
python之簡單爬蟲(爬取豆瓣出版社)
阿新 • • 發佈:2019-01-26
ok,開始我們的實驗
1.開啟瀏覽器,輸入網址,右擊網頁,檢視網頁原始碼,這裡我用的是谷歌瀏覽器

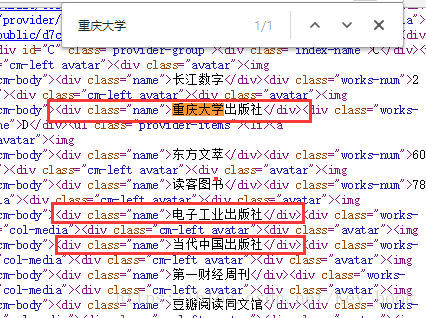
2.看上圖我們發現許多出版社名稱,接下來我們查詢一個出版社名稱,例如重慶大學
觀察下圖我們發現它們都在一個div標籤內,且class=”name” ,所以,我們開始編寫程式碼
3.程式碼
import urllib.request
import re
import os
url = "https://read.douban.com/provider/all" #獲取url
pat = '<div class="name">(.*?)</div>' #匹配規則 4.最後在你的儲存目錄下開啟檔案就可以檢視內容了!
