
目標檢測之Loss:Center Loss梯度更新
轉載:https://blog.csdn.net/u014380165/article/details/76946339
最近幾年網路效果的提升除了改變網路結構外,還有一群人在研究損失層的改進,這篇博文要介紹的就是較為新穎的center loss。center loss來自ECCV2016的一篇論文:A Discriminative Feature Learning Approach for Deep Face Recognition。
論文連結:http://ydwen.github.io/papers/WenECCV16.pdf程式碼連結:https://github.com/ydwen/caffe-face
對於常見的影象分類問題,我們常常用softmax loss來求損失,關於softmax loss你可以參考這篇博文:
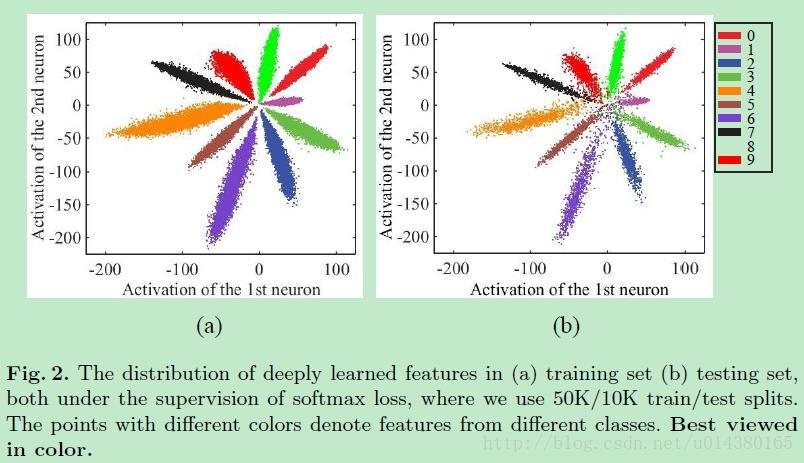
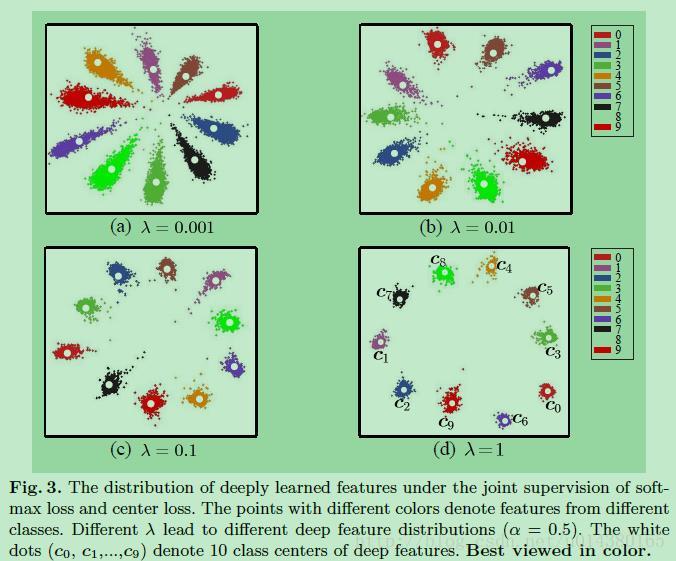
如果你是採用softmax loss加上本文提出的center loss的損失,那麼最後各個類別的特徵分佈大概如下圖Fig3。和Fig2相比,類間距離變大了,類內距離減少了(主要變化在於類內距離:intra-class),這就是直觀的結果。
接下來詳細介紹center loss。如果你還是不熟悉傳統的softmax loss,那麼先來看看傳統的softmax loss。首先區分softmax和softmax loss的區別,可以看部落格:
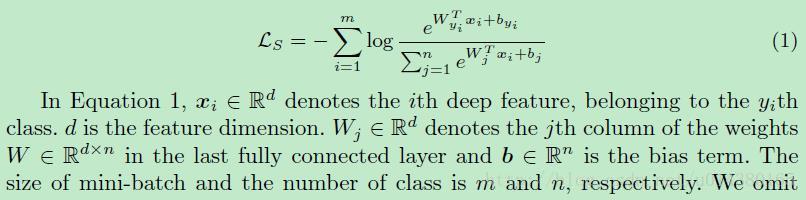
那麼center loss到底是什麼呢?先看看center loss的公式LC。cyi表示第yi個類別的特徵中心,xi表示全連線層之前的特徵。後面會講到實際使用的時候,m表示mini-batch的大小。因此這個公式就是希望一個batch中的每個樣本的feature離feature 的中心的距離的平方和要越小越好,也就是類內距離要越小越好。這就是center loss。
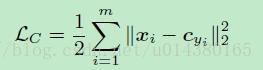
關於LC的梯度和cyi的更新公式如下:
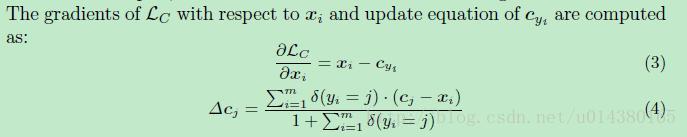
這個公式裡面有個條件表示式如下式,這裡當condition滿足的時候,下面這個式子等於1,當不滿足的時候,下面這個式子等於0.
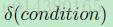
因此上面關於cyi的更新的公式中,當yi(表示yi類別)和cj的類別j不一樣的時候,cj是不需要更新的,只有當yi和j一樣才需要更新。
作者文中用的損失L的包含softmax loss和center loss,用引數南木達(打不出這個特殊字元)控制二者的比重,如下式所示。這裡的m表示mini-batch的包含的樣本數量,n表示類別數。
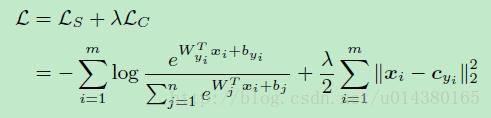
梯度求導過程,相當與在softmaxLoss後面加了2*(X - C)的約束因子
具體的演算法描述可以看下面的Algorithm1:
