
NRE論文總結:Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
阿新 • • 發佈:2019-01-09
acl論文閱讀(Attention-Based Bidirectional Long Short-Term Memory Networks for
Relation Classification,中科大自動化所 Zhou ACL 2016)
資料集詳情
SemEval-2010 Task 8 dataset
- training
8,000 sentences - testing
2,717 sentences - validation
randomly select 800 sentence
演算法
blstm+attention機制,使用BLSTM對句子建模,並使用word級別的attention機制。
引數
- rate
1.0 - minibatch size
10 - L2 regularization strength
10−5 - the dropout rate
embedding layer:0.3
LSTM layer: 0.3
the penultimate layer:0.5 - Other parameters in our model are initialized randomly
效果
此論文所使用的方法F1值可以達到84.0,目前所有方法中最高的F1值為84.3(BLSTM (Zhang et al., 2015)),但此方法的缺陷是需要手動構造特徵,而此論文是把資料灌入模型,不需要手動提特徵。
演算法詳情
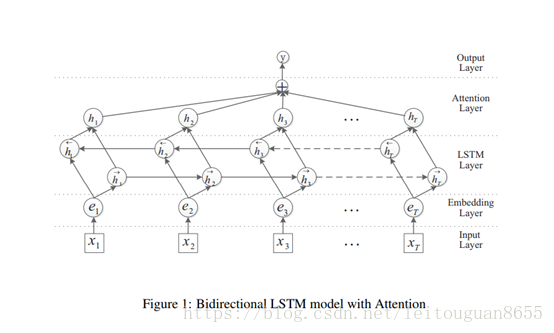
- Input Layer:將原始句子輸入該層,x_i:句子中的每個單詞,T:句子中單詞個數
- embedding層:將每一個單詞對映到一個低維向量,e_i:每個詞的向量,可以是word2vec的結果;
- LSTM層:利用BLSTM模型從step(2)中得到高階特徵;
- attention層:產生一個權重向量,並與LSTM的每一個時間點上word-level特徵相乘得到sentence-level特徵向量;
- output層:將得到的senten-level特徵向量用於關係分類。
疑惑
- 論文對lstm正反向結果的處理(即上文中的第三步)
和之前直接把lstm的最終正反向輸出直接拼接相比,作者這裡是把每一個單詞的前饋輸出與反饋輸出逐個元素求和得到的向量作為最後的 輸出,關於這一塊文中並沒有給出具體解釋。 - Attention機制中權重的處理
和隨機初始化不同的是,本論文中的權重和lstm層的輸出有關,文中沒有具體解釋這樣做的原因。
程式碼
沒有找到論文的原始碼,從github找到一份類似思想的指令碼進行除錯,指令碼除錯過程。
其他
論文理解的不透,程式碼也處於很弱的階段,且行且珍惜,祝自己保持初心!