
《python資料分析讀書筆記》--- 資料探索(一)
前言
當收集到初步的樣本資料集後,需要對資料從數據質量分析和資料特徵分析兩個方面進行探索分析,其中,資料質量分析要求我們先檢測資料的是否存在缺失值和異常值;而資料特徵分析要求我們在資料探勘建模前,通過頻率分佈分析,對比分析,帕斯托分析,週期性分析,相關性分析等分析方法,對採集的樣本資料的特徵規律進行分析,以瞭解資料的規律和趨勢,為資料探勘等後續環節提供支援。
資料質量分析
一般不符合要求,不能直接進行分析的資料稱之為髒資料,而資料質量分析主要是就是檢測原始資料中是否有髒資料,一般髒資料包括以下內容:
- 缺失值
- 異常值
- 不一致值
- 重複資料和含有特殊符號
(1) 缺失值分析
資料缺失一般是記錄缺失和記錄中的某個欄位缺失,兩者都會造成分析資料結構不準確。從總體上講,一般分為3中處理方法,分別是刪除,填充,以及不處理。
(2) 異常值分析
資料異常是指收集資料的個別資料錄入錯誤和不合常理的,其明顯偏離其餘的觀測資料。
其中分一下三個方面進行分析
- 簡單統計分析
統計量最大值和最小值,判斷是否超過合理範圍。 - 3倍標準差原則
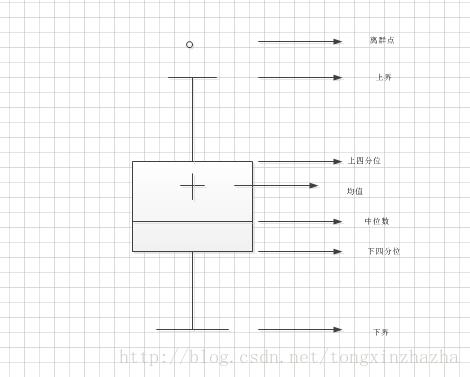
對於服從正態分佈的資料,異常值定義為測試值中與平均值相差3倍標 準差的值,而對於非正態分佈,可設定為遠離平均值的多少倍標準差來選取異常值。 箱形圖模型
指標如下
QL 下四分位數,表示全部觀測值有四分之一資料比它小
QU 上四分位數,表示全部觀測值有四分之一資料比它大
IQR 四分位數間距,IQR = QU-QL
異常值定義為:小於QL-1,.5IQR 或者 大於QU+1.5IQR
(3) 一致性分析
資料一致性是指資料的矛盾性和不相容性,不一致一般發生於資料整合過程中,可能是多資料來源整合,對於重複放置的資料未能夠進行一致性更新造成的。例如,兩張表都存放使用者的TEL,當用戶更新TEL時候,一張表更新,而另外一張沒有更新,則導致了不一致的資料。
資料特徵分析
(1) 分佈分析
分佈分析解釋資料的分佈特徵和分佈型別。資料一般分為兩種類別,定量資料與定性資料,定量資料一般是用現象的數值來表示現象的資料特徵,而定性資料則是根據分析者的經驗直覺等,對分析資料的品質特徵,常進行的是分類分佈。所以定量資料的分佈分析常使用下列步驟進行。
- a. 求極差。 (極大值減去極小值)
- b. 決定組距和組數。(組數=極差/組距)
- c. 決定分點。
- d.列出頻率分佈表。(組段/組中值/頻數/頻率/累計頻率)
- e. 繪製頻率分佈直方圖。
而定性資料分佈分析常使用的是餅圖和條形圖。
(2) 對比分析
對比分析是指將兩個相互聯絡的指標進行比較,從數量上展示和說明研究物件規模的大小,水平的高低,速度的快慢和各種關係是否協調。(曲線的對比圖)
(3) 週期性分析
探索某個變數是否隨著時間的變化而呈現出某種週期變化趨勢。時間尺度可以分為年度、季度、月度、周度、日度、小時週期性趨勢。