
分散式資料處理框架:Apache Beam
1簡介
大資料時代中,資料從簡單的批處理,擴充套件到實時處理、流處理。起初的MapReduce處理模式早已獨木難支。此外,大資料處理技術也是百花齊放,如 HBase、Hive、Kafka、Spark、Flink 等,對開發者而言,想要將其全部熟練運用幾乎是一項不可能完成的任務。此時,Google在2016年2月宣佈將大資料流水線產品(Google DataFlow)貢獻給 Apache 基金會孵化,2017年1月Apache 對外宣佈開源 Apache Beam,2017年5月迎來了它的第一個穩定版本2.0.0。
Apache Beam的主要目標是統一批處理和流處理的程式設計正規化,為亂序無限的大資料集處理提供簡單靈活,功能豐富以及表達能力強大的SDK,但Apache Beam不涉及具體執行引擎的實現,Apache Beam希望基於Beam開發的資料處理程式可以執行在任意的分散式計算引擎上。
2Apache Beam架構
2.1基礎架構
Apache Beam將資料處理分成三層Beam Model、Pipeline和Beam Runners組成。如下圖2-1所示,Model是Beam 的模型或叫資料來源的IO,它是由多種資料來源或倉庫的IO組成,資料來源支援批處理和流處理。Pipeline是Beam的管道,所有的批處理或流處理都要通過這個管道把資料傳輸到後端的計算平臺。這個管道現在是唯一的。資料來源可以切換多種,計算平臺或處理平臺也支援多種。需要注意的是,管道只有一條,它的作用是連線資料和 Runners平臺(計算引擎)。Runners是大資料計算或處理平臺,目前支援Apache Flink、Apache Spark、Direct Pipeline 和 Google Clound Dataflow 四種。其中 Apache Flink 和 Apache Spark 同時支援本地和雲端。Direct Pipeline 僅支援本地,Google Clound Dataflow 僅支援雲端。後續還將接入更多大資料計算平臺。

圖2-1 資料處理架構圖
2.2Beam Model
Beam Model便是Beam的程式設計正規化,即Beam SDK的靈魂。首先,瞭解下Beam Model相關問題域的一些基本概念。
l 資料來源
分散式資料處理的資料來源型別通常有兩類,有界的資料集和無界的資料流。有界的資料集,比如一個HDFS中的檔案,一個Hive表等,資料特點是已持久化、大小固定、不常變動。而無界的資料流,比如Kafka流出來的資料流,其特點是動態、無邊界、無法全部持久化。Beam框架設計時便需兼顧這兩種資料來源資料處理進行考慮,即批處理和流處理。
l 時間
分散式框架的時間處理有兩種,一種是全量計算,另一種是部分增量計算。批處理任務通常進行全量的資料計算,較少關注資料的時間屬性,但是對於流處理任務來說,由於資料流是無情無盡的,無法進行全量的計算,通常是對某個視窗中得資料進行計算,對於大部分的流處理任務來說,按照時間進行視窗劃分,可能是最常見的需求。
l 亂序
對於流處理的資料流來說,資料的到達順序可能並不嚴格按照Event-Time的時間順序。若是按照 Process Time 定義時間視窗,便不存在亂序問題,因為都是關閉當前視窗後才進行下一個視窗操作,需要等待,所以執行都是有序的。而對於Event Time定義的時間視窗,則可能存在時間靠前的訊息在時間靠後的訊息後到達的情況,這在分散式的資料來源中可能非常常見的棘手問題。
Beam Model 處理的目標資料是無界的時間亂序資料流,不考慮時間順序或有界的資料集可看做是無界亂序資料流的一個特例。Beam Model 從下面四個維度歸納了使用者在進行資料處理的時候需要考慮的問題:
- What。如何對資料進行計算?例如,機器學習中訓練學習模型可以用 Sum或者Join 等。在Beam SDK中由Pipeline中的操作符指定。
- Where。資料在什麼範圍中計算?例如,基於Process-Time 的時間視窗、基於Event-Time的時間視窗、滑動視窗等等。在Beam SDK中由Pipeline 的視窗指定。
- When。何時輸出計算結果?例如,在1小時的Event-Time時間視窗中,每隔1分鐘將當前視窗計算結果輸出。在Beam SDK中由Pipeline的Watermark和觸發器指定。
- How。遲到資料如何處理?例如,將遲到資料計算增量結果輸出,或是將遲到資料計算結果和視窗內資料計算結果合併成全量結果輸出。在Beam SDK中由Accumulation指定。
Beam Model將“WWWH”四個維度抽象出來組成了Beam SDK,使用者在基於Beam SDK構建資料處理業務邏輯時,每一步只需要根據業務需求按照這四個維度呼叫具體的API,即可生成分散式資料處理Pipeline,並提交到具體的Runners執行引擎上執行。Apache Beam目前支援的API介面是由Java與Python語言實現的,其他語言版本的API正在開發之中。下表2-1是目前Beam 2.0的SDKs支援資料來源IO 。
|
資料來源IO |
描述 |
|
Amqp |
高階訊息佇列協議 |
|
Cassandra |
Cassandra是一個NoSQL列族(column family)實現,使用由Amazon Dynamo引入的架構方面的特性來支援Big Table資料模型。 |
|
Elasticesarch |
一個實時的分散式搜尋引擎 |
|
Google-cloud-platform |
谷歌雲 IO |
|
Hadoop-file-system |
操作 Hadoop 檔案系統的 IO |
|
Hadoop-hbase |
操作 Hadoop 上的 Hbase 的介面 IO |
|
Hcatalog |
Hcatalog 是 Apache 開源的對於表和底層資料管理統一服務平臺 |
|
Jdbc |
連線各種資料庫的資料庫聯結器 |
|
Jms |
Java 訊息服務(Java Message Service,簡稱 JMS)是用於訪問企業訊息系統的開發商中立的 API。企業訊息系統可以協助應用軟體通過網路進行訊息互動。JMS 在其中扮演的角色與 JDBC 很相似,正如 JDBC 提供了一套用於訪問各種不同關係資料庫的公共 API,JMS 也提供了獨立於特定廠商的企業訊息系統訪問方式 |
|
Kafka |
處理流資料的輕量級大資料訊息系統,或叫訊息匯流排 |
|
Kinesis |
對接亞馬遜的服務,可以構建用於處理或分析流資料的自定義應用程式,以滿足特定需求 |
|
Mongodb |
MongoDB 是一個基於分散式檔案儲存的資料庫 |
|
Mqtt |
IBM 開發的一個即時通訊協議 |
|
Solr |
亞實時的分散式搜尋引擎技術 |
|
xml |
一種資料格式 |
表2-1 Beam 2.0的SDKs支援資料來源IO
3簡單實戰演習
3.1 環境
A. 下載安裝JDK 7或更新的版本。
B. 下載maven並配置。
C. 開發環境 Eclipse(個人習慣)。
3.2 Join操作示例
3.2.1Join案例
將使用者資訊(使用者賬戶+使用者名稱)文字資料,與訂單資訊(使用者賬戶+訂單名+訂單詳情)文字資料,通過使用者賬戶欄位取並集操作。
3.2.2 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>william-lib</groupId>
<artifactId>wordcount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>wordcount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.15</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-jdbc</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>UTF8</encoding>
<fork>fasle</fork>
<meminitial>1024m</meminitial>
<maxmem>2024m</maxmem>
</configuration>
</plugin>
<!-- The configuration of maven-jar-plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<!-- The configuration of the plugin -->
<configuration>
<!-- Configuration of the archiver -->
<archive>
<!-- 生成的jar中,不要包含pom.xml和pom.properties這兩個檔案 -->
<addMavenDescriptor>false</addMavenDescriptor>
<!-- Manifest specific configuration -->
<manifest>
<!-- 是否要把第三方jar放到manifest的classpath中 -->
<addClasspath>true</addClasspath>
<!-- 生成的manifest中classpath的字首,因為要把第三方jar放到lib目錄下,所以classpath的字首是lib/ -->
<classpathPrefix>./</classpathPrefix>
<!-- 應用的main class -->
<mainClass>william_lib.wordcount</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
3.2.3TestJoin.java
package william_lib.wordcount;
import org.apache.beam.runners.direct.DirectRunner;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.SimpleFunction;
import org.apache.beam.sdk.transforms.join.CoGbkResult;
import org.apache.beam.sdk.transforms.join.CoGroupByKey;
import org.apache.beam.sdk.transforms.join.KeyedPCollectionTuple;
import org.apache.beam.sdk.values.KV;
import org.apache.beam.sdk.values.PCollection;
import org.apache.beam.sdk.values.TupleTag;
/**
*
* <pre>
* 2個本地資料集,以指定欄位做join操作
* </pre>
*
* @author William_JM
* @date 2017年12月13日
*
*/
public class TestJoin {
@SuppressWarnings("serial")
public static void main(String[] args) {
// 管道工廠建立需求管道
PipelineOptions options = PipelineOptionsFactory.create();
// 顯式指定PipelineRunner:DirectRunner(Local模式)
options.setRunner(DirectRunner.class);
// 裝置管道
Pipeline pipeline = Pipeline.create(options);
// 讀取使用者資訊資料集
final PCollection<KV<String, String>> userInfoCollection =
pipeline.apply(TextIO.read().from(args[0])).apply("userInfoCollection",
MapElements.via(new SimpleFunction<String, KV<String, String>>() {
@Override
public KV<String, String> apply(String input) {
// line format example:account|username
String[] values = input.split("\\|");
return KV.of(values[0], values[1]);
}
}));
// 業務訂單資料集
final PCollection<KV<String, String>> orderCollection =
pipeline.apply(TextIO.read().from(args[1])).apply("orderCollection",
MapElements.via(new SimpleFunction<String, KV<String, String>>() {
@Override
public KV<String, String> apply(String input) {
// line format example: orderId|orderName|description
String[] values = input.split("\\|");
return KV.of(values[0], values[1]);
}
}));
final TupleTag<String> userInfoTag = new TupleTag<String>();
final TupleTag<String> orderTag = new TupleTag<String>();
// 通過 beam提供CoGroupByKey實現對2組關係資料集(key/value)的join操作
// beam SDK為確保資料型別一致,強制資料集壓入KeyedPCollectionTuple
final PCollection<KV<String, CoGbkResult>> cogrouppedCollection =
KeyedPCollectionTuple.of(userInfoTag, userInfoCollection).and(orderTag, orderCollection)
.apply(CoGroupByKey.<String>create());
final PCollection<KV<String, String>> finalResultCollection = cogrouppedCollection.apply(
"finalResultCollection", ParDo.of(new DoFn<KV<String, CoGbkResult>, KV<String, String>>() {
@ProcessElement
public void processElement(ProcessContext pc) {
KV<String, CoGbkResult> e = pc.element();
String account = e.getKey();
String username = e.getValue().getOnly(userInfoTag);
for (String order : pc.element().getValue().getAll(orderTag)) {
pc.output(KV.of(account, username + "\t" + order));
}
}
}));
// 結果儲存資料集
PCollection<String> formattedResults = finalResultCollection.apply("formattedResults",
ParDo.of(new DoFn<KV<String, String>, String>() {
@ProcessElement
public void processElement(ProcessContext c) {
c.output(c.element().getKey() + " : " + c.element().getValue());
}
}));
formattedResults.apply(TextIO.write().to("joinedResults"));
pipeline.run().waitUntilFinish();
}
}
如上是將使用者資訊資料集與訂單資訊資料集做join操作實戰單碼。
1、 管道工廠生產定製屬性管道(Pipeline)——指定資料處理Runner為本地模式。
PipelineOptions options = PipelineOptionsFactory.create();
options.setRunner(DirectRunner.class);
2、 組裝資料引流管道
Pipeline pipeline = Pipeline.create(options);
3、 注入使用者資料集——這是beam最重要的Model模組,就是指定資料的來源,及資料的結構。本例是有界固定大小的文字檔案。
final PCollection<KV<String, String>> userInfoCollection= pipeline.apply
(TextIO.read().from(args[0])).apply("userInfoCollection",MapElements.via(newSimpleFunction<String, KV<String, String>>(){…...}));
final PCollection<KV<String, String>>orderCollection = pipeline.apply
(TextIO.read().from(args[1])).apply("orderCollection",MapElements.via(newSimpleFunction<String, KV<String, String>>() {……}));
4、 join處理——beam是通過Transforms正規化,在管道中操作資料,使用者需以方法(函式)的形式提供處理邏輯物件(也就是“使用者程式碼”)。本例中使用的是beam SDKs提供的通用方法CoGroupByKey實現對2組關係資料集(key/value)的join操作。
final PCollection<KV<String,CoGbkResult>>cogrouppedCollection = KeyedPCollectionTuple.of(userInfoTag,userInfoCollection).and(orderTag,orderCollection).apply(CoGroupByKey.<String>create());
5、 結果資料儲存結構樣式——封裝資料處理結果為自定義物件
PCollection<String> formattedResults = finalResultCollection.apply("forma
ttedResults",ParDo.of(new DoFn<KV<String,String>, String>(){…}));
6、 指定結果儲存路徑
formattedResults.apply(TextIO.write().to("joinedResults"));
7、送入管道,分配計算引擎執行
pipeline.run().waitUntilFinish();
3.2.4部署執行
因為Windows上的Beam2.0.0不支援本地路徑,故需要打包部署到Linux 上。
1、打jar包
2、準備待合併文字資料userInfo.txt和order.txt。文字內容如下:

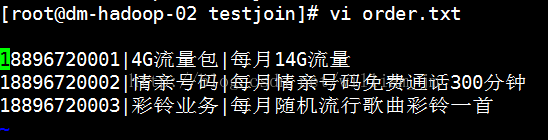
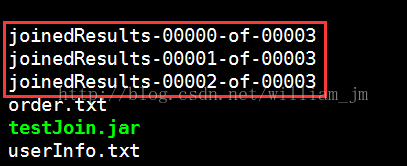
3、執行指令:java -jar testJoin.jaruserInfo.txt order.txt。
執行結果如下圖:


4Apache Beam應用場景
Google Cloud、阿里巴巴、百度等巨頭公司都在使用Beam,Apache Beam 中文社群正在整合一些工作中的Runners和SDKs IO,包括人工智慧、機器學習和時序資料庫等一些功能。以下為應用場景的幾個例子:
1、 Beam可以用於ETL Job任務
Beam的資料可以通過SDKs的IO接入,通過管道可以用後面的Runners 做清洗。
2、Beam資料倉庫快速切換、跨倉庫
由於Beam的資料來源是多樣IO,所以用Beam以快速切換任何資料倉庫。
3、Beam計算處理平臺切換、跨平臺
Runners目前提供了4種可以切換的常用平臺,隨著Beam的強大應該會有更多的平臺提供給大家使用。
5總結
1、Apache Beam的Beam Model將無限亂序資料流的資料處理抽象成“WWWH”四個維度,非常清晰與合理;
2、Beam Model統一了對無限資料流和有限資料集的處理模式,且明確了程式設計正規化,擴大了流處理系統可應用的業務範圍,例如,Event-Time/Session視窗的支援,亂序資料的處理支援等。
3、Apache Beam集成了很多資料模型的一個統一化平臺,它為大資料開發工程師頻繁換資料來源或多資料來源、多計算框架提供了整合統一框架平臺。
4、Apache Beam 主要針對理想並行的資料處理任務,並通過把資料集拆分多個子資料集,讓每個子資料集能夠被單獨處理,從而實現整體資料集的並行化處理。
5、Apache Beam也可以對資料來源中資料讀取,自定義業務規則,對資料質量進行稽核統計,儲存資料質量資訊。