部分:
(1)文中沒有使用樣本的類別資訊,它將具有相同下標的樣本之間的cosine相似度與其他所有非相同下標的樣本之間的cosine相似度進行比較,也就相當於訓練“一對多”的分類器,最優化分類器,使得它們之間相差margin的大小。這樣做能夠一定程度上達到分類的效果,但是我不認為能夠達到非常出眾的結果。
(2)整篇論文的目標函式,理論上只能夠將樣本分開,但不能使得相同下標的樣本之間的cosine相似度變大,這樣一來,在測試集中,利用cosine相似度無法得到想要的結果。
最終的實驗結果也完全達不到一個滿意的效果,當然作者沒有提及引數的問題,也許將引數調整到合適的狀態可以一定程度上改善結果,但是,我對於該方法理論依舊無法理解。
我聯絡過論文的作者,第一次請教了“最終使用什麼方法衡量對映到子空間之後的資料的相似度”的問題,她很快進行了回答,但是當我請教了以上我所提到的疑惑時,發了好幾封郵件,都沒有得到回覆,也許是因為作者工作太忙的緣故。
雖然如此,本文還是將“從簡單學習到複雜學習”的思想遷移到了演算法JFSSL中,得到了如表3的結果。
 如表3所示,該改進的確對演算法的結果有所提升, 但在Text query方面似乎效果不大,這可能是因為text樣本的特徵數量較少,且樣本的數量太少的原因。
如表3所示,該改進的確對演算法的結果有所提升, 但在Text query方面似乎效果不大,這可能是因為text樣本的特徵數量較少,且樣本的數量太少的原因。對於這個改進方法,新增了兩個閾值,用於控制樣本更新權重的分配,但最優的閾值並不好取,因為原演算法中,利用了最小化的平方誤差的方法對樣本進行類別的劃分,在目標函式的設計中,對於同類樣本的劃分能力不強,使得同類樣本的均方誤差差異較小。同時,該改進思想其實存在一種trade-off(權衡):應用的訓練樣本數量大小的權衡。學習演算法需要足夠的訓練樣本進行訓練,當演算法中,太多的樣本的均方誤差大於閾值,則沒有足夠的樣本以供學習;當演算法中,應用的訓練樣本較大時,對學習結果產生不良影響的樣本也會越多。
近兩年在該問題上,並沒有突破性的工作,基本都是對於前面經典的方法進行改進,在資料集上的表現也沒有特別大的進步。單獨研究不同模態特徵之間的關係,可能很難取得突破,需要將樣本的特徵提取和子空間的生成,這兩部分關聯在一起,才有可能有更好的效果。這其實是一個比較自然的想法,但是至今也沒有非常突出的工作。我個人更加看好神經網路的方法,因為它將以上的兩步結合到了一起,但是目前在效果方面沒有明顯超越傳統方法。