
Hadoop多節點叢集的構建
1、叢集部署介紹
1.1 Hadoop簡介
Hadoop是Apache軟體基金會旗下的一個開源分散式計算平臺。以Hadoop分散式檔案系統HDFS(Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的開源實現)為核心的Hadoop為使用者提供了系統底層細節透明的分散式基礎架構。
對於Hadoop的叢集來講,可以分成兩大類角色:Master和Salve。一個HDFS叢集是由一個NameNode和若干個DataNode組成的。其中NameNode作為主伺服器,管理檔案系統的名稱空間和客戶端對檔案系統的訪問操作;叢集中的DataNode
從上面的介紹可以看出,HDFS和MapReduce共同組成了Hadoop分散式系統體系結構的核心。HDFS在叢集上實現分散式檔案系統,MapReduce
1.2環境說明
Hadoop叢集中包括3個節點:1個Master,2個Salve,節點之間區域網連線,可以相互ping通,節點IP地址分佈如下:
| IP | Hostname |
| 10.139.8.39 | master |
| 10.139.8.40 | slave1 |
| 10.139.8.41 | slave2 |
Master機器主要配置NameNode和JobTracker
在這裡,2個NameNode的資料其實是實時共享的。新HDFS採用了一種共享機制,JournalNode叢集或者NFS進行共享。NFS是作業系統層面的,JournalNode是hadoop層面的,我們這裡使用JournalNode叢集進行資料共享。
這就需要使用ZooKeeper叢集進行選擇了。HDFS叢集中的兩個NameNode都在ZooKeeper中註冊,當active狀態的NameNode出故障時,ZooKeeper能檢測到這種情況,它就會自動把standby狀態的NameNode切換為active狀態。
1.3環境配置
(1)修改當前機器名稱
假定我們發現我們的機器的主機名不是我們想要的。
1)在CentOS下修改機器名稱
修改檔案/etc/sysconfig/network裡的值即可,修改成功後用hostname命令檢視當前主機名是否設定成功。
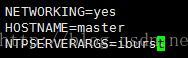
(2)配置hosts檔案
"/etc/hosts"這個檔案是用來配置主機將用的DNS伺服器資訊,是記載LAN內接續的各主機的對應[HostNameIP]用的。當用戶在進行網路連線時,首先查詢該檔案,尋找對應主機名對應的IP地址。

儲存修改後,重啟系統。
2.2 配置Master無密碼登入所有Salve
1)SSH無密碼原理
Master(NameNode | JobTracker)作為客戶端,要實現無密碼公鑰認證,連線到伺服器Salve(DataNode | Tasktracker)上時,需要在Master上生成一個金鑰對,包括一個公鑰和一個私鑰,而後將公鑰複製到所有的Slave上。當Master通過SSH連線Salve時,Salve就會生成一個隨機數並用Master的公鑰對隨機數進行加密,併發送給Master。Master收到加密數之後再用私鑰解密,並將解密數回傳給Slave,Slave確認解密數無誤之後就允許Master進行連線了。這就是一個公鑰認證過程,其間不需要使用者手工輸入密碼。
2)Master機器上設定無密碼登入
a. Master節點利用ssh-keygen命令生成一個無密碼金鑰對。
在Master節點上執行以下命令:
ssh-keygen –t rsa
執行後詢問其儲存路徑時直接回車採用預設路徑。生成的金鑰對:id_rsa(私鑰)和id_rsa.pub(公鑰),預設儲存在"/home/使用者名稱/.ssh"目錄下。檢視"/home/使用者名稱/"下是否有".ssh"資料夾,且".ssh"檔案下是否有兩個剛生產的無密碼金鑰對。

b. 接著在Master節點上做如下配置,把id_rsa.pub追加到授權的key裡面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
檢視下authorized_keys的許可權,如果許可權不對則利用如下命令設定該檔案的許可權:
chmod 600 authorized_keys
c. 用root使用者登入修改SSH配置檔案"/etc/ssh/sshd_config"的下列內容。
檢查下面幾行前面”#”註釋是否取消掉:
RSAAuthentication yes # 啟用 RSA 認證
PubkeyAuthentication yes # 啟用公鑰私鑰配對認證方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公鑰檔案路徑
設定完之後記得重啟SSH服務,才能使剛才設定有效。下面就是重複上面的步驟把剩餘的兩臺(Slave1和Slave2)Slave伺服器進行配置。這樣,我們就完成了"配置Master無密碼登入所有的Slave伺服器"。
接下來配置所有Slave無密碼登入Master,其和Master無密碼登入所有Slave原理一樣,就是把Slave的公鑰追加到Master的".ssh"資料夾下的"authorized_keys"中,記得是追加(>>)
3、Java環境安裝
所有的機器上都要安裝JDK,現在就先在Master伺服器安裝,然後其他伺服器按照步驟重複進行即可。安裝JDK以及配置環境變數,需要以"root"的身份進行。
3.1 安裝JDK
首先用root身份登入"Master.Hadoop"後在"/usr"下建立"java"資料夾,再將"jdk-8u91-linux-x64.tar.gz"複製到"/usr/java"資料夾中,然後解壓即可。檢視"/usr/java"下面會發現多了一個名為"jdk1.8.0_91"資料夾,說明我們的JDK安裝結束,進入下一個"配置環境變數"環節。
3.2 配置環境變數
(1)編輯"/etc/profile"檔案
編輯"/etc/profile"檔案,在後面新增Java的"JAVA_HOME"、"CLASSPATH"以及"PATH"內容如下:

(2)使配置生效
儲存並退出,執行下面命令使其配置立即生效。
source /etc/profile
3.3 驗證安裝成功
配置完畢並生效後,用下面命令判斷是否成功。
java -version

從上圖中得知,我們確定JDK已經安裝成功。
3.4 安裝剩餘機器
這時用普通使用者hadoop通過scp命令格式把"/usr/java/"檔案複製到其他Slave上面,剩下的事兒就是在其餘的Slave伺服器上按照上圖的步驟配置環境變數和測試是否安裝成功,這裡以Slave1.Master為例:
scp -r /usr/java [email protected]:/usr/
4、Hadoop叢集安裝
所有的機器上都要安裝hadoop,現在就先在Master伺服器安裝,然後其他伺服器按照步驟重複進行即可。安裝和配置hadoop需要以"root"的身份進行。
4.1 安裝hadoop
所有的機器上都要安裝hadoop,現在就先在Master伺服器安裝,然後其他伺服器按照步驟重複進行即可。安裝和配置hadoop需要以"root"的身份進行。
4.1 安裝hadoop
首先用root使用者登入"Master"機器,將下載的"hadoop-2.6.4.tar.gz"複製到/usr目錄下。然後進入"/usr"目錄下,用下面命令把"hadoop-2.6.4.tar.gz"進行解壓,並將其重新命名為"hadoop",把該資料夾的讀許可權分配給普通使用者hadoop,然後刪除"hadoop-1.0.0.tar.gz"安裝包。
cd /usr
tar –xzvf hadoop-2.6.4.tar.gz
mv hadoop-2.6.4 hadoop
chown –R hadoop:hadoop hadoop #將資料夾"hadoop"讀許可權分配給hadoop普通使用者
rm -rf hadoop-2.6.4.tar.gz
把Hadoop的安裝路徑新增到"/etc/profile"中,修改"/etc/profile"檔案,將以下語句新增到末尾,並使其生效(. /etc/profile):
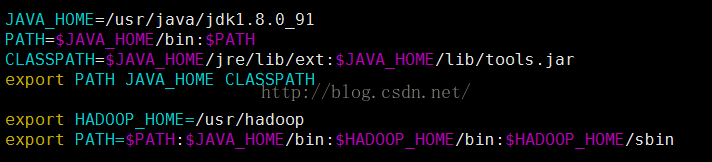
4.2 配置hadoop
本文部署的hadoop2.4中NameNode節點不再是隻有一個,可以有多個(目前只支援2個)。每一個都有相同的職能。
一個是active狀態的,一個是standby狀態的。當叢集執行時,只有active狀態的NameNode是正常工作的,standby狀態的NameNode是處於待命狀態的,時刻同步active狀態NameNode的資料。一旦active狀態的NameNode不能工作,通過手工或者自動切換,standby狀態的NameNode就可以轉變為active狀態的,就可以繼續工作了。這就是高可靠(HA)。
在這裡,2個NameNode的資料其實是實時共享的。新HDFS採用了一種共享機制,JournalNode叢集或者NFS進行共享。NFS是作業系統層面的,JournalNode是hadoop層面的,我們這裡使用JournalNode叢集進行資料共享。
這就需要使用ZooKeeper叢集進行選擇了。HDFS叢集中的兩個NameNode都在ZooKeeper中註冊,當active狀態的NameNode出故障時,ZooKeeper能檢測到這種情況,它就會自動把standby狀態的NameNode切換為active狀態。
(1)配置hadoop-env.sh
該"hadoop-env.sh"檔案位於"/usr/hadoop/etc/hadoop"目錄下。
在檔案中修改下面內容:

(2)安裝配置zookeeper
下載最新的zooper軟體:http://www.apache.org/dyn/closer.cgi/zookeeper/,並將下載後的zookeeper-3.4.8.tar.gz解壓到/usr/hadoop/app下,把zookeeper的安裝路徑新增到"/etc/profile"中,修改"/etc/profile"檔案,將以下語句新增到末尾,並使其生效(. /etc/profile):

在/usr/hadoop/app/zookeeper/conf下新建zoo.cfg配置檔案,並配置下述內容:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/hadoop/app/zookeeper/zkdata
datalogDir=/usr/hadoop/app/zookeeper/zkdatalog
# the port at which the clients will connect
clientPort=2181
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1(3)配置core-site.xml檔案
修改Hadoop核心配置檔案core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>(4)配置hdfs-site.xml檔案
修改Hadoop中HDFS的配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:50070</value>
</property>
<!-- nn2的RPC通訊地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave1:9000</value>
</property>
<!-- nn2的http通訊地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/hadoop/tmp/journal</value>
</property>
<!--指定支援高可用自動切換機制-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns</value>
</property>
<!--
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>(5)配置mapred-site.xml檔案
修改Hadoop中MapReduce的配置檔案
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
</property>
</configuration>(6)配置yarn-site.xml檔案
修改Hadoop中yarn的配置檔案
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value></property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>(7)配置slaves檔案(Master主機特有)
slave1
slave2現在在Master機器上的Hadoop配置就結束了,剩下的就是配置Slave機器上的Hadoop。
最簡單的方法是將 Master上配置好的hadoop所在資料夾"/usr/hadoop"複製到所有的Slave的"/usr"目錄下(實際上Slave機器上的slavers檔案是不必要的, 複製了也沒問題)。用下面命令格式進行。
scp -r /usr/hadoop root@slave1:/usr/
scp -r /usr/hadoop root@slave2:/usr/
三、啟動過程
1、啟動Zookeeper叢集
分別在master、slave1、slave2上執行
zkServer.sh start然後執行:
zkServer.sh status三個節點都啟動後,執行
zkCli.sh然後執行
ls /2、格式化Zookeeper叢集,目的是在Zookeeper叢集上建立HA的相應節點
在master上執行,注意,最好手動敲入命令。
hdfs zkfc –formatZKzkCli.shls /
則表示格式化成功

ls /hadoop-ha會出現我們配置的HA叢集名稱
3、啟動Journal叢集
分別在master,slave1,slave2上執行
hadoop-daemon.sh start journalnode4、格式化叢集上的一個NameNode
在master上執行:
hdfs namenode -format5、啟動叢集中步驟4中的NameNode
啟動master上的NameNode
hadoop-daemon.sh start namenode6、把NameNode的資料同步到另一個NameNode上
把NameNode的資料同步到slave1上,在slave1上執行:
hdfs namenode –bootstrapStandby7、啟動另個一NameNode
在slave1上執行
hadoop-daemon.sh start namenode8、啟動所有的DataNode
hadoop-daemons.sh start datanode9、啟動Yarn
start-yarn.sh分別在master與slave1上執行
hadoop-daemon.sh start zkfc
至此配置結束。
相關推薦
Hadoop多節點叢集的構建
1、叢集部署介紹 1.1 Hadoop簡介 Hadoop是Apache軟體基金會旗下的一個開源分散式計算平臺。以Hadoop分散式檔案系統HDFS(Hadoop Distributed Filesystem)和MapReduce(Google MapRedu
一步步教你Hadoop多節點叢集安裝配置
1、叢集部署介紹 1.1 Hadoop簡介 Hadoop是Apache軟體基金會旗下的一個開源分散式計算平臺。以Hadoop分散式檔案系統HDFS(Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的開源實現)為核心的Hadoop為使用者提
centos7+hadoop 2.8 的多節點叢集搭建
1、叢集IP 192.168.2.218 hadoop-slave-1 192.168.2.4 hadoop-master 2、java 選用自帶的java 1.7.0. openjdk 關於java版本和hadoop版本的搭配可以參考hadoop官方wiki htt
Hyperledger Fabric v1.1 單機多節點叢集環境搭建
Fabric v1.1 1.環境安裝 1).安裝go 1.9.x 下載地址 http://golang.org/dl/ 配置環境 #go的安裝根目錄 export GOROOT=/usr/local/go #go的工作路徑根目錄 export GOPAT
Hyperledger Fabric-v1.1多節點叢集
Fabric v1.1 1.環境安裝 1).安裝go 1.9.x 下載地址 http://golang.org/dl/ 配置環境 #go的安裝根目錄 export GOROOT=/usr/local/go #go的工作路徑根目錄 export GOPAT
Spark學習筆記(二) 安裝Hadoop單節點叢集
安裝Hadoop單節點叢集 1. 下載並解壓Hadoop 1.1 下載Hadoop 1.2 解壓Hadoop包 1.3 將解壓的資料夾重新命名為Hadoop,然後拷貝到/usr/local下 2. 設定Hadoop環境變數
基於docker-compose部署tendermint多節點叢集
一.我們可以通過 docker-compose 來啟動多個 container 通過官方文件我們知道啟動 tendermint 叢集需要下面幾個步驟: 每個 node 都需要通過 tendermint init 來進行初始化; 需要有一個包含所有 validator 節點
K8S+openstack swift 多節點叢集部署
目的:通過k8s可以快速建立啟動swift叢集 思路:剛開始想全自動的,後來實現有點困難,主要對k8s不是很熟,所以先半自動了。。。先建立swift proxy的映象,再在worker節點中隨便找一臺製作swift 儲存的映象。swift物件儲存的多節點叢集模式暫時採用temau
k8s, etcd 多節點叢集部署問題排查記錄
目錄 文章目錄 目錄 部署環境 1. etcd 叢集啟動失敗 解決 2. etcd 健康狀態檢查失敗 解決 3. kube-apiserver 啟動失敗 解決
hadoop 三節點叢集安裝配置詳細例項
2012-05-23 作者:周海漢 網址:http://abloz.com 日期:2012.5.23 topo節點: 192.168.10.46 Hadoop46 192.168.10.47 Hadoop47 192.168.
Geode多節點叢集實驗
db $ reboot nn gfsh>list members Name | Id -------- | --------------------------------------------------- server3 | 192.168.79.139(ser
centos7 hadoop 3節點叢集安裝筆記
安裝 hadoop 賦予hadoop使用者sudo許可權: 1. 切換到root使用者,給hadoop使用者授予sudo許可權:修改/etc/sudoers檔案,由於預設root使用者也不可以寫
Redis單機多節點叢集實驗
第一步:安裝Redis 前面已經安裝過了 不解釋, Reids安裝包裡有個叢集工具,要複製到/usr/local/bin裡去 cp redis-3.2.9/src/redis-trib.rb /usr/local/bin 第二步:修改配置,建立節點 我們現在要搞六個節點,三主三從, 埠規定分別是7001,
centos7 Redis單機多節點叢集部署
1.Reids安裝包裡有個叢集工具,要複製到/usr/local/bin裡去 [[email protected] ~]# ll [[email protected] ~]# cd redis-3.2.9/src [[email p
redis單機多節點叢集搭建
注意: 在叢集過程前一定要把字尾為aof,rdb的redis資料儲存檔案刪除(或者備份到其他資料夾,只要不是/root/下就可以),否則會叢集失敗。第一步:安裝Redis(redis安裝)Reids安裝包裡有個叢集工具,要複製到/usr/local/bin裡去c
Hyperledger Fabric 1.0 從零開始(八)——Fabric多節點叢集生產部署
6.1、平臺特定使用的二進位制檔案配置 該方案與Hyperledger Fabric 1.0 從零開始(五)——執行測試e2e類似,根據企業需要,可以控制各節點的域名,及聯盟鏈的統一域名。可以指定單獨節點的訪問,生成指定的公私鑰、證書等檔案。具體的引數配置可以參考generateArtifacts.sh檔案,
Hadoop2.6完全分散式多節點叢集安裝配置
<name>fs.defaultFS</name> <value>hdfs://Master.Hadoop:9000</value> </property> <property> <name>io.fil
乾貨 | 超級賬本Fabric 1.0 多節點叢集的部署(1)
題圖攝於廣州:獵德橋珠江畔超級賬本 Fabric 1.0即將揭開面紗,社群使用者對此充滿期待。為
elasticsearch6.0.1單機多節點叢集搭建
環境準備 1、準備兩臺伺服器:10.47.227.13 10.47.227.14(預設已安裝java環境) 2、es6.0.1安裝包下載 (下載地址:https://www.elastic.co/cn/downloads/past-releases/elasticse
Flume-ng 多節點叢集搭建
Flume NG是一個分散式、可靠、可用的系統,它能夠將不同資料來源的海量日誌資料進行高效收集、聚合,最後儲存到一箇中心化資料儲存系統中,方便進行資料分析。事實上flume也可以收集其他資訊,不僅限於日誌。由原來的Flume OG到現在的Flume NG,進行了