
從線性到非線性模型-對數線性模型
從線性到非線性模型
1、線性迴歸,嶺迴歸,Lasso迴歸,區域性加權線性迴歸
2、logistic迴歸,softmax迴歸,最大熵模型
3、廣義線性模型
4、Fisher線性判別和線性感知機
5、三層神經網路
6、支援向量機
二、Logistic迴歸和SoftMax迴歸,最大熵模型
一、Logistic迴歸
分類問題可以看作是在迴歸函式上的一個分類。一般情況下定義二值函式,然而二值函式不易優化,一般採用sigmoid函式平滑擬合(當然也可以看作是一種軟劃分,概率劃分):從函式影象我們能看出,該函式有很好的特性,適合二分類問題。至於為何選擇Sigmoid函式,後面可以從廣義線性模型推匯出Sigmoid函式。
邏輯迴歸可以看作是線上性迴歸的基礎上構建的分類模型,理解的角度有多種,最直接的理解是考慮邏輯迴歸是將線性迴歸值離散化。即一個二分類問題如下:(二值函式)
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ \begin{split}…
sigmoid函式

二分類問題屬於一種硬劃分,即是與否的劃分,而sigmoid函式則將這種硬劃分軟化,以一定的概率屬於某一類(且屬於兩類的加和為1)。Sigmoid函式將線性迴歸值對映到 區間,從函式影象我們能看出,該函式有很好的特性,適合二分類問題。 因此邏輯迴歸模型如下:
KaTeX parse error: No such environment: equation at position 8:
\begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲
\begin{split}…
這裡對於目標函式的構建不再是最小化函式值與真實值的平方誤差了,按分類原則來講最直接的損失因該是0-1損失,即分類正確沒有損失,分類錯誤損失計數加1。但是0-1損失難以優化,存在弊端。結合sigmoid函式將硬劃分轉化為概率劃分的特點,採用概率$h_{\theta}(x^{(i)}) $的對數損失(概率解釋-N次伯努利分佈加最大似然估計),其目標函式如下:
KaTeX parse error: No such environment: equation at position 8:
\begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲
\begin{split}
…
同樣採用梯度下降的方法有:
KaTeX parse error: No such environment: equation at position 8:
\begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲
\begin{split}
…
又:
KaTeX parse error: No such environment: equation at position 8:
\begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲
\begin{split}
…
所以有:
概率解釋
邏輯迴歸的概率解釋同線性迴歸模型一致,只是假設不再是服從高斯分佈,而是服從0-1分佈,由於 ,假設隨機變數y服從伯努利分佈是合理的 。即:
KaTeX parse error: No such environment: equation at position 8:
\begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲
\begin{split}
…
所以最大化似然估計有:
KaTeX parse error: No such environment: equation at position 8:
\begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲
\begin{split}
…
logistic採用對數損失原因
採用對數損失的原因有二:
1)從概率解釋來看,多次伯努利分佈是指數的形式。由於最大似然估計匯出的結果是概率連乘,而概率(sigmoid函式)恆小於1,為了防止計算下溢,取對數將連乘轉換成連加的形式,而且目標函式和對數函式具備單調性,取對數不會影響目標函式的優化值。
2)從對數損失目標函式來看,取對數之後在求導過程會大大簡化計算量。
二、SoftMax迴歸
Softmax迴歸可以看作是Logistic迴歸在多分類上的一個推廣。考慮二分類的另一種表示形式:
當logistic迴歸採用二維表示的話,那麼其損失函式如下:
KaTeX parse error: No such environment: equation at position 8:
\begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲
\begin{split}
…
其中,在邏輯迴歸中兩類分別為,,二在softmax中採用兩個隨機變數組成二維向量表示,當然隱含約束.為了更好的表示多分類問題,將(不一定理解為y的取值為k,更應該理解為y可以取k類)多分類問題進行如下表示。
其中向量的第k位為1,其他位為0,也就是當 時將其對映成向量時對應第k位為1。採用多維表示之後,那麼對於每一維就變成了一個單獨的二分類問題了,所以softmax函式形式如下:
其中函式值是一個維的向量,同樣採用對數損失(多項式分佈和最大似然估計),目標函式形式是logistic迴歸的多維形式。
KaTeX parse error: No such environment: equation at position 8:
\begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲
\begin{split}
…
其中表示第個樣本的標籤向量化後第k維的取值0或者1.可以看出Softmax的損失是對每一類計算其概率的對數損失,而logistic迴歸是計算兩類的迴歸,其本質是一樣。Logistic迴歸和Softmax迴歸都是基於線性迴歸的分類模型,兩者無本質區別,都是從二項分佈和多項式分佈結合最大對數似然估計。只是Logistic迴歸常用於二分類,而Softmax迴歸常用於多分類。而且Logistic迴歸在考慮多分類時只考慮n-1類。
概率解釋
二分類與多分類可以看作是N次伯努利分佈的二項分佈到多項分佈的一個推廣,概率解釋同Logistic迴歸一致。詳細解釋放到廣義線性模型中。
二分類轉多分類思想
對於多分類問題,同樣可以借鑑二分類學習方法,在二分類學習基礎上採用一些策略以實現多分類,基本思路是“拆解法”,假設N個類別,經典的拆分演算法有“一對一”,“一對多”,“多對多”,
一對一的基本思想是從所有類別中選出兩類來實現一個兩分類學習器,即學習出個二分類器,然後對新樣本進行預測時,對這 個分類器進行投票最終決定屬於那一類。
一對多的基本思想是把所有類別進行二分類,即屬於類和非兩類,這樣我們就需要N個分類器,然後對新樣本進行預測時,與每一個分類器比較,最終決定屬於哪一類。這其實就是Softmax的思想,也是SVM多分類的思想。
//多對多的基本思想是
三、最大熵模型
很奇怪,為什麼會把最大熵模型放到這,原因很簡單,它和Logistic迴歸和SoftMax迴歸實在是驚人的相似,同屬於對數線性模型。
熵的概念
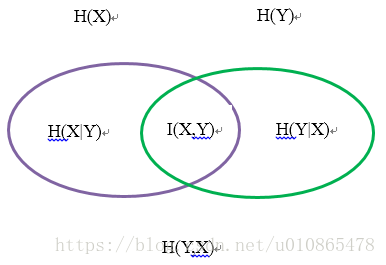
資訊熵:熵是一種對隨機變數不確定性的度量,不確定性越大,熵越大。若隨機變數退化成定值,熵為0。均勻分佈是“最不確定”的分佈 。
假設離散隨機變數X的概率分佈為,則其熵為:
其中熵滿足不等式。
聯合熵:對於多個隨機變數的不確定性可以用聯合熵度量
假設離散隨機變數的聯合概率分佈為,則其熵為:
條件熵:在給定條件下描述隨機變數的不確定性
假設離散隨機變數,在給定的條件下的不確定性為條件熵H(X|Y),也就等於
互資訊:衡量兩個隨機變數相關性的大小