
科普帖:深度學習中GPU和視訊記憶體分析
深度學習最吃機器,耗資源,在本文,我將來科普一下在深度學習中:
- 何為“資源”
- 不同操作都耗費什麼資源
- 如何充分的利用有限的資源
- 如何合理選擇顯示卡
並糾正幾個誤區:
- 視訊記憶體和GPU等價,使用GPU主要看視訊記憶體的使用?
- Batch Size 越大,程式越快,而且近似成正比?
- 視訊記憶體佔用越多,程式越快?
- 視訊記憶體佔用大小和batch size大小成正比?
0 預備知識
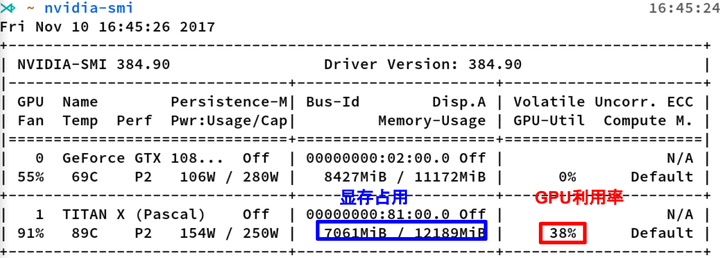
nvidia-smi是Nvidia顯示卡命令列管理套件,基於NVML庫,旨在管理和監控Nvidia
GPU裝置。
 nvidia-smi的輸出
nvidia-smi的輸出
這是nvidia-smi命令的輸出,其中最重要的兩個指標:
- 視訊記憶體佔用
- GPU利用率
視訊記憶體佔用和GPU利用率是兩個不一樣的東西,顯示卡是由GPU計算單元和視訊記憶體等組成的,視訊記憶體和GPU的關係有點類似於記憶體和CPU的關係。
這裡推薦一個好用的小工具:gpustat,直接pip
install gpustat即可安裝,gpustat基於nvidia-smi,可以提供更美觀簡潔的展示,結合watch命令,可以動態實時監控GPU的使用情況。
watch --color -n1 gpustat -cpu
 gpustat
輸出
gpustat
輸出
視訊記憶體可以看成是空間,類似於記憶體。
- 視訊記憶體用於存放模型,資料
- 視訊記憶體越大,所能執行的網路也就越大
GPU計算單元類似於CPU中的核,用來進行數值計算。衡量計算量的單位是flop: the number of floating-point multiplication-adds
1*2+3 1 flop
1*2 + 3*4 + 4*5 3 flop
1. 視訊記憶體分析
1.1 儲存指標
1Byte = 8 bit
1K = 1024 Byte
1M = 1024 K
1G = 1024 M
1T = 1024 G
10 K = 10*1024 Byte
除了K、M,G,T等之外,我們常用的還有KB 、MB,GB,TB 。二者有細微的差別。
1Byte = 8 bit
1KB = 1000 Byte
1 K、M,G,T是以1024為底,而KB 、MB,GB,TB以1000為底。不過一般來說,在估算視訊記憶體大小的時候,我們不需要嚴格的區分這二者。
在深度學習中會用到各種各樣的數值型別,數值型別命名規範一般為TypeNum,比如Int64、Float32、Double64。
- Type:有Int,Float,Double等
- Num: 一般是 8,16,32,64,128,表示該型別所佔據的位元數目
常用的數值型別如下圖所示:
常用的數值型別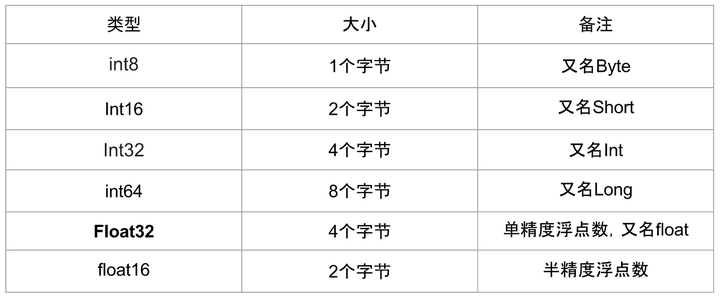 常用的數值型別
常用的數值型別
其中Float32 是在深度學習中最常用的數值型別,稱為單精度浮點數,每一個單精度浮點數佔用4Byte的視訊記憶體。
舉例來說:有一個1000x1000的 矩陣,float32,那麼佔用的視訊記憶體差不多就是
1000x1000x4 Byte = 4MB
32x3x256x256的四維陣列(BxCxHxW)佔用視訊記憶體為:24M
1.2 神經網路視訊記憶體佔用
神經網路模型佔用的視訊記憶體包括:
- 模型自身的引數
- 模型的輸出
舉例來說,對於如下圖所示的一個全連線網路(不考慮偏置項b)
模型的輸入輸出和引數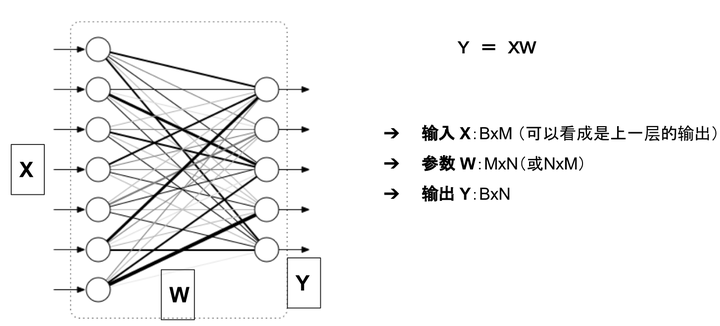 模型的輸入輸出和引數
模型的輸入輸出和引數
模型的視訊記憶體佔用包括:
- 引數:二維陣列 W
- 模型的輸出: 二維陣列 Y
輸入X可以看成是上一層的輸出,因此把它的視訊記憶體佔用歸於上一層。
這麼看來視訊記憶體佔用就是W和Y兩個陣列?
並非如此!!!
下面細細分析。
1.2.1 引數的視訊記憶體佔用
只有有引數的層,才會有視訊記憶體佔用。這部份的視訊記憶體佔用和輸入無關,模型載入完成之後就會佔用。
有引數的層主要包括:
- 卷積
- 全連線
- BatchNorm
- Embedding層
- ... ...
無引數的層:
- 多數的啟用層(Sigmoid/ReLU)
- 池化層
- Dropout
- ... ...
更具體的來說,模型的引數數目(這裡均不考慮偏置項b)為:
- Linear(M->N): 引數數目:M×N
- Conv2d(Cin, Cout, K): 引數數目:Cin × Cout × K × K
- BatchNorm(N): 引數數目: 2N
- Embedding(N,W): 引數數目: N × W
引數佔用視訊記憶體 = 引數數目×n
n = 4 :float32
n = 2 : float16
n = 8 : double64
在PyTorch中,當你執行完model=MyGreatModel().cuda()之後就會佔用相應的視訊記憶體,佔用的視訊記憶體大小基本與上述分析的視訊記憶體差不多(會稍大一些,因為其它開銷)。
1.2.2 梯度與動量的視訊記憶體佔用
舉例來說, 優化器如果是SGD:
可以看出來,除了儲存W之外還要儲存對應的梯度 ,因此視訊記憶體佔用等於引數佔用的視訊記憶體x2,
如果是帶Momentum-SGD
這時候還需要儲存動量, 因此視訊記憶體x3
如果是Adam優化器,動量佔用的視訊記憶體更多,視訊記憶體x4
總結一下,模型中與輸入無關的視訊記憶體佔用包括:
- 引數 W
- 梯度 dW(一般與引數一樣)
- 優化器的動量(普通SGD沒有動量,momentum-SGD動量與梯度一樣,Adam優化器動量的數量是梯度的兩倍)
1.2.3 輸入輸出的視訊記憶體佔用
這部份的視訊記憶體主要看輸出的feature map 的形狀。
feature map feature
map
feature
map
比如卷積的輸入輸出滿足以下關係:
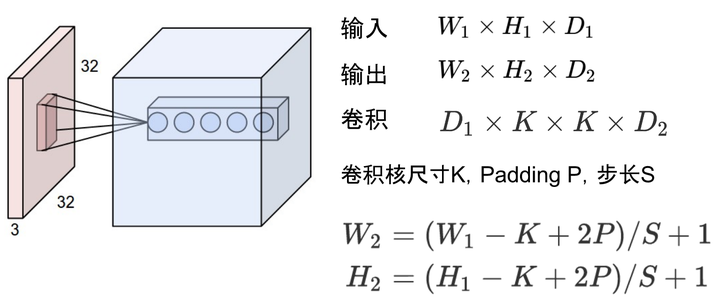
據此可以計算出每一層輸出的Tensor的形狀,然後就能計算出相應的視訊記憶體佔用。
模型輸出的視訊記憶體佔用,總結如下:
- 需要計算每一層的feature map的形狀(多維陣列的形狀)
- 模型輸出的視訊記憶體佔用與 batch size 成正比
- 需要儲存輸出對應的梯度用以反向傳播(鏈式法則)
- 模型輸出不需要儲存相應的動量資訊(因為不需要執行優化)
深度學習中神經網路的視訊記憶體佔用,我們可以得到如下公式:
視訊記憶體佔用 = 模型視訊記憶體佔用 + batch_size × 每個樣本的視訊記憶體佔用
可以看出視訊記憶體不是和batch-size簡單的成正比,尤其是模型自身比較複雜的情況下:比如全連線很大,Embedding層很大
另外需要注意:
- 輸入(資料,圖片)一般不需要計算梯度
- 神經網路的每一層輸入輸出都需要儲存下來,用來反向傳播,但是在某些特殊的情況下,我們可以不要儲存輸入。比如ReLU,在PyTorch中,使用
nn.ReLU(inplace = True)能將啟用函式ReLU的輸出直接覆蓋保存於模型的輸入之中,節省不少視訊記憶體。感興趣的讀者可以思考一下,這時候是如何反向傳播的(提示:y=relu(x) -> dx = dy.copy();dx[y<=0]=0)
1.3 節省視訊記憶體的方法
在深度學習中,一般佔用視訊記憶體最多的是卷積等層的輸出,模型引數佔用的視訊記憶體相對較少,而且不太好優化。
節省視訊記憶體一般有如下方法:
- 降低batch-size
- 下采樣(NCHW -> (1/4)*NCHW)
- 減少全連線層(一般只留最後一層分類用的全連線層)
2 計算量分析
計算量的定義,之前已經講過了,計算量越大,操作越費時,執行神經網路花費的時間越多。
2.1 常用操作的計算量
常用的操作計算量如下:
- 全連線層:BxMxN , B是batch size,M是輸入形狀,N是輸出形狀。
- 卷積的計算量:
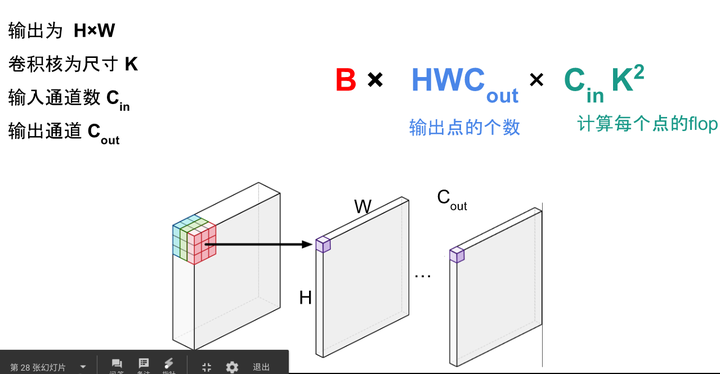 卷積的計算量分析
卷積的計算量分析
- BatchNorm 計算量我個人估算大概是 , 歡迎指正
- 池化的計算量:
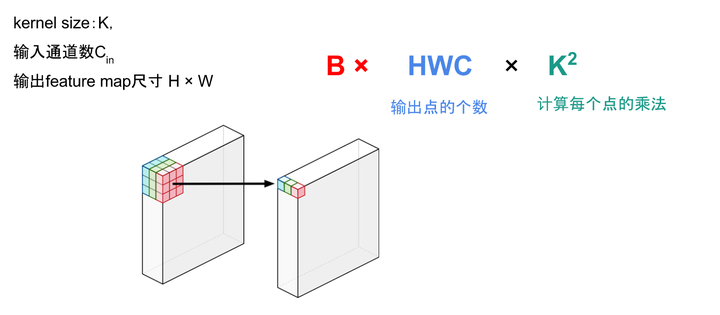
- ReLU的計算量: BHWC
2.2 AlexNet 分析
AlexNet的分析如下圖,左邊是每一層的引數數目(不是視訊記憶體佔用),右邊是消耗的計算資源
AlexNet分析 AlexNet分析
AlexNet分析
可以看出:
- 全連線層佔據了絕大多數的引數
- 卷積層的計算量最大
2.3 減少卷積層的計算量
今年穀歌提出的MobileNet,利用了一種被稱為DepthWise Convolution的技術,將神經網路執行速度提升許多,它的核心思想就是把一個卷積操作拆分成兩個相對簡單的操作的組合。如圖所示, 左邊是原始卷積操作,右邊是兩個特殊而又簡單的卷積操作的組合(上面類似於池化的操作,但是有權重,下面類似於全連線操作)。
Depthwise Convolution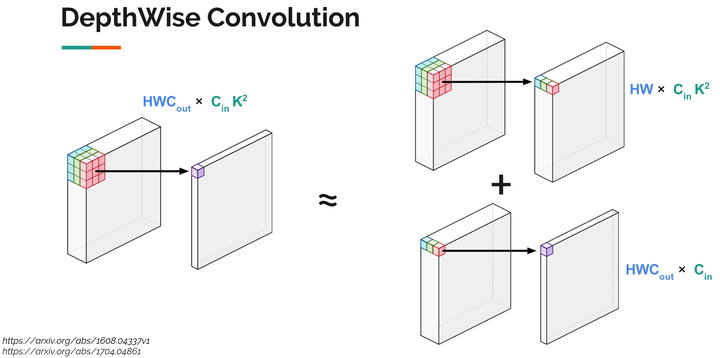 Depthwise
Convolution
Depthwise
Convolution
這種操作使得:
- 視訊記憶體佔用變多(每一步的輸出都要儲存)
- 計算量變少了許多,變成原來的( )(一般為原來的10-15%)
2.4 常用模型 視訊記憶體/計算複雜度/準確率
去年一篇論文()總結了當時常用模型的各項指標,橫座標是計算複雜度(越往右越慢,越耗時),縱座標是準確率(越高越好),圓的面積是引數數量(不是視訊記憶體佔用)。左上角我畫了一個紅色小圓,那是最理想的模型的的特點:快,效果好,佔用視訊記憶體小。
常見模型計算量/視訊記憶體/準確率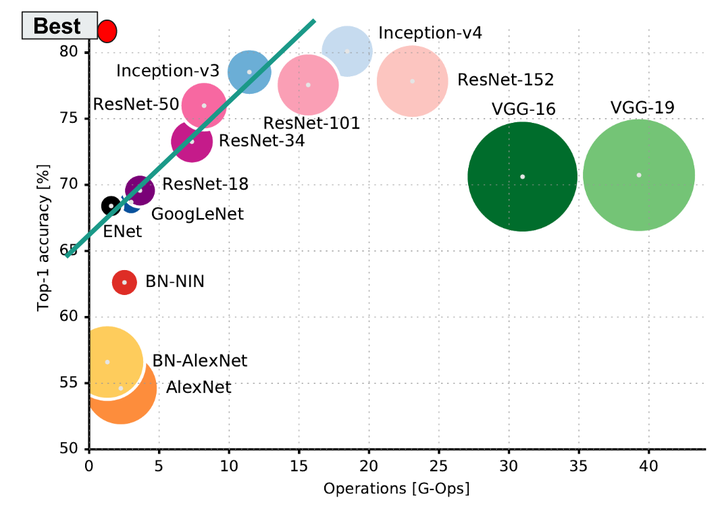 常見模型計算量/視訊記憶體/準確率
常見模型計算量/視訊記憶體/準確率
3 總結
3.1 建議
- 時間更寶貴,儘可能使模型變快(減少flop)
- 視訊記憶體佔用不是和batch size簡單成正比,模型自身的引數及其延伸出來的資料也要佔據視訊記憶體
- batch size越大,速度未必越快。在你充分利用計算資源的時候,加大batch size在速度上的提升很有限
尤其是batch-size,假定GPU處理單元已經充分利用的情況下:
- 增大batch size能增大速度,但是很有限(主要是平行計算的優化)
- 增大batch size能減緩梯度震盪,需要更少的迭代優化次數,收斂的更快,但是每次迭代耗時更長。
- 增大batch size使得一個epoch所能進行的優化次數變少,收斂可能變慢,從而需要更多時間才能收斂(比如batch_size 變成全部樣本數目)。
3.2 關於顯示卡選購
當前市面上常用的顯示卡指標如下:
常見顯示卡指標 常見顯示卡指標
常見顯示卡指標
顯然GTX 1080TI價效比最高,速度超越新Titan X,價格卻便宜很多,視訊記憶體也只少了1個G(據說故意閹割掉一個G,不然全面超越了Titan X怕激起買Titan X人的民憤~)。
- K80價效比很低(速度慢,而且賊貴)
- 注意GTX TITAN和Nvidia TITAN的區別,別被騙
另外,針對本文,我做了一個Google 幻燈片:神經網路效能分析,國內使用者可以點此下載ppt。Google幻燈片格式更好,後者格式可能不太正常。
本文都是針對單機單卡的分析,分散式的情況會和這個有所區別。在分析計算量的時候,只分析了前向傳播,反向傳播計算量一般會與前向傳播有細微的差別。
限於本人水平,文中有疏漏之處,還請指正。