
SPPnet論文總結
小菜看了SPPNet這篇論文之後,也是參考了前人的部落格,結合自己的一些觀點寫了這篇論文總結。
這裡參考的連線如下:
[http://blog.csdn.net/u013078356/article/details/50865183]
論文:
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
本篇博文主要講解大神何凱明2014年的paper:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,這篇paper主要的創新點在於提出了空間金字塔池化。paper主頁:
1. Introduction
在之前物體檢測的文章,比如R-CNN中,他們都要求輸入固定大小的圖片,這些圖片或者經過裁切(Crop)或者經過變形縮放(Warp),都在一定程度上導致圖片資訊的丟失和變形,限制了識別精確度。兩種方式如下所示。

實上,在網路實現的過程中,卷積層是不需要輸入固定大小的圖片的,而且還可以生成任意大小的特徵圖,只是全連線層需要固定大小的輸入。因此,固定長度的約束僅限於全連線層。在本文中提出了Spatial Pyramid Pooling layer 來解決這一問題,使用這種方式,可以讓網路輸入任意的圖片,而且還會生成固定大小的輸出。這樣,整體的結構和之前的R-CNN有所不同。

2. Spatital Pyramid Pooling
在解釋什麼是空間金字塔池化之前,先一下什麼是空間金字塔。這裡的理解就是以不同大小的塊來對圖片提取特徵,比如下面這張圖:
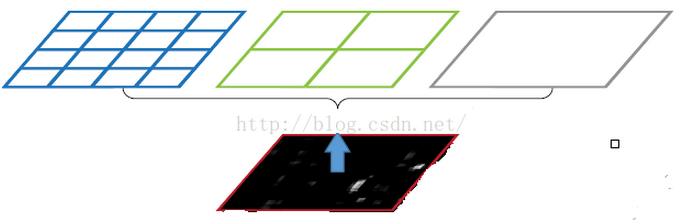
分別是4*4,2*2,1*1大小的塊,將這三張網格放到下面這張特徵圖上,就可以得到16+4+1=21種不同的切割方式,分別在每一個區域取最大池化,那麼就可以得到21組特徵。這種以不同的大小格子的組合方式來池化的過程就是空間金字塔池化(SPP)。

現在,再來看這張完整的影象,因為卷積層輸入的任意大小的圖片,所以Conv5計算出的feature map也是任意大小的,現在經過SPP之後,就可以變成固定大小的輸出了,以上圖為例,一共可以輸出(16+4+1)*256的特徵,16+4+1表示空間盒的數量(Spatial bins),256則表示卷積核的數量。
3. 物體檢測
帶有SPP layer的網路叫做SPP-net,它在物體檢測上跟R-CNN也有一定的區別。首先是特徵提取上,速度提升了好多,R-CNN是直接從原始圖片中提取特徵,它在每張原始圖片上提取2000個Region Proposal,然後對每一個候選區域框進行一次卷積計算,差不多要重複2000次,而SPP-net則是在卷積原始影象之後的特徵圖上提取候選區域的特徵。所有的卷積計算只進行了一次,效率大大提高。
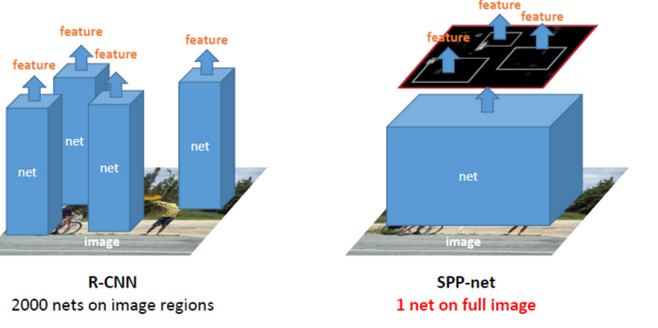
從這張圖片上應該可以看到兩者之間的計算差別。
4. 演算法應用之物體檢測
在SPP-Net還沒出來之前,物體檢測效果最牛逼的應該是RCNN演算法了,下面跟大家簡單講一下R-CNN的總演算法流程,簡單回顧一下:
1、首先通過選擇性搜尋,對待檢測的圖片進行搜尋出2000個候選視窗。
2、把這2k個候選視窗的圖片都縮放到227*227,然後分別輸入CNN中,每個候選窗臺提取出一個特徵向量,也就是說利用CNN進行提取特徵向量。
3、把上面每個候選視窗的對應特徵向量,利用SVM演算法進行分類識別。
可以看到R-CNN計算量肯定很大,因為2k個候選視窗都要輸入到CNN中,分別進行特徵提取,計算量肯定不是一般的大。
接著迴歸正題,如何利用SPP-Net進行物體檢測識別?具體演算法的大體流程如下:
1、首先通過選擇性搜尋,對待檢測的圖片進行搜尋出2000個候選視窗。這一步和R-CNN一樣。
2、特徵提取階段。這一步就是和R-CNN最大的區別了,同樣是用卷積神經網路進行特徵提取,但是SPP-Net用的是金字塔池化。這一步驟的具體操作如下:把整張待檢測的圖片,輸入CNN中,進行一次性特徵提取,得到feature maps,然後在feature maps中找到各個候選框的區域,再對各個候選框採用金字塔空間池化,提取出固定長度的特徵向量。而R-CNN輸入的是每個候選框,然後在進入CNN,因為SPP-Net只需要一次對整張圖片進行特徵提取,速度是大大地快啊。江湖傳說可一個提高100倍的速度,因為R-CNN就相當於遍歷一個CNN兩千次,而SPP-Net只需要遍歷1次。
3、最後一步也是和R-CNN一樣,採用SVM演算法進行特徵向量分類識別。
演算法細節說明:看完上面的步驟二,我們會有一個疑問,那就是如何在feature maps中找到原始圖片中候選框的對應區域?因為候選框是通過一整張原始的圖片進行檢測得到的,而feature maps的大小和原始圖片的大小是不同的,feature maps是經過原始圖片卷積、下采樣等一系列操作後得到的。那麼我們要如何在feature maps中找到對應的區域呢?
這個答案可以在文獻中的最後面附錄中找到答案:
APPENDIX A:Mapping a Window to Feature Maps。這個作者直接給出了一個很方便我們計算的公式:假設(x’,y’)表示特徵圖上的座標點,座標點(x,y)表示原輸入圖片上的點,那麼它們之間有如下轉換關係:
(x,y)=(S*x’,S*y’)
其中S的就是CNN中所有的strides的乘積。比如paper所用的ZF-5:
S=2*2*2*2=16
而對於Overfeat-5/7就是S=12,這個可以看一下下面的表格:
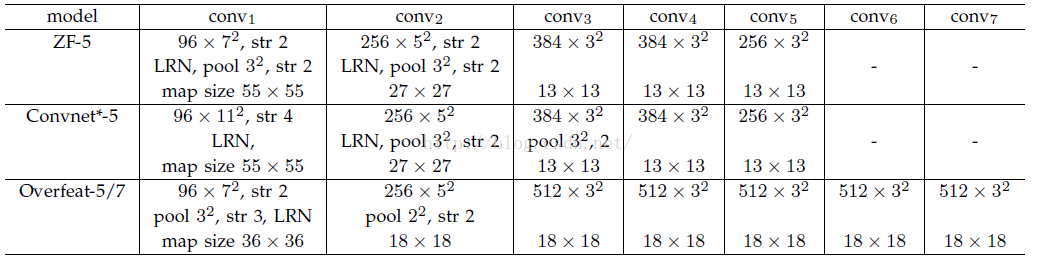
需要注意的是Strides包含了池化、卷積的stride。自己計算一下Overfeat-5/7(前5層)是不是等於12。
反過來,我們希望通過(x,y)座標求解(x’,y’),那麼計算公式如下:
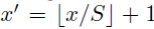
因此我們輸入原圖片檢測到的windows,可以得到每個矩形候選框的四個角點,然後我們再根據公式:
Left、Top: 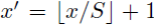
Right、Bottom:
