再談Fisher Vector
阿新 • • 發佈:2019-01-26
Fisher Vector(1)
在高斯混合模型中,我提到了特徵處理的一般流程:
事實上高斯混合模型完成的是k-means的任務,那麼通過高斯混合模型聚類後,也用一般的基於距離的方法進行feature encoding麼?不是的,高斯混合模型通常和Fisher Vector一起使用(而Kmeans一般與Bag of Words一起使用,BOW模型一般也是上述流程框圖)。現在就來對Fisher Vector做個簡單介紹。
Kernel Trick
要理解Fisher Vector, 也要先了解下Kernel。知乎上關於Kernel的問題我比較贊同第三個答案。Kernel不是一種神祕的東西,只是一種計算的trick。 在CV界中亙古不變的主題分類中,假設要訓練一個( −1,1)的二分類器,則當有一個新樣本的時候,則其屬於一類y的概率為:
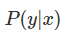
可以看出這是一個判別模型,利用logistic function對其建模(為什麼使用logistic function可以參考Andrew Ng的機器學習講義):
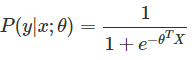
我們的目標是找到最好的θ(θ是向量),如果樣本很多的話,可以通過最大似然估計找到一組最佳的θ^來達到最好的分類效果。但是在樣本較少的情況下,可假設θ的先驗概率分佈服從均值0的高斯分佈,即θ~N(0,ξ),ξ可通過統計樣本得到,那麼有
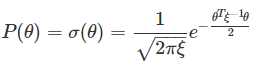
利用最大後驗概率來估計,假設一共有N個樣本xi(i=1,2,3,…,N),且相互獨立,則
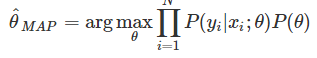
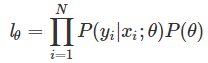
對lθ兩邊取ln對數,則:
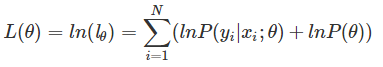
對θ求導:
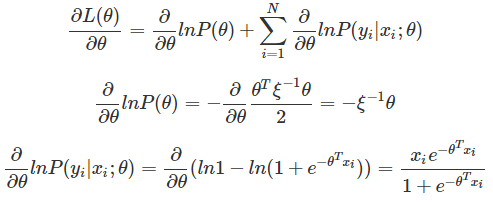
令∂L(θ)∂θ=0,有
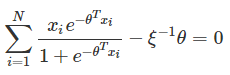
求解過程如下:
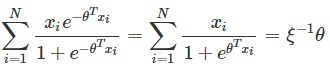
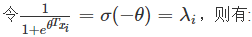
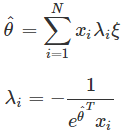
將結果帶入 P(y|x;θ),最終得到:
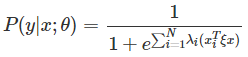
令K(xi,x)=xTiξx為核函式,該核函式為線性核。
Fisher Vector(2)
在Fisher Vector(1)中介紹了線性核,為了滿足不同的需求,實際應用中會使用多種多樣的核函式,Fisher Kernel就是其中的一種。 # Fisher Kernel