
【Machine learning(python篇)】-幾種常用的資料結構
阿新 • • 發佈:2019-01-26
python中有多種資料結構,資料結構之間也可以相互轉化,概念一多就容易使人混淆,對於初學者來說本來很容的概念,最終卻變成了噩夢,很難區分不同資料結構之間的用法,這樣就會造成亂用資料結構,致使執行效率低下。對於較簡單的程式來說亂用資料結構不會有太大的問題,但涉及到大資料運算,可能一個數據型別就會導致記憶體吃滿,這時善用資料結構就會變的尤為重要。
標準的python庫中一般使用list來儲存一組數值,並且可以使用自帶的各種函式對數值進行各種運算。由於list中的元素可以是各種物件,list中儲存的是物件的指標,這樣為了儲存['q','w','r'],需要生成3個指標和三個字串物件,對於大資料量的運算來說這種顯然很耗費記憶體和cpu。
此外python還提供了array模組,array物件和list不同,它直接儲存數值,但是由於不支援多維陣列,也沒有各種運算函式,因此不適合做數值運算。
numpy彌補了上面的不足,提供了兩種基本的物件,ndarray(N-dimensional array object)和ufunc(universal function object)。ndarray用來儲存單一資料型別的多為陣列,ufunc則提供能夠對陣列進行處理的函式。
可以使用array的shape屬性來獲取維度資訊
note:從(4,3)轉換為(3,4)並不是轉置,只是改變了每個軸的大小,陣列的元素在記憶體中的位置並沒有改變。
當某個軸的元素為-1時,將根據元素的個數自己推算此軸的長度,如下面的c.shape=2,-1將元素轉換為(2,6):
使用陣列的reshape方法可以建立一個改變了尺寸的新陣列,原陣列的shape保持不變。這種方法建立的新陣列和原陣列其實是共享資料儲存記憶體區域,因此修改其中任意一個數組的元素都會修改另一個數組的內容。
上面的方法都是先建立一個python序列,然後通過array函式將其轉換為陣列,這樣做效率並不高。numpy還提供了很多專門用來建立陣列的函式。
arange函式,類似於python中的range函式,通過給定開始值,結束值和步長來建立一維陣列,陣列中的值不包括終值:
另外可以使用frombuffer,fromstring,fromfile等函式從位元組序列建立陣列。如下面以fromstring為例:
下面建立了一個九九乘法表,輸出的陣列a中的每個元素a[i,j]都等於func1(i,j):
S32 : 32個位元組的字串型別,由於結構中的每個元素的大小必須固定,因此需要指定字串的長度
i : 32bit的整數型別,相當於int32
f : 32bit的單精度浮點數型別,相當於float32
然後我們呼叫array函式建立陣列,通過關鍵字引數 dtype=persontype, 指定所建立的陣列的元素型別為結構persontype。執行上面程式之後,我們可以在IPython中執行如下的語句檢視陣列a的元素型別:
| : 忽視位元組順序
< : 低位位元組在前
> : 高位位元組在前
結構陣列的存取方法和一般陣列相同,通過下標能夠取得其中的元素,注意元素的值看上去像是組元,實際上它是一個結構:
因為a是一個結構陣列,所以a[0]是和a共享記憶體資料的,因此可以通過修改a[0]來修改他的欄位,改變元素陣列中的對應欄位:
先用linspace產生一個從0到2*pi的等距離的10個函式,然後使用numpy的sin函式計算陣列x中每個元素的正弦值,然後將結果返回給y。計算之後x的值並沒有改變,而是新建立了一個數組儲存結果。如果我們希望將sin函式計算的結果直接覆蓋到陣列x中的話,可以將被覆蓋的陣列作為第二個引數傳遞給sin, 如:
sin的第二個引數也是x,那麼它做的事情是對x中的每個值求正弦值,並把結果放到x中對應的位置中。此時函式的返回值仍然是整個計算的結果,只不過它就是x,因此兩個變數的id是相同的(t和x指向同一塊記憶體區域)。
我們使用下面一個小程式,比較下numpy.math和python標準庫的math.sin的計算速度:
同樣計算100萬次np.sin要比math.sin快10倍多,這主要是np.sin在c語言級別的迴圈計算。np.sin同樣也支援單個數值運算,但是在執行單詞求正弦運算時它的效率就比math.sin低很多,如下:
請注意在計算單個值的時候math.sin效率要比np.sin高差不多10倍,這主要是由於np.sin同時支援陣列和單個值的計算,c語言內部的實現要比math.sin複雜的多,所以在使用的時候如果是單個數值儘量使用math.sin,大量的陣列或矩陣使用np.sin。另外np.sin返回的資料型別是float64,而math.sin返回的是floatl型別:
通過上面的例子我們瞭解瞭如何最有效率地使用math庫和numpy庫中的數學函式。因為它們各有長短,因此在匯入時不建議使用*號全部載入,而是應該使用import numpy as np的方式載入,這樣我們可以根據需要選擇合適的函式呼叫。
(1)讓所有輸入陣列都向其中shape最長的陣列看齊,shape中不足的部分都通過在前面加1補齊
(2)輸出陣列的shape是輸入陣列shape的各個軸上的最大值
(3)如果輸入陣列的某個軸和輸出陣列的對應軸的長度相同或者其長度為1時,這個陣列能夠用來計算,否則出錯
(4)當輸入陣列的某個軸的長度為1時,沿著此軸運算時都用此軸上的第一組值
由於這種廣播計算很常用,因此numpy提供了一個快速產生如上面a,b陣列的方法: ogrid物件
ogrid是一個很有趣的物件,它像一個多維陣列一樣,用切片組元作為下標進行存取,返回的是一組可以用來廣播計算的陣列。其切片下標有兩種形式:
開始值:結束值:步長,和np.arange(開始值, 結束值, 步長)類似
開始值:結束值:長度j,當第三個引數為虛數時,它表示返回的陣列的長度,和np.linspace(開始值, 結束值, 長度)類似:
有關numpy中的數學運算的內容將會在下篇文章中詳細介紹!
一、list列表型別
list型別是Python中內建的, list中包含的資料之間的型別可以不相同,並且list中資料儲存的是資料的指標,因為資料型別不同所以不能一起存放到一個記憶體空間,致使list中的每個資料都會開闢一個記憶體空間,所以list型別的資料是很耗費記憶體的,list中的資料的索引從0開始。
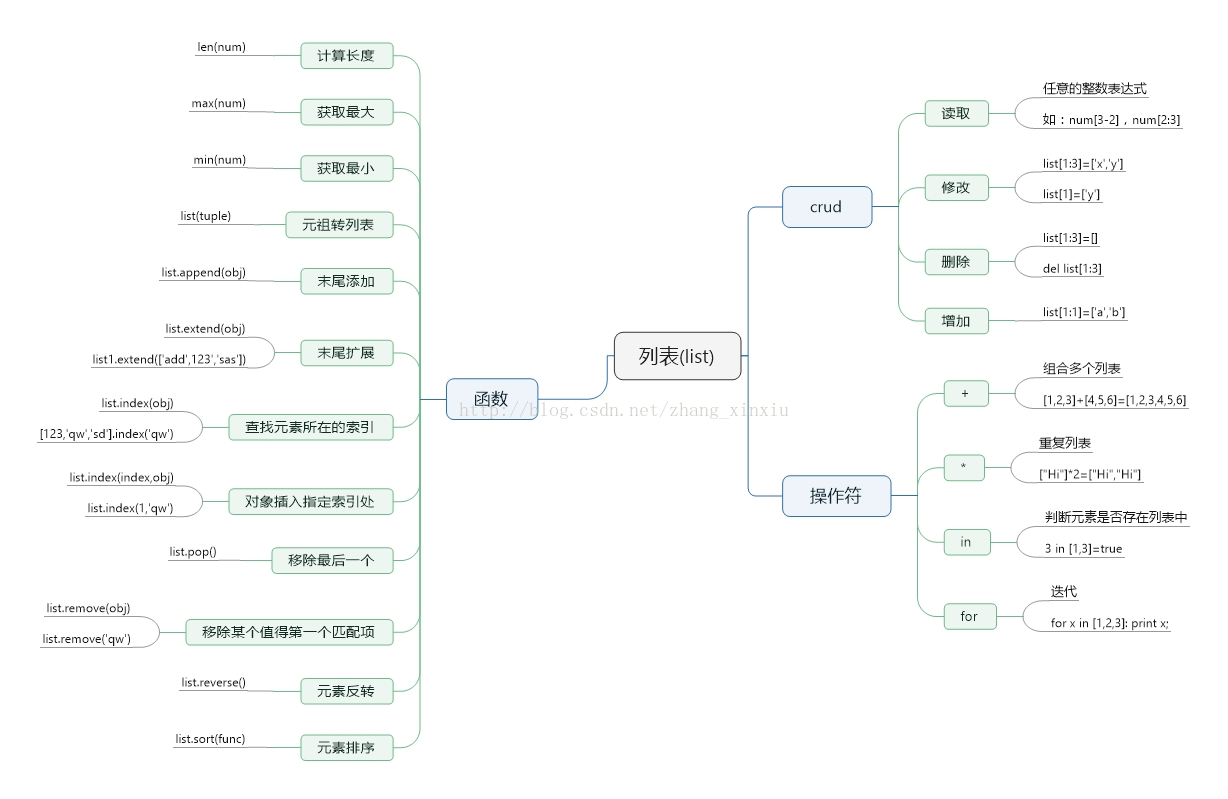
上圖是list型別基本內容,其中的函式部分所有的操作跟其它語言中的list型別是相同的,這裡面的資料每次寫入和讀取都會進行裝箱和拆箱操作,裝箱和拆箱操作既佔用記憶體又耗時,所以在大資料處理的時候慎用list型別的資料。
#定義一個list >>> l=[1,2,3,4] #檢視l >>> l [1, 2, 3, 4] #獲取l中的第二個到第三個(list的索引是從0開始) >>> l[1:3] [2, 3] #在l中增加元素 >>> l[1:3]=['a','b'] >>> l [1, 'a', 'b', 4] #在l中刪除元素 >>> l[1:3]=[] >>> l [1, 4] >>> del l[1] >>> l [1] #使用numpy中的tile函式將l轉化為2維list(tile函式會複製l中的元素,tile的第一個引數代表生成後的維度,第二個引數代表最終行資料的個數) >>> l=[1,2,3,'a','b','v'] >>> e=tile(l,(2,3)) >>> e array([['1', '2', '3', 'a', 'b', 'v', '1', '2', '3', 'a', 'b', 'v', '1', '2', '3', 'a', 'b', 'v'], ['1', '2', '3', 'a', 'b', 'v', '1', '2', '3', 'a', 'b', 'v', '1', '2', '3', 'a', 'b', 'v']], dtype='|S1') >>> print e [['1' '2' '3' 'a' 'b' 'v' '1' '2' '3' 'a' 'b' 'v' '1' '2' '3' 'a' 'b' 'v'] ['1' '2' '3' 'a' 'b' 'v' '1' '2' '3' 'a' 'b' 'v' '1' '2' '3' 'a' 'b' 'v']]
二、tuple元組型別
元組與list列表類似,也是儲存的資料的指標,不同的是元組在記憶體中申請的是固定地址,不可變更,不能修改和刪除元組中的某個元組,只能建立和刪除整個元組。為了修改元組的內容,只能再生成一個新的元組,把修改好的內容放到新的元組中,可以使用加號將多個元組合併為一個。無符號的物件,以物件隔開,預設為元組。
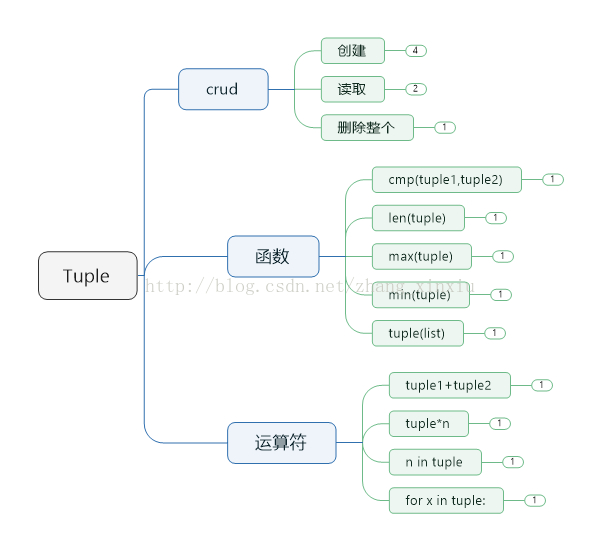
上圖為元組的基本操作,元組和列表很相似,很多用法也相同,在使用的使用如果元組能夠滿足需求的話可以考慮使用元組,因為相較列表元組的對記憶體的需求更低。
#建立元組 >>> t1=(1,2,3,'a','c') >>> t1 (1, 2, 3, 'a', 'c') >>> t2=1,2,3,'c','d' >>> t2 (1, 2, 3, 'c', 'd') >>> x,y=1,'q' >>> x,y (1, 'q') #讀取元組中的元素 >>> t1[1:3] (2, 3) >>> t1[1-3] 'a' >>> t1 (1, 2, 3, 'a', 'c') >>> t1[3] 'a' >>> t1[2-3] 'c' >>> t1[-1] 'c' #刪除整個元組 >>> del t1 >>> t1 Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 't1' is not defined #合併兩個元組 >>> t2=1,2,3,'c','d' >>> t1=(1,2,3,'a','c') >>> t1+t2 (1, 2, 3, 'a', 'c', 1, 2, 3, 'c', 'd') #元組複製 >>> t1*2 (1, 2, 3, 'a', 'c', 1, 2, 3, 'a', 'c') #取元組最大值和最小值 >>> max(t1) 'c' >>> min(t1) 1 #列表轉元組 >>> l=[1,2,3,'a','b'] >>> tuple(l) (1, 2, 3, 'a', 'b')
三、字典
字典是另一種可變容器的模型,可儲存任意型別的物件,但鍵必須是不可變的,鍵可以是字串,陣列或元組。
#建立字典 >>> dict={} >>> dict['q']=1 >>> dict1={'q':1,'w':2} #修改字典內容 >>> dict1 {'q': 1, 'w': 2} >>> dict1['q']=2 >>> dict1.update({'w':3}) >>> dict1 {'q': 2, 'w': 3} #刪除字典內容 >>> del dict1['q'] >>> dict1 {'w': 3} >>> dict1.clear() >>> dict1 {} #返回字典的字串 >>> str(dict2) '{12: 12}' #建立一個新字典,以序列seq中元素做字典的鍵,value為字典所有鍵對應的初始值 >>> dict1.fromkeys((1,2,3),3) {1: 3, 2: 3, 3: 3} #獲取字典中指定的值 >>> dict1 {'q': 1, 'w': 2} >>> dict1['q'] 1 #讀取字典中的值,如果不存在返回預設值 >>> dict1.get('q',0) 1 >>> dict1 {'q': 1, 'w': 2} >>> dict1.get('a',4) 4 >>> dict1 {'q': 1, 'w': 2} #讀取字典中的值,如果不存在返回預設值,並將值寫入字典中 >>> dict1 {'q': 1, 'e': 4, 'w': 2} >>> dict1.setdefault('r',5) 5 >>> dict1 {'q': 1, 'r': 5, 'e': 4, 'w': 2} #淺拷貝 >>> dict4=dict1.copy() >>> dict4 {'q': 1, 'r': 5, 'e': 4, 'w': 2}
四、numpy中的array
標準的python庫中一般使用list來儲存一組數值,並且可以使用自帶的各種函式對數值進行各種運算。由於list中的元素可以是各種物件,list中儲存的是物件的指標,這樣為了儲存['q','w','r'],需要生成3個指標和三個字串物件,對於大資料量的運算來說這種顯然很耗費記憶體和cpu。
此外python還提供了array模組,array物件和list不同,它直接儲存數值,但是由於不支援多維陣列,也沒有各種運算函式,因此不適合做數值運算。
numpy彌補了上面的不足,提供了兩種基本的物件,ndarray(N-dimensional array object)和ufunc(universal function object)。ndarray用來儲存單一資料型別的多為陣列,ufunc則提供能夠對陣列進行處理的函式。

4.1 ndarray
4.1.1 建立
可以使用給array物件傳遞python的序列物件來建立陣列,如果傳遞的是多層巢狀的序列,將會建立多維的陣列。>>> a=array([1,2,3,4])
>>> a
array([1, 2, 3, 4])
>>> b=array((4,5,6,7))
>>> b
array([4, 5, 6, 7])
>>> c=array([[1,2,3],[4,5,6],[7,8,9]])
>>> c
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> c.dtype
dtype('int32')
可以使用array的shape屬性來獲取維度資訊
>>> c.shape
(3, 3)
還可以通過改變shape屬性的,在保持陣列元素的個數不變的情況下,改變陣列的每個軸的長度。下面將(4,3)的c陣列,轉換為(3,4)。
>>> c
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
>>> c.shape
(4, 3)
>>> c.shape=3,4
>>> c
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
note:從(4,3)轉換為(3,4)並不是轉置,只是改變了每個軸的大小,陣列的元素在記憶體中的位置並沒有改變。
當某個軸的元素為-1時,將根據元素的個數自己推算此軸的長度,如下面的c.shape=2,-1將元素轉換為(2,6):
>>> c.shape=2,-1
>>> c
array([[ 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12]])
使用陣列的reshape方法可以建立一個改變了尺寸的新陣列,原陣列的shape保持不變。這種方法建立的新陣列和原陣列其實是共享資料儲存記憶體區域,因此修改其中任意一個數組的元素都會修改另一個數組的內容。
>>> d=b.reshape((2,2))
>>> d
array([[ 7, 8],
[ 9, 10]])
>>> b[1]=1
>>> b
array([ 7, 1, 9, 10])
>>> d
array([[ 7, 1],
[ 9, 10]])
>>> array([[1,2,3,4],[5,6,7,8],[1,3,5,6]],dtype=float)
array([[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 1., 3., 5., 6.]])
>>> array([[1,2,3,4],[5,6,7,8],[1,3,5,6]],dtype=complex)
array([[ 1.+0.j, 2.+0.j, 3.+0.j, 4.+0.j],
[ 5.+0.j, 6.+0.j, 7.+0.j, 8.+0.j],
[ 1.+0.j, 3.+0.j, 5.+0.j, 6.+0.j]])
上面的方法都是先建立一個python序列,然後通過array函式將其轉換為陣列,這樣做效率並不高。numpy還提供了很多專門用來建立陣列的函式。
arange函式,類似於python中的range函式,通過給定開始值,結束值和步長來建立一維陣列,陣列中的值不包括終值:
>>> arange(0,1,0.1)
array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
>>> linspace(0,1,12)
array([ 0. , 0.09090909, 0.18181818, 0.27272727, 0.36363636,
0.45454545, 0.54545455, 0.63636364, 0.72727273, 0.81818182,
0.90909091, 1. ])
>>> linspace(0,1,12,endpoint=False)
array([ 0. , 0.08333333, 0.16666667, 0.25 , 0.33333333,
0.41666667, 0.5 , 0.58333333, 0.66666667, 0.75 ,
0.83333333, 0.91666667])>>> logspace(0, 2, 20)
array([ 1. , 1.27427499, 1.62377674, 2.06913808,
2.6366509 , 3.35981829, 4.2813324 , 5.45559478,
6.95192796, 8.8586679 , 11.28837892, 14.38449888,
18.32980711, 23.35721469, 29.76351442, 37.92690191,
48.32930239, 61.58482111, 78.47599704, 100. ])
另外可以使用frombuffer,fromstring,fromfile等函式從位元組序列建立陣列。如下面以fromstring為例:
>>> t='abcdef'
>>> fromstring(t,dtype=int8)
array([ 97, 98, 99, 100, 101, 102], dtype=int8)
>>> fromstring(t,dtype=int16)
array([25185, 25699, 26213], dtype=int16)
>>> def func(i):
... return i%2+1
...
>>> fromfunction(func,(10,))
array([ 1., 2., 1., 2., 1., 2., 1., 2., 1., 2.])
下面建立了一個九九乘法表,輸出的陣列a中的每個元素a[i,j]都等於func1(i,j):
>>> def func1(i,j):
... return (i+1)*(j+1)
...
>>> fromfunction(func1,(9,9))
array([[ 1., 2., 3., 4., 5., 6., 7., 8., 9.],
[ 2., 4., 6., 8., 10., 12., 14., 16., 18.],
[ 3., 6., 9., 12., 15., 18., 21., 24., 27.],
[ 4., 8., 12., 16., 20., 24., 28., 32., 36.],
[ 5., 10., 15., 20., 25., 30., 35., 40., 45.],
[ 6., 12., 18., 24., 30., 36., 42., 48., 54.],
[ 7., 14., 21., 28., 35., 42., 49., 56., 63.],
[ 8., 16., 24., 32., 40., 48., 56., 64., 72.],
[ 9., 18., 27., 36., 45., 54., 63., 72., 81.]])
>>> arange(0, 60, 10).reshape(-1, 1) + arange(0, 6)
array([[ 0, 1, 2, 3, 4, 5],
[10, 11, 12, 13, 14, 15],
[20, 21, 22, 23, 24, 25],
[30, 31, 32, 33, 34, 35],
[40, 41, 42, 43, 44, 45],
[50, 51, 52, 53, 54, 55]])
4.1.2 結構陣列
下面定義了一個結構陣列,它的每個元素都有name,age和weight欄位:>>> from numpy import *
>>> persontype=dtype({'names':['name','age','weight'],'formats':['S32','i','f']})
>>> persontype
dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
>>> a=array([("Zhang",32,75.5),("Wang",24,65.2)],dtype=persontype)
>>> a
array([('Zhang', 32, 75.5), ('Wang', 24, 65.19999694824219)],
dtype=[('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
>>> a.dtype
dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
S32 : 32個位元組的字串型別,由於結構中的每個元素的大小必須固定,因此需要指定字串的長度
i : 32bit的整數型別,相當於int32
f : 32bit的單精度浮點數型別,相當於float32
然後我們呼叫array函式建立陣列,通過關鍵字引數 dtype=persontype, 指定所建立的陣列的元素型別為結構persontype。執行上面程式之後,我們可以在IPython中執行如下的語句檢視陣列a的元素型別:
>>> a.dtype
dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
| : 忽視位元組順序
< : 低位位元組在前
> : 高位位元組在前
結構陣列的存取方法和一般陣列相同,通過下標能夠取得其中的元素,注意元素的值看上去像是組元,實際上它是一個結構:
>>> a[0]
('Zhang', 32, 75.5)
>>> a[0].dtype
dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
因為a是一個結構陣列,所以a[0]是和a共享記憶體資料的,因此可以通過修改a[0]來修改他的欄位,改變元素陣列中的對應欄位:
>>> c=a[1]
>>> c
('Wang', 24, 65.19999694824219)
>>> c["name"]="Li"
>>> c
('Li', 24, 65.19999694824219)
>>> a
array([('Zhang', 32, 75.5), ('Li', 24, 65.19999694824219)],
dtype=[('name', 'S32'), ('age', '<i4'), ('weight', '<f4')])
>>> a[1]
('Li', 24, 65.19999694824219)
4.1.3ufunc運算
ufunc是universal function的縮寫,它是一種能對陣列的每個元素進行操作的函式。Numpy內建的許多ufunc都是c語言級別實現的,因此它的執行速度非常快。讓我們來看個例子:>>> import numpy as np
>>> x=np.linspace(0,2*np.pi,10)
>>> y=np.sin(x)
>>> y
array([ 0.00000000e+00, 6.42787610e-01, 9.84807753e-01,
8.66025404e-01, 3.42020143e-01, -3.42020143e-01,
-8.66025404e-01, -9.84807753e-01, -6.42787610e-01,
-2.44929360e-16])先用linspace產生一個從0到2*pi的等距離的10個函式,然後使用numpy的sin函式計算陣列x中每個元素的正弦值,然後將結果返回給y。計算之後x的值並沒有改變,而是新建立了一個數組儲存結果。如果我們希望將sin函式計算的結果直接覆蓋到陣列x中的話,可以將被覆蓋的陣列作為第二個引數傳遞給sin, 如:
>>> t=np.sin(x,x)
>>> x
array([ 0.00000000e+00, 6.42787610e-01, 9.84807753e-01,
8.66025404e-01, 3.42020143e-01, -3.42020143e-01,
-8.66025404e-01, -9.84807753e-01, -6.42787610e-01,
-2.44929360e-16])sin的第二個引數也是x,那麼它做的事情是對x中的每個值求正弦值,並把結果放到x中對應的位置中。此時函式的返回值仍然是整個計算的結果,只不過它就是x,因此兩個變數的id是相同的(t和x指向同一塊記憶體區域)。
我們使用下面一個小程式,比較下numpy.math和python標準庫的math.sin的計算速度:
import time
import math
import numpy as np
x=[i*0.001 for i in xrange(1000000)]
start=time.clock()
for i,t in enumerate(x):
x[i]=math.sin(t)
print "math.sin:",time.clock()-start
x=[i*0.001 for i in xrange(1000000)]
x=np.array(x)
start=time.clock()
np.sin(x,x)
print "np.math sin:",time.clock()-start
#輸出
#math.sin: 0.360840664005
#np.math sin: 0.0248599687013同樣計算100萬次np.sin要比math.sin快10倍多,這主要是np.sin在c語言級別的迴圈計算。np.sin同樣也支援單個數值運算,但是在執行單詞求正弦運算時它的效率就比math.sin低很多,如下:
x=[i*0.001 for i in xrange(1000000)]
start=time.clock()
for i,t in enumerate(x):
x[i]=np.sin(t)
print "np.sin:",time.clock()-start
#np.sin: 2.09553287431請注意在計算單個值的時候math.sin效率要比np.sin高差不多10倍,這主要是由於np.sin同時支援陣列和單個值的計算,c語言內部的實現要比math.sin複雜的多,所以在使用的時候如果是單個數值儘量使用math.sin,大量的陣列或矩陣使用np.sin。另外np.sin返回的資料型別是float64,而math.sin返回的是floatl型別:
>>> import numpy as np
>>> type(np.sin(0.5))
<type 'numpy.float64'>
>>> import math
>>> type(math.sin(0.5))
<type 'float'>通過上面的例子我們瞭解瞭如何最有效率地使用math庫和numpy庫中的數學函式。因為它們各有長短,因此在匯入時不建議使用*號全部載入,而是應該使用import numpy as np的方式載入,這樣我們可以根據需要選擇合適的函式呼叫。
4.2廣播
當我們使用ufunc函式對兩個陣列進行計算時,ufunc函式會對兩個陣列的對應元素進行計算,因此它要求這兩個陣列有相同的大小(shape大小相同)。如果兩個shape不同,則會進行如下的廣播處理:(1)讓所有輸入陣列都向其中shape最長的陣列看齊,shape中不足的部分都通過在前面加1補齊
(2)輸出陣列的shape是輸入陣列shape的各個軸上的最大值
(3)如果輸入陣列的某個軸和輸出陣列的對應軸的長度相同或者其長度為1時,這個陣列能夠用來計算,否則出錯
(4)當輸入陣列的某個軸的長度為1時,沿著此軸運算時都用此軸上的第一組值
>>> a=np.arange(0,60,10).reshape(-1,1)
>>> a
array([[ 0],
[10],
[20],
[30],
[40],
[50]])
>>> a.shape
(6, 1)
>>> b=np.arange(0,5)
>>> b
array([0, 1, 2, 3, 4])
>>> c=a+b
>>> c
array([[ 0, 1, 2, 3, 4],
[10, 11, 12, 13, 14],
[20, 21, 22, 23, 24],
[30, 31, 32, 33, 34],
[40, 41, 42, 43, 44],
[50, 51, 52, 53, 54]])由於這種廣播計算很常用,因此numpy提供了一個快速產生如上面a,b陣列的方法: ogrid物件
>>> x,y = np.ogrid[0:5,0:5]
>>> x
array([[0],
[1],
[2],
[3],
[4]])
>>> y
array([[0, 1, 2, 3, 4]])ogrid是一個很有趣的物件,它像一個多維陣列一樣,用切片組元作為下標進行存取,返回的是一組可以用來廣播計算的陣列。其切片下標有兩種形式:
開始值:結束值:步長,和np.arange(開始值, 結束值, 步長)類似
開始值:結束值:長度j,當第三個引數為虛數時,它表示返回的陣列的長度,和np.linspace(開始值, 結束值, 長度)類似:
>>> x, y = np.ogrid[0:1:4j, 0:1:3j]
>>> x
array([[ 0. ],
[ 0.33333333],
[ 0.66666667],
[ 1. ]])
>>> y
array([[ 0. , 0.5, 1. ]])有關numpy中的數學運算的內容將會在下篇文章中詳細介紹!