
白話機器學習演算法(十三)LVQ
阿新 • • 發佈:2019-01-26
LVQ網路(Learning Vector Quantization)是前面說的SOM的一個變種,但是學習方法仍然是Kohonen的競爭方法,說他是變種,因為這個演算法是一種有監督的方法。
單看他的名字就知道,這是一種向量量化手段,如果給我K類資料,每類資料若干樣本,我要找K個向量來代表這K類資料的模式,最簡單的方法就是我對每類求均值,這是個很好的想法,但是如果我每個類中都有若干離群點,那可能會導致均值不能很好的代表那類資料的輸入模式;怎麼做呢?投票機制!LVQ,SOM都是這麼做的;
LVQ分為LVQ1,LVQ2,LVQ3,下面簡單說說LVQ2:
前面講了SOM,LVQ與SOM的區別在輸入,LVQ的輸入是有標籤的,同時其神經元也是有初始標籤的,如下圖:
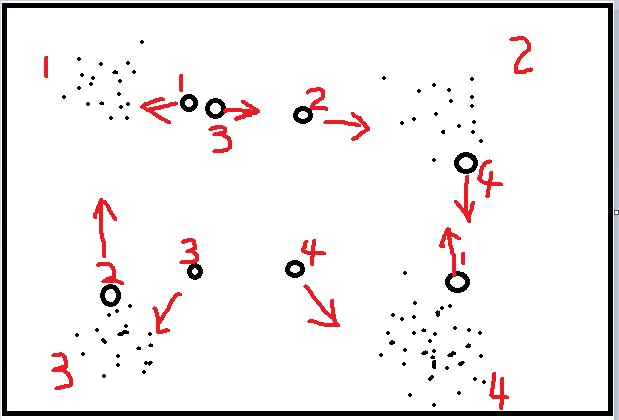
LVQ是由資料驅動的,資料搜尋距離它最近的兩個神經元,對於同類神經元採取拉攏,異類神經元採取排斥,這樣相對於只拉攏不排斥能加快演算法收斂的速度,最終得到資料的分佈模式,開頭提到,如果我得到已知標籤的資料,我要求輸入模式,我直接求均值就可以,用LVQ或者SOM的好處就是對於離群點並不敏感,少數的離群點並不影響最終結果,因為他們對最終的神經元分佈影響很小。