
微信高階研究員解析深度學習在NLP中的發展和應用 | 公開課筆記

分享嘉賓 | 張金超
整理 | Just
來源 | AI科技大本營線上公開課
近年來,深度學習方法極大的推動了自然語言處理領域的發展。幾乎在所有的 NLP 任務上我們都能看到深度學習技術的應用,並且在很多的任務上,深度學習方法的表現大大超過了傳統方法。可以說,深度學習方法給 NLP 帶來了一場重要的變革。
我們近期邀請到了微信模式識別中心的高階研究員張金超博士,他畢業於中國科學院計算技術研究所,研究方向是自然語言處理、深度學習,以及對話系統。在本次公開課上,他全面而具體地講述了深度學習在 NLP 中的發展和應用,內容主要分為以下四大篇章:
- 自然語言處理的基本概念和任務;
- 深度學習方法如何解決 NLP;
- 對話和機器翻譯當中的深度學習模型和一些雲端應用,以及使用例項;
- 對 NLP 感興趣的開發者提供一些技能進階的建議。
以下為公開課內容實錄,人工智慧頭條整理(有刪改):
一、自然語言處理的基本概念和任務
1.基本概念
首先講一下自然語言處理的基本概念和任務,這一塊講解的目的是讓大家對自然語言處理這個領域有一個框圖的認識,要知道自然語言處理的目標是什麼,任務是什麼,主要的方法大概有哪些。
Natural Language Processing,縮寫是 NLP,主要是指我們藉助於計算技術,來對人類的自然語言進行分析、理解,還有生成的一個過程。現在大家比較常見的兩個具體應用的場景,一個就是對話機器人(Chatbot),比如 AI 音箱,大家可以跟它做一些對話交流。還有機器翻譯,大家可能平時會用一些提供翻譯功能的網站,這兩個是自然語言處理比較經典的任務。

自然語言處理是語言學和電腦科學的交叉學科,語言學方面主要涉及到詞法、句法、語用、語義等等,語言學家他們會語言學理論去研究。電腦科學方面會涉及到統計理論、機器學習、優化方法以及資料視覺化、深度學習等,它們兩個交叉起來叫做計算語言學,即以計算的方法來處理語言。
關於自然語言處理任務的重要性大家可以想一下,一方面語言是人類長期進化來的能力,是人類自然的一種互動方式,所以假如機器能夠非常準確、全面地理解我們的語義,那麼人機互動的方式會發生一個非常革命性的變化。但現在自然語言處理能力還沒有到那種程度,我們還需要各種輸入、輸出裝置。另一方面,人類的知識大規模的儲存形式是文字,包括大量的書籍,可以把它電子化成數字化的文字,針對這些海量的文字做分析處理,從而得到有價值的資訊,這也需要強大的自然語言處理能力的支撐。
2.自然語言處理任務
自然語言處理任務大概有哪些?我個人做了一個總結,基本可以劃分為五層:詞法分析、句子分析、語義層面的分析、資訊抽取,頂層任務。頂層任務直接面向用戶,提供如機器翻譯、對話機器人這樣的產品化服務。
首先是詞法分析層。第一個是分詞任務,英文的文字是由空格分隔開的單詞序列,但中文詞和詞之間沒有清楚的分隔符。對於“長江是中華民族的母親河”這個句子,我們來做自然語言處理分析,最小的語義單元就是字,字的歧義性非常高。如果我們對它做切分的話,那麼“長江”、“中華民族”,還有“母親”、“河”這種完全可以切出來,句子的基本語義單元就變成了詞,這就是分詞任務的目的。
第二個任務是新詞發現,該任務希望發掘文字中的一些新詞,比如說“活久見“、”十動然拒“、”十動然揍”這種網路熱詞。第三個任務是形態分析,形態分析主要針對形態豐富的語言。給定一個詞,把裡面的詞幹、詞綴、詞根等拆分出來,然後做一些形態還原、形態切分任務,給上面的任務提供一個更好的輸入。
第四個任務是詞性標註。詞有動詞、名詞之類詞性,詞性標註任務就是把每一個詞的詞性給標出來。另外還有拼寫校正任務,應用場景就是我們在用文字編輯器的時候,打錯了字會被標紅,編輯器還能提供自動糾錯的功能。
第二個層面的任務是句子分析(Sentence Analysis)。包括句法分析任務。句法分析包括淺層的句法分析和深層的句法分析,比如像組塊分析就是給定一個句子,然後來標出裡面一些名詞短語或者動詞短語的塊。我們直接來看下面的句法樹,我們怎麼來看組塊呢?比如前面這個 “My dog” 是 NP,NP 是指一個名詞短語,S1,VP1 是一個動詞短語,組塊分析的目的不是想把這棵樹分析出來,而是想把這個 NP 和 VP 作為一個 Chunk(組塊) 給標註出來。

第二個任務是超級標籤標註(Super Tagging),這個任務並不想得到最後句法樹的結構,只想得到跟我這個詞當前相關的樹的結構。比如說我想得到 My 的這個 Super Tagg,從 ROOT 到 My 的這一條樹的路徑是必須儲存的,其他上面的一些終結符的結點會被去掉。
成分句法分析任務的目標是畫這棵樹,把句子的結構分析出來。從一個根的結點出發,下面會有 NP、VP,最後到一個終結符上去。
依存句法分析任務是來分析句子裡詞和詞之間的依存(修飾)關係,由這些修飾關係來構成一棵依存的句法樹。
語言模型任務,是訓練一個模型來對語句合理的程度(流暢度)進行一個打分。
語種識別任務,是給定一段文字,識別出這段文字是用哪一個語言書寫的,這可以被用到機器翻譯任務中。
第三個任務是句子邊界檢測,我們知道中文句子邊界是非常明顯的,會由句號、歎號或者問號等做分隔,但是對一些語言來說,句子之間是沒有明顯邊界的,所以做句子層面的分析之前,首先要對它進行句子邊界的檢測,比如泰語。
再往上就是語義分析(Semantic Analysis)層。語言學家想用一些結構化的符號來表達語義,但是現在的深度學習,大量的語義其實是分散式的表示,也就是一系列數值,具體哪一種形式會真正地表達語義還沒有定論。
語義分析層中,第一個任務是詞義消歧,一個詞它可能會有歧義,該任務是來確定它準確的詞義。
第二個任務是語義角色標註,是一種淺層的語義分析。該任務要標出句子裡面語義決策動作的發起者,受到動作影響的人等等。比如 “A 打了 B”,那麼 A 就是一個施事, B 就是一個受事,中間就是一個打的動作。
第三個任務是抽象語義表示(Abstract Semantic Parsing),它是近幾年提出的一種抽象語義的表示形式,縮寫是 AMR。下面這個一階謂詞邏輯演算和框架語義分析基本上是語言學家一直想把語義做一個符號化推理系統的表達。
近期在應用裡面用的比較多的語義表現形式就是詞彙、句子、段落的向量化表示,即Word/Sentence/Paragraph Vector,包括研究向量化的方法和向量性質以及應用。
這是 AMR 的一個例子,這裡面有三個句子,三個句子表達的語義是一樣的。“貓想吃魚”這個語義,有三個不同的句子,但是在 AMR 這個概念裡,對應的是一個相同的 AMR 圖。 AMR 分析的時候,會把一些無關緊要的詞去掉,比如 the 或 to。
再高一個層面的任務就是資訊抽取(Information Extraction)。比如我們給定最下面的這一段新聞,想從裡面抽一些關鍵的資訊出來,即從無結構的文本當中抽取出結構化的資訊,這是廣義的資訊抽取概念,可以先做命名實體識別,從這一段文字裡識別出人名、地名、機構名,因為這些東西相比於其他的連詞等標點符號具有更多的意義。
第二個任務是實體消歧,該任務是把句子中出現的名詞準確關聯到現實當中的一個物件。
第三個任務是術語抽取,是從文本當中抽取特定的術語。
第四個任務是共指消解。句子裡面會出現代詞或者多種名詞表達同一個物件的現象。比如代詞的消解是找出“他、她、它”中的某一個到底指代的是哪個事物。名詞消解也是同樣的道理。
關係抽取任務是確定文本當中兩個實體之間的關係,比如說誰生了誰,兩個實體一個是生一個是被生。
事件抽取任務是一個更復雜的過程,要抽取出時間、地點、人物、發生的事件等等,這是更結構化的資訊抽取。
這裡,我把情感分析和對話系統用到的意圖識別和槽位填充也歸結到這個部分裡了。舉個情感分析這個應用場景的例子,比如我們去購物網站買東西,買完了以後會給它做評價,那麼使用者的這個評價到底是正面的還是負面的情緒?我們需要對這個評價分析出情感傾向。
意圖識別是對話系統當中一個比較重要的模組,是要分析使用者跟對話機器人說話的時候這句話的目的是什麼,比如說播放音樂,那麼意圖就是音樂。
槽位填充是和意圖識別搭配起來使用的,意圖識別出來了,但是意圖要有具體的資訊,比如你的意圖是讓機器人幫你去定明天早上從北京到上海飛的一張機票,意圖識別出來是定機票,那麼要抽取一些資訊的槽位,比如時間是“明天早上”,出發點是“北京”,目的地是“上海”,這樣才能配合起來做後面的一些程式性的工作。
再往上就是頂層任務了,這些任務面向使用者提供自然語言處理產品。一般這些任務會用到之前我們說的很多自然語言處理技術,目的是搭建一個綜合性的系統。
第一個就是機器翻譯任務,是要實現文字的自動翻譯。
文字摘要是給定大段的文字,把裡面的梗概提取出來,把它縮短,使得更方便閱讀或者更方便提取關鍵的資訊。
問答任務是問系統一個問題,它能給你一個準確的答案。比如,你問“周杰倫的母親叫什麼名字”,這個系統需要反饋給你一個非常準確的答案。
對話系統就是你和機器進行互動,它給你相應的反饋,執行相應的指令。閱讀理解是給定機器一整篇文章,然後對它提一些與文章相關的問題,它能夠給你答案,很像我們考英語閱讀理解。
還有一個任務就是自動文章分級,給定一篇文章,對文章的質量進行打分或者做一個分級的操作。
3.自然語言處理任務的難點
自然語言處理任務為什麼難?我個人認為主要在於:歧義問題、知識問題、離散符號計算問題,還有語義本質的問題。
先說歧義問題,有些話的表達可能會有歧義或者模稜兩可。我們上面舉了幾個詞彙層面歧義的例子,比如上面這三個句子是詞或者字層面的歧義,“我們研究所/有東西”,這裡的研究所是一個名詞,“我們研究/所有東西”,這裡的“研究”就變成一個動詞。再往下就是一詞多義的問題,第一個句子是“山上的杜鵑開了”,第二個是“樹上有一隻杜鵑在叫”,同樣是杜鵑,前面說的是一種花,後面是一種鳥,這也會造成歧義。
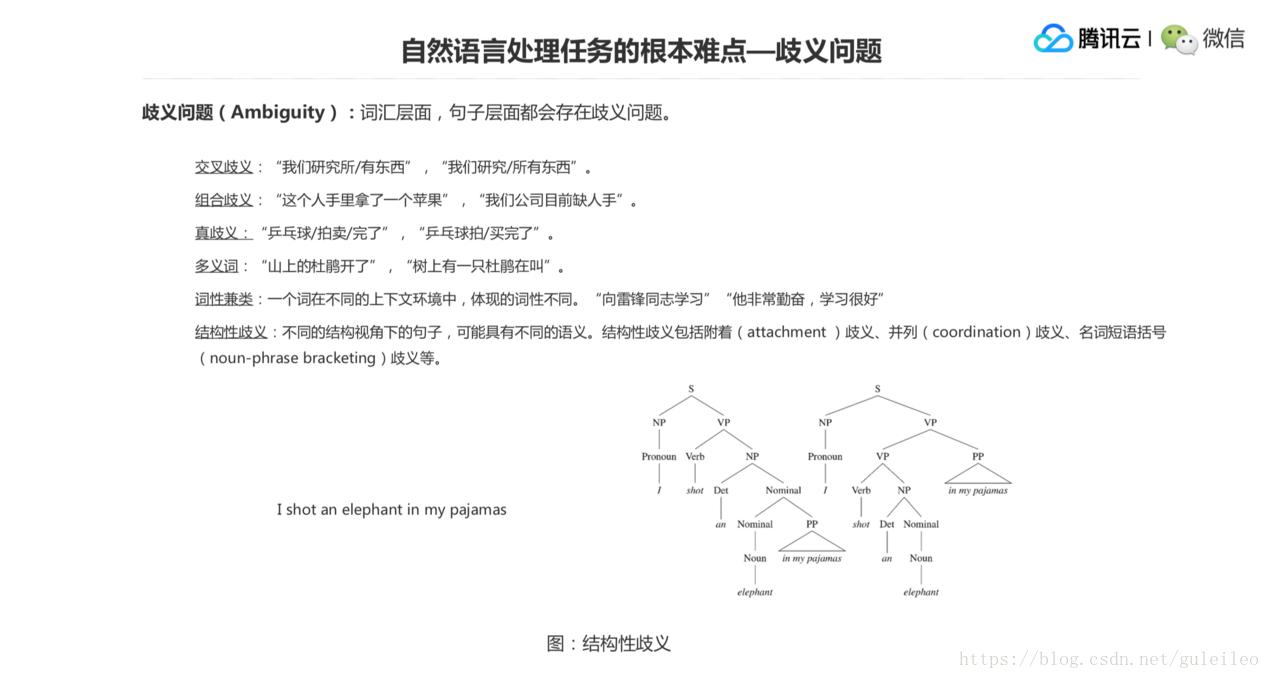
還有詞性兼類問題,一個詞在不同的上下文環境當中體現的詞性也會不同,比如說第一個句子“向雷鋒同志學習”,這個學習是一個動詞。第二個是“他非常勤奮,學習很好”,這個學習是一個名詞,所以也會出現這種詞性兼類的歧義。
再一個就是結構性的歧義,分很多種,看一個比較簡單的應用的例子,I shot an elephant in my pajamas,如果我們把後面這個 elephant in my pajamas 看成一個 NP 的話,這個是說“我擊中了睡衣裡面的一頭大象”,這在語義上是不對的。如果 in 後面的這個介詞短語來修飾這個 an 的話,它翻譯出來就是“我穿著我的睡衣擊中了一頭大象”,這才是合理的。
第二個是知識問題,是指知識稀疏或者詞彙稀疏,詞彙稀疏導致了搭配稀疏,然後導致了語義稀疏,它有一個遞進關係。一個比較出名的定律叫齊夫定律(Zipf Law),這個定律是說在自然語言語料當中,一個單詞出現的頻率和它在頻率表當中的排名基本成一個反比關係。例如,對英語的 Brown 資料集裡的語料進行統計,“the、of、and”是前三高的詞頻。
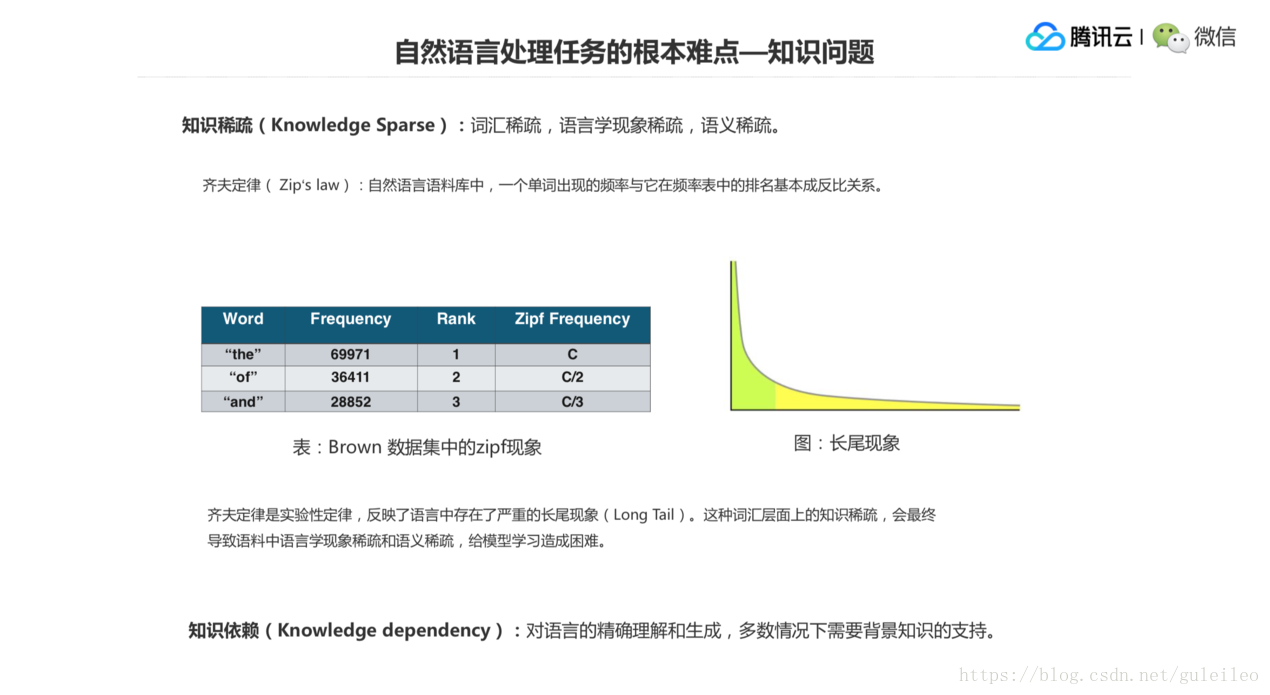
以 Zipf 的角度來看,它認為排位和詞頻實際上是可以用一個反比關係來對它進行建模。那麼這個語料也很好地反應了基本上這個“the”大概在 7 萬左右,“of”大概在 36000 左右,那就變成了 c 和 c/2 這麼一個倍數的關係。“and”和“the”構成了 c/3,這是一個 1/3 的關係,這是一個 Zipf 的現象,這個現象會引起詞頻下降非常快,會導致一個長尾現象。即有很多詞出現的次數很少,但是數量又很大,當它們全部加起來的話,又不能把它們忽略掉。
再一個問題是知識依賴,這是說對語言精確的理解和生成,有很多時候是需要背景知識支援的,比如“蘋果”到底是一個水果還是一個手機,就需要有一些知識來支援,不能根據一句話就完全能把它理解掉。
知識稀疏的問題,從機器學習的角度來看的話,相當於給了一個模型非常不均勻的資料分佈,那對模型來說它的學習難度就會變大。
第三個是離散符號計算的問題。我們看到的文字其實都是一些符號,對計算機來說,它看的其實也是一些離散的符號,但我們知道計算機其實最擅長的是數值型的運算,而不是符號的推理,並且符號之間的邏輯推理會非常複雜。現在在統計機器學習模型裡面做的是用 one-hot,就是用一個非常稀疏的向量來表示這個詞的形式,把它作為特徵輸到後面的模型裡去,但這面臨一個高維的問題。另一個是符號和符號之間都是正交的,那麼就很難建立起符號之間的相關關係,這是深度學習方法能夠部分解決一下這個問題。
第四個就是語義問題,到底什麼是語義?什麼是語義?語言裡面到底是什麼東西?符號背後真正的語義怎麼來表示?語言學家他走的路子就是我構建好多形式化的、結構化的圖之類的,這種結構去做語義或者是一些符號推導系統,認為它可以接近語義本質。但是,這些其實走得越遠離計算機就越遠,因為它越符號,語義的可解釋性就會很差。拿數字來表示語義,我們也不知道這個數字到底是什麼東西。所以目前為止現在研究領域對這個問題解決得比較差。
假如語義問題真的解決了,那所有的自然語言處理任務都不是問題,但目前來說,我們現階段做的事情實際上僅僅是需要在做每一個子問題的時候,把這個子問題用各種各樣的方法把它做好就行了,語義真的是比較難解決的問題。
目前來說幾乎所有的自然語言處理方法都是基於資料驅動,也就是統計機器學習的模型,那麼資料質量加上模型的能力就決定了最後的任務表現,而並非機器真的能全面理解人類語言當中的語義,比如市面上的對話機器人很大的程度上要歸於資料或者一些規則,而不是機器真的能像人類一樣地去思考、推理,然後給你一個非常人格化的回覆,現階段人工智慧還沒有達到那種要求。
4.小結
我們大概講了自然語言處理任務的基本概念,還有一些目前自然語言處理主要在解決的任務。一般來說一個做 NLP 的人,他可能以他的能力做到裡面的一個或者幾個任務。自然語言處理是一個交叉學科,它會使用語言學的理論,但是不會說去研究語言學,也會去用一些統計機器學習或者演算法模型方面的東西,但目的又不是去徹底研究透演算法層面的東西,而是說只是追求可用。當然現在的趨勢是很多做自然語言處理的人都在深入地研究演算法模型,但歸根到底我們想解決自然語言處理的問題其實是怎麼對這個問題進行建模然後解決好。
二、深度學習方法解決NLP任務
1.自然語言處理方法的演化
下面講一下深度學習方法和之前的方法,還有一些深度學習方法解決基本任務的介紹。
自然語言處理方法的演化大概可以這麼來劃分,一個是叫理性主義,一個叫經驗主義。

理性主義很好理解,就是寫規則,來處理這個問題。經驗主義就是加資料,加演算法模型的方式來解決問題。理性主義基本上是語言學家來主導,就是研究語言,寫語言學的知識,然後用這些語言學知識的規則來處理自然語言處理的任務。
這個方法的好處就是可解釋性特別好,它明確知道這個輸出的結果是由哪條規則產生的作用,但問題是規則越寫越多的時候,很容易前後起衝突,寫規則的成本也非常高,其實對自然語言處理的理解,處理方法的演化方面會比較慢。
經驗主義方法就是所有的知識都在資料裡面,從資料裡面學東西,不關心裡面的語法規則是什麼,這個研究階段就由電腦科學家主導,主要的方法就是基於資料驅動的機器學習模型加少量的語言學知識。
經驗主義裡我們給它又劃分成了兩個階段,一個是統計機器學習方法的階段,它的一個特點是基於符號特徵的計算,就是抽一些符號化的特徵,然後交給機器學習模型來做。第二個特點是它一般是用傳統的針對非 DL 的一些方法,比如 LR、SVM 之類。
到了近幾年,NLP 主要是用深度學習方法,它的第一個特點就是分散式表示特徵,也就是拿一串數字來表示一些語義作為特徵,交到後面的分類器來做。第二個特點是以各種神經網路為核心模型,而不再是以前的這種 SVM 等其他的分類器之類的東西,這是深度學習方法兩大比較突出的特徵。
我們來看理性主義模型下自然語言處理的一個視角,這是研究機器翻譯的一位德國教授提出的機器翻譯金字塔模型,當然後面到統計的時代大家也借用這個模型來表達機器翻譯的過程。
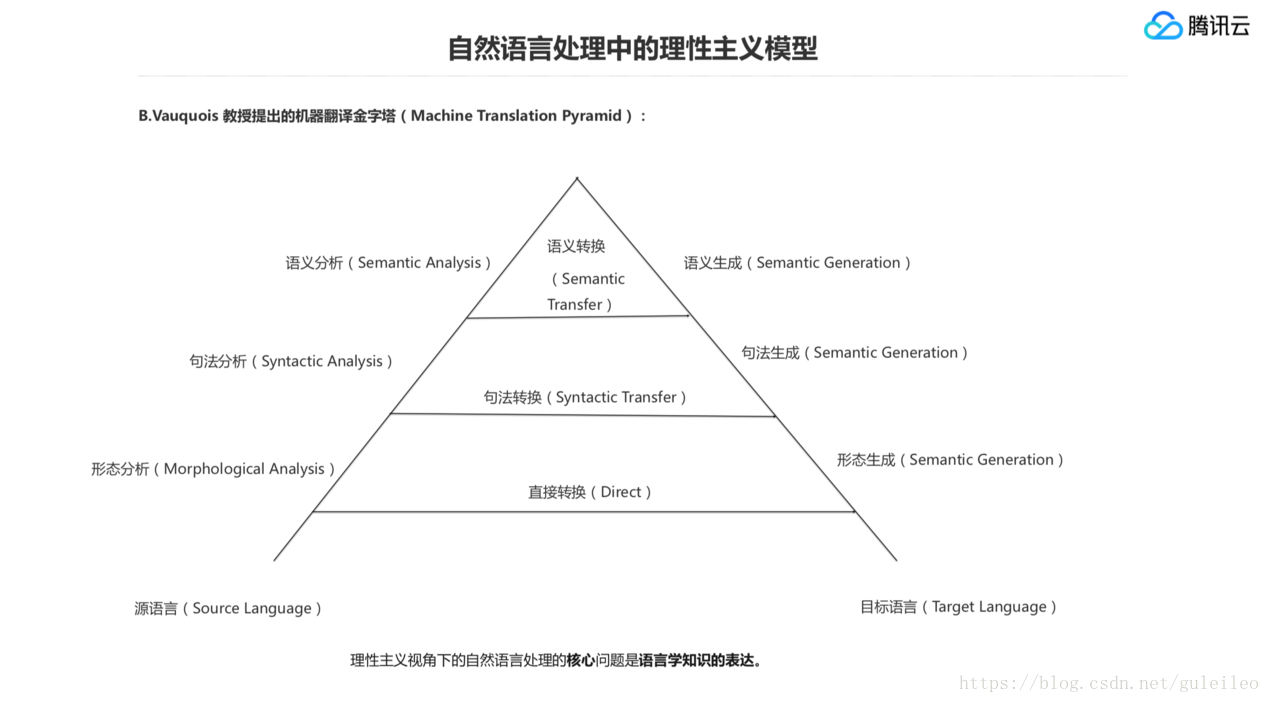
從這個視角看語言,要先做形態分析,然後再做句法分析、語義分析,再往上是中間語言最高的形式,然後往右邊去轉換,這是一個機器翻譯的過程。給一個源語言的句子,轉換成目標語言的句子,那麼它認為從上到下是一個遞進的,從左到右是一個層層轉化的過程,所以它在處理某一任務的時候也是基於語言學結構來處理,這是理性主義模型下一個非常經典的看法。
到經驗主義模型基本上是這樣的,其實就是一個機器學習的過程,就是先構建語料,做標註,再設計特徵,做特徵提取,然後交給機器學習演算法,訓練好模型做輸出。我們說前面的階段一個核心問題是語言學知識表達的問題,後面經驗主義模型下一個核心的問題實際上是對這個任務的建模和機器學習演算法的求解。

2.自然語言處理常用的問題模型
首先我們在這裡區分兩個概念,一個叫問題模型,一個叫演算法模型。問題模型就是把這個任務怎麼把它形式化出來,是一個建模的過程。演算法模型是說怎麼來拿某個演算法去解決這個問題建模的形式,就是給你一個事情,你把它分解開來,然後看看它到底能套哪個模型,後面就是對這個模型的求解問題。
NLP 當中常用的問題模型包括分類模型、序列標註模型和序列生成模型。
分類模型是一個比較狹義的分類概念。實際上序列標註模型和序列生成模型也可以理解成一個廣義分類的問題。分類是指像文字分類或者給句子做情感分析之類的狹義模型。

第一個分類問題就是給你一段文字做類別的標註,比如你對它進行文字分類,給你一個新聞,它到底是一個政治、體育、財經或者其他類別的新聞。意圖識別,就是前面說到的和一個對話機器人聊天的時候你給它一句話,然後這個機器人它能識別出來你的意圖是要幹嘛。情感分類的話就是前面說的你買的東西,你對它做一個評價,這是正向的還是負向的,實際上都可以抽象成問題模型裡面的一個分類模型。
分類模型傳統的一個解決方法就是標帶標註的語料,再特徵提取,然後訓分類器進行分類。這個分類器就會用邏輯迴歸、貝葉斯、支援向量機、決策樹等等。
第二個是序列標註模型。序列標註我們拿分詞這個事情來做一個比較好的舉例,實際上數學建模是這樣,你有 N 個 X,它構成一個序列,你可以認為它是 N 個字,這個句子裡面有 N 個字,給每個字加上一個標籤,它生成 N 個序列的標籤,那麼分詞這個問題就抽象成字的序列標註的模型。

比如說“長江”它應該是構成一個詞的,那麼就給它分成分類的侯選標籤,就是 begin、middle、end 或者 single。“長江”應該在 begin 的位置,“江”應該在 end 的位置,如果它標成 b 了,它標成 e 了,很明顯是它們兩個字要構成一個詞了。假如這個模型是標註成了 s,那就是 single,它就是自己一個詞。“中華民族”這個就是 begin,middle,middle,end,那這四個合起來就是“中華民族”這一個詞。
那麼整個分詞的過程,就是從上面這一行藍色到下面這個詞的藍色,那就是一個序列標註,你只要對每個字分類分正確了,那分詞的結果就是對的。
這是一個序列標註的模型,分詞是一個非常經典的任務。詞性標註、命名實體識別,甚至現在大家做句法分析或者語義角色標註,也開始使用序列標註模型來做了。傳統做序列標註模型的一些方法,包括隱馬爾科夫、最大熵、條件隨機場、平均感知機等等,是用來求解序列標註的問題的。這兩個層面上的模型我們要分開。
第三個是序列生成模型。所謂的序列生成模型就是如何生成一段文字,逐詞地來生成,使得生成的這個文字是合理的。怎麼來評價它的合理性?如果是單語生成的話,那麼可以使用語言模型,保證流暢度、合理性越高越好。
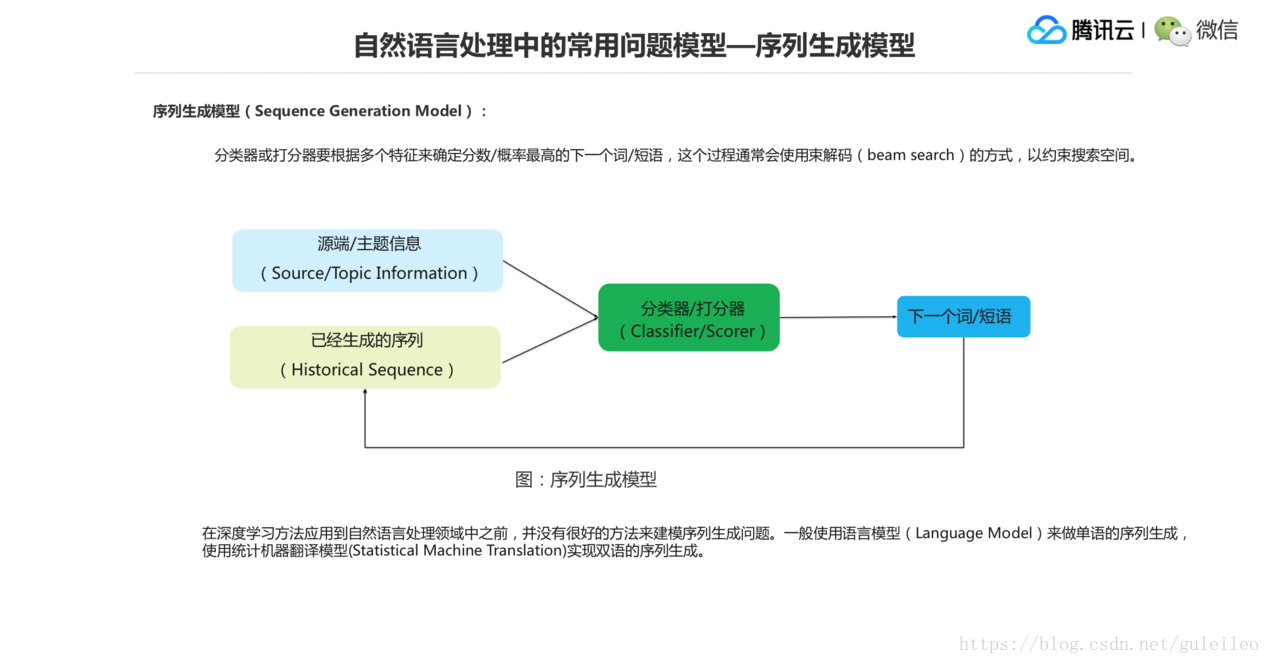
如果是一個雙語生成的任務,像機器翻譯任務,你就要約束它跟原來的語義接近的情況下,生成的序列更合理。在深度學習方法出來之前,其實沒有太好的方法來建模序列生成問題,一個就是這個語言模型來做單語生成,再一個就是用統計機器翻譯模型來做雙語生成。生成的過程當中要用一個束解碼的方式來約束搜尋空間。
3.統計機器學習演算法模型的不足
我們前面講的是一些統計的學習演算法,比如 SVM、LR 之類,這些演算法有什麼不足呢?一個就是前面需要設計一些複雜的特徵,這些特徵是要人工地去設一個特徵模板,用這些特徵模板去匹配句子裡面的一些特徵,把它抽出來,作為一個離散化的特徵來輸入到模型裡面去,這一塊是非常複雜的。
第二個是這個演算法模型對序列建模的能力很差,這個特徵在詞方面都是非常稀疏的,在對句子抽特徵的時候就更稀疏了。比如整個語料當中有 1 萬個不同的詞,那麼這個句子裡非常有可能出現了一個詞會只在幾個句子裡出現過,所以它的特徵會非常稀疏。第三個就是前面抽特徵是一步,訓練模型是一步,這個其實中間會有錯誤的誤差,甚至有一些複雜的任務,它要去進行多步的操作,這會產生一個非常嚴重的錯誤傳播問題。後面我們也會用具體的模型來解釋這個錯誤傳播的問題。
我們看一下深度學習,它可以來解決前面說的分類問題、序列標註問題、序列生成問題用到的一些基本元件,現在主要應用到的比如前向神經網路,就是一個最簡單的全連結網路。迴圈神經網路,包括純的 RNN,加門控的 RNN,還有 LSTM。還有就是卷積神經網路,這個在圖象方面用的比較多,NLP 裡面也會用。再一個就是注意力機制,這些是一些深度學習的基本元件,大家有興趣的可以自己去看公式,瞭解一些基本的模型。
為什麼說深度學習方法比前面我們說的統計機器學習的模型要強大?我們現在來逐條分析。
4.強大的深度學習方法—分散式表示
一個是分散式表示(Distributed Representation),或者更具體一點叫 Word Embedding/Word Representation 之類的。是拿這個數值來表示這個特徵,而不再是之前的離散特徵,這是一個比較經典的任務,也就是 Bengio 提出的神經網路語言模型,他把這個詞通過一個矩陣,通過查表的方式式得到一個 Word Embedding,然後交到後面去訓練這個神經網路的語言模型。現在 NLP 所有的任務基本都基於 Word Embedding。

Word Embedding 這一步怎麼來做?假如有 V 個詞,一個詞就是 W1、W2 一直到 Wv,構建一個矩陣,每一個詞可向量的維度是 M 維,那麼這個 W1 過來了以後,查表會查到 W1 對應這一類的詞向量作為它的一個表示,這個表叫 Lookup Table,這就把詞的符號轉換成一個向量形式的過程。

最右邊這個就是它的詞向量,這個詞向量是在整個模型的訓練中,可以通過 SGD 下降的方式給它回傳做調整,也就是說我們最終得到的詞向量是非常適合於這個任務的詞向量,也是得到了這個任務的目標函式下這個詞非常好的一個表達形式。符號向量化的第一個好處就是克服維度爆炸的問題,One-hot 會到一個非常高的維度,但是詞向量最小可以把它設成 20、50 之類的就解決掉了。再一個就是說它可以直接進行數值運算,因為它就是向量,向量就是數值,然後就交到後面做很大的矩陣運算,這完全沒有問題。再一個就是 SGD 自動特徵學習,這個前面我們說到了,就是 SGD 怎麼去調 Word Embedding。
5.強大的深度學習方法—序列建模方法
深度學習方法強大的第二個優點,就是序列建模。前面說序列建模很難,在前面的一些特徵設計方法裡面,在深度學習裡面,序列建模的方法就變得非常簡單了,就是以詞彙層面的分散式表示為基礎,然後對詞之間的互動進行計算,生成整個句子的一個分散式表示。整個過程都是在做計算,而不是在做特徵模板的設計。
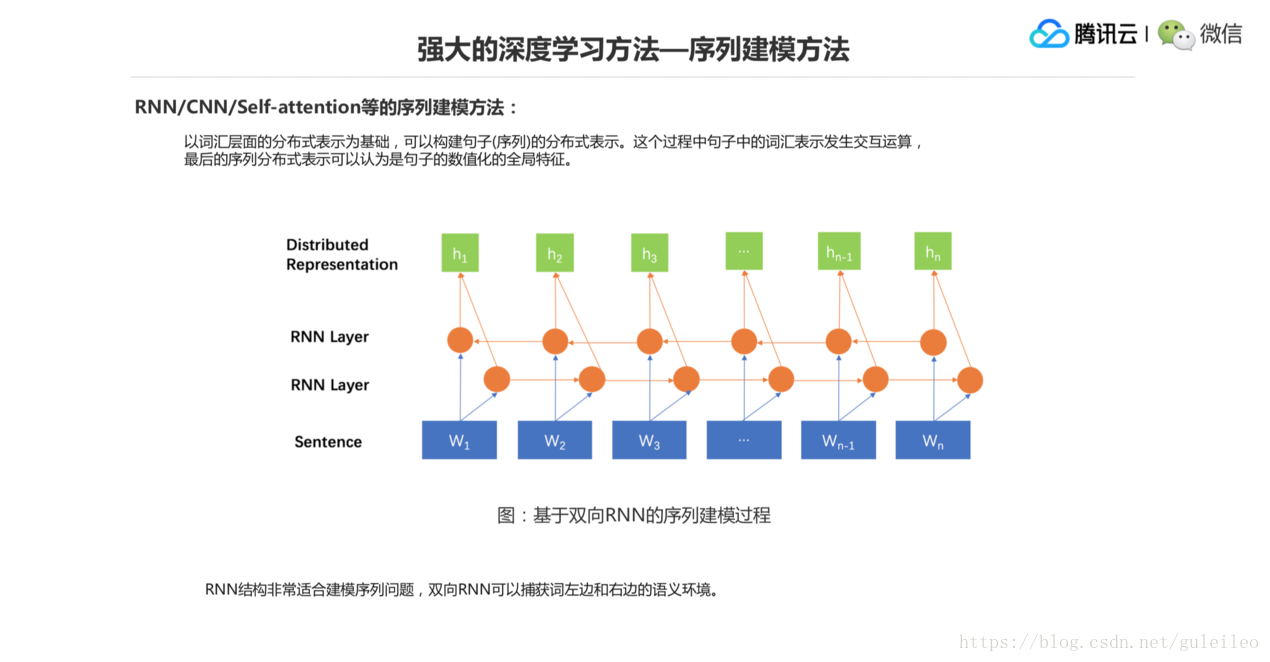
這個圖是一個比較具體的基於雙向 RNN 的一個序列建模模型,我們看到會有兩層 RNN 層,第一層是從左向右地對詞向量進行壓縮表示,第二層是從右向左做壓縮表示,然後兩層的表示連線起來,作為最終整個句子的表示,用 N 個詞,後面生成的分散式表示就可以是 N 個向量,每個向量可以認為是它對應的下面這個詞的一個上下文環境的語義表示,作為整個句子的特徵。也可以用最後面一個,就用 Hn 可以表示一個句子的特徵,也可以把這些東西作為一個句子特徵的表示。也就是說這個地方用神經網路的方式直接基於詞做計算得到句子的特徵表示,就繞過了特徵模板,非常方便。
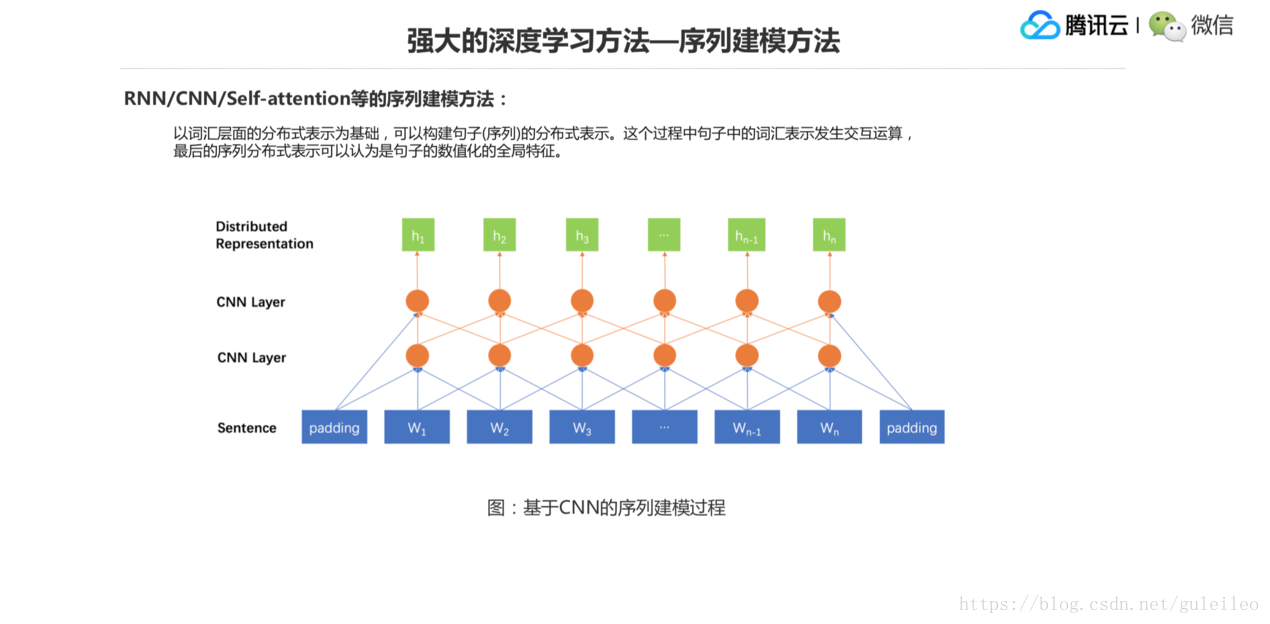
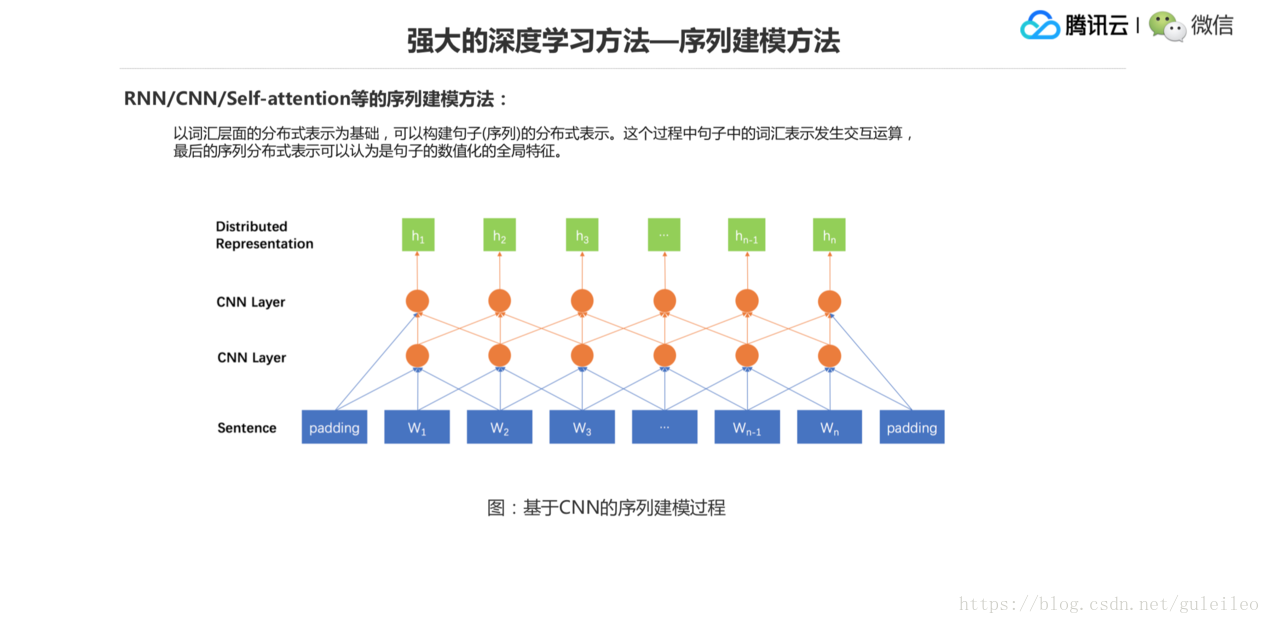
這是基於 CNN 的序列建模的一個方法,CNN 就是一個視窗,把一個詞通過不同的權重做加和,然後形成一個表示。第二層也是一個視窗,這樣一層層上去以後,越上面的一些 CNN 的結點它覆蓋的詞的範圍就越大。實際上到最上面這一層綠色的表示,也可以認為跟前面那個模型一樣,就是作為整個句子的一個特徵表示,然後結合後面的任務就好了。
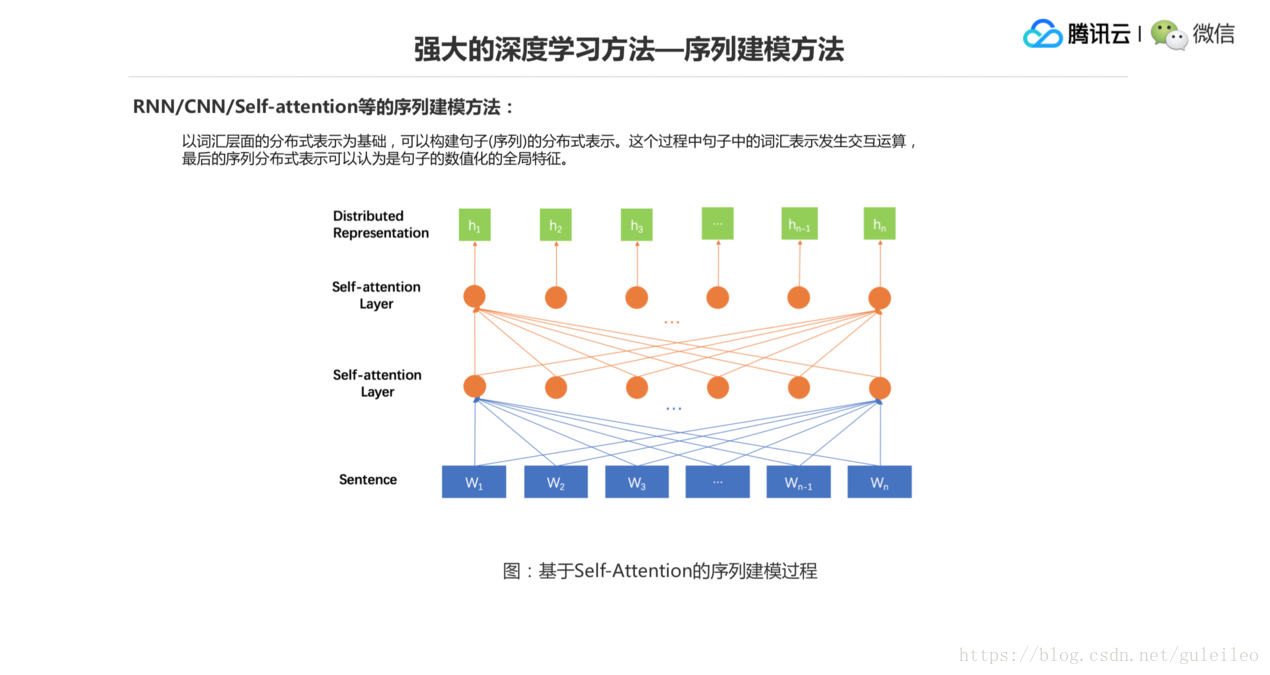
最近的工作有基於 Self-Attention 的這種序列建模方式,在 W1 生成 H1 的過程中它需要參考所有句子裡面的詞,然後計算和所有詞的一個相關程度,決定其他所有詞在最終形成它的表示的過程中所佔的權重比例。這個話有點繞,像前面的這些模型,W1 生成 H1 的時候,它可能只是一個區域性視窗,只考慮一個區域性範圍跟它互動的一些詞的範圍,在 Self-Attention 裡面,它要考慮跟它所有詞的關係,然後來構成最終的一個表示。
6.強大的深度學習方法—引數統一優化
第三個深度學習方法強大的一個優點就是引數統一優化的問題。之前我們說前面設計特徵模板,後面交一個分類器,更嚴重的就是搭一個系統的時候需要做很多步的模型搭建,比如傳統的統計機器翻譯裡面有一個短語模型的搭建流程,我有語料,先要做詞對齊,然後在詞對齊的結果上抽短語,抽完短語以後做短語特徵方面的抽取。

在短語這個層面還要學一個調序模型,在語料這個層面上其實還需要學一個語言模型,這些模型最後加一塊來融合,達到最後的模型,但實際上中間這些模型訓練的時候都是非常獨立的,有一些遞進的關係,然後就會出現一個錯誤傳播的問題,這些所有的引數並不是統計到一個優化目標函式下去訓練的。但深度學習方法裡,尤其 End-to-End 這個模型,就是能把所有的引數統一到一個優化目標函式下去緩解這種傳統的系統搭建方法的一個錯誤傳播的問題。這是一個基於統計的短語機器翻譯系統的一個搭建流程。
我們看一下基於神經網路的機器翻譯模型搭建的過程。下面有平行語料,就交到這個模型裡面去訓練,模型會有一個優化函式,最後能得到這個模型,整個模型來建模平行語料裡的翻譯知識。具體怎麼來做,後面我們會有更加詳細的介紹。這裡想表達的是深度學習方法,可以把所有的引數做統一優化。

我們來看一下前面提到自然語言處理中提到了三個問題模型,一個叫分類,一個叫序列標註,另一個叫序列生成。在傳統的方法下我們看過了它們是怎麼來做的。比如,前面做特徵模板設計,後面接分類器,像決策樹、SVM、LR 之類的分類器來做。那到了神經網路或者說深度學習時代,這個事情怎麼解決?其實底層還是基於特徵抽取的一個過程。
看這個圖,大家應該看到除了上面橙黃色的這個點,就是前面我們說的一個特徵抽取的過程,一個雙向 RNN 來抽取一定特徵的過程。對這個句子特徵抽取完了以後,接一個橙黃色的分類器,後面輸一個 Softmax,然後輸出哪個類別的概率,那就是用這種方法來建模一個分類的問題。
比如情感分析問題,或者說一個文字分類問題,你就把句子交到這個神經網路去,然後神經網路把特徵抽完了,後面接一個分類的過程,整個的優化都是基於上面這個分類的準確程度來做梯度回傳,回傳到每一條連線權重,還有詞向量上面去,所以整個系統它是一個模型,所有的引數同時在做優化,不存在特徵模板的問題,所以能夠很好地解決分類問題。
這是一個序列標註的問題,就是前面說到分詞的問題,給每一個字加一個合適的類標。其實下面還是一樣,抽特徵,抽出 N 個字的表示出來,就是這些字的特徵,後面每個接 Softmax 的分類器,然後做一個路徑最優的尋優操作做一個推理,找到一條最優的序列路徑出來。這是一個深度學習方法解決序列標註問題。
那怎麼來做序列生成的問題?就是 Encoder、Decoder,這是一個非常經典的模型。Encoder 就是把原先的句子做表示, Decoder 是根據這個表示來做生成。Encoder 也可以用 CNN、RNN、Self-Attention,Decoder 也可以分別用這三種。這個模型反映的是一個翻譯的過程,翻譯的過程是計算機可以處理自然語言,我們希望計算機能生成這個結果,也就是一個序列到另一個序列的對映,但是這兩個序列之間可能會存在著不同的長度。這是目前大家來做機器翻譯問題或者對話聊天裡的閒聊通用的一個模型。
7.深度學習方法的缺點
我們說說深度學習方法的缺點。一個缺點是模型的可解釋性低,首先它是一個數值的運算,你很難解釋它每一步的數值代表了什麼。整個過程在算,你很難去展現它中間語言學的一些推理過程,效果會很好,但是不好解釋,有人把它叫做黑盒。
再一個就是因為它都是基於數值的,所以就比較難去融入一些鮮豔符號的規則進來,這個語言學的知識或者人類的一些執行約束,很難去融入進來。再一個就是這個模型需要的計算量比較大,有很大權重矩陣的運算,矩陣乘法,或者做 Softmax 之類的這種計算,所以需要計算的還是比較重的,尤其是訓練大模型的時候,一般現在是用多顯示卡,最起碼是多卡,或者是多機來訓一個比較大的模型。
這個模型的表現除了依賴於本身的結構,它還依賴於比較多的訓練技巧,所謂的訓練技巧就是指中間某些引數的初始化方法,網路的超參設計,還要加一些其他東西,比如本身就給你一個 RNN,它其實可能表現不好,但加上很多訓練的方法進去,這個模型表現才會好起來。
所以有很多人說這是一個煉丹的過程,但是這個煉丹的過程到目前大家研究的也越來越透徹了,有很多分析的論文已經出來了,所以我們也希望這個模型可解釋性更好一點,這些訓練的技巧方法能夠在數學上找到更好的理論,然後拿實驗去驗證它,而不是說我們就真的是像煉丹師一樣去煉一個模型出來,這不是科學。
這章主要的內容就是介紹了自然語言處理裡面常用的一些問題模型和演算法模型,對比了統計機器學習方法和深度學習方法,然後分析了它們的優劣之處。
三、對話和機器翻譯中的深度學習模型和雲端應用
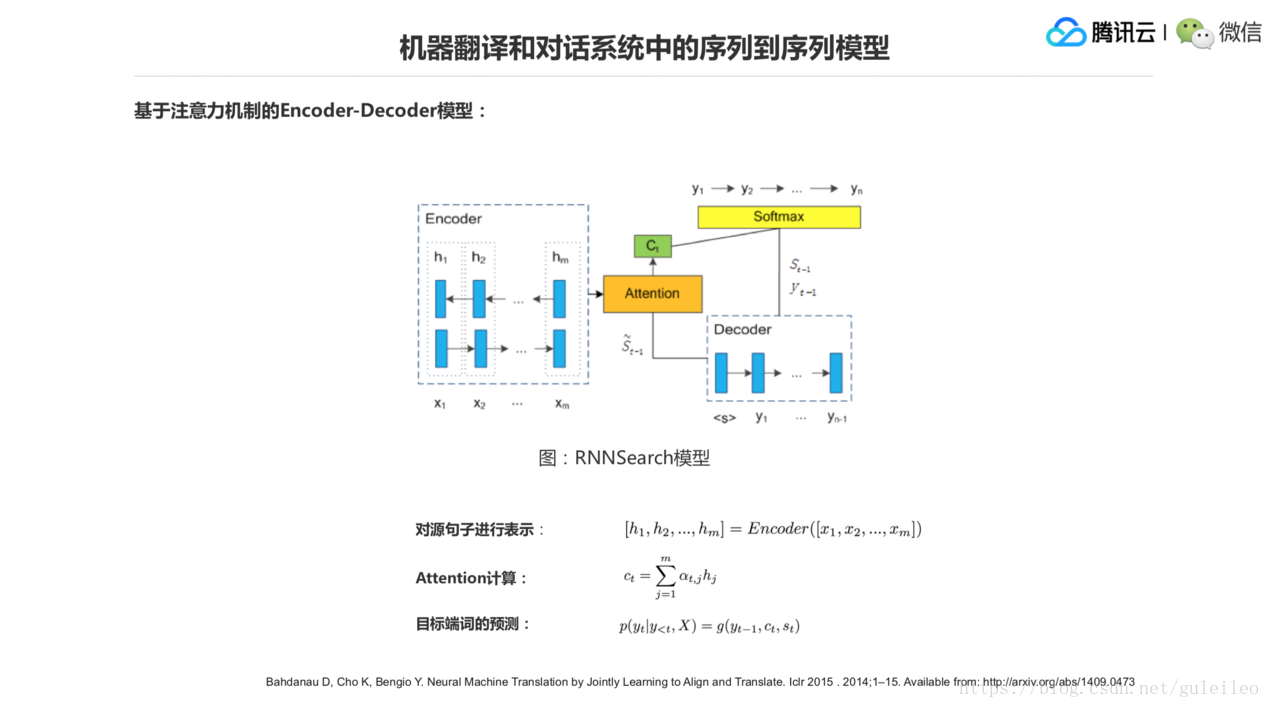
1.機器翻譯和對話系統中的序列到序列模型
前面我們說到了對話機器人和機器翻譯,這兩個問題其實差不多,對話機器人是一個單語的聊天,你說中文它給你回覆一箇中文。機器翻譯的過程其實是從一個語言到另外一個語言,它說“很高興認識你”,翻譯出來“Nice to meet you”,但兩個問題實際上都是序列到序列的問題。那麼機器翻譯模型和對話系統裡面的閒聊,它可以用一個通用模型,就是前面說的 Encoder 和 Decoder 來解決。
數學形式的話就是這樣,X 和 X1 到 Xm,Y 是 Y1 到 Yn,前面可以認為是 M 個詞或者 M 個字,這邊是 N 個詞或者 N 個字,建模就兩個序列之間的對映關係,就是第三個公式。只要把這個對映關係學到了,那麼就知道給定了 X1 到 Xm 的時候,我怎麼給出一個更好的 Y1 到 Yn,是一個更好的回覆或者更好的翻譯,這是一個序列到序列的問題模型。

前面我們已經看過這個模型了,它怎麼來生成這個 Y2?首先它要考慮源端的資訊,比如 X1 到Xm,它是一個語義。再一個就是它還要考慮到已經生成了什麼出來,因為它從 Y1 到 Yn,Yn 是逐個生成的。所以已經生成的序列加上源端的資訊或者主題的資訊,我們可以認為 X 是一個源端資訊或者主題資訊,然後經過一個分類器來預測下一個詞,下一個詞預測出來又到這兒來了,加到已經生成的序列後面,這個序列變長了,然後再預測下一個詞,直到預測出一個句子的終結符出來,這個序列的預測就算生成完成了,大概流程就是這樣,抽象的數學表示就是上面三個公式。

這個圖是一個比較經典的 Encoder-Decoder 結構,左邊是一個 Encoder,右邊是一個 Decoder,中間是一個 Attention 注意力機制。當 Decoder 其中一個詞的時候,比如說 Yt 這個詞的時候,去源端尋找跟它相關語義的時候,用一個 Attention 的形式,到底是 H1 扮演的權重大一些,還是 H2 扮演的權重大一些,還是 Hm 扮演的權重大一些,這是一個 Soft Attention 的過程。
這麼講其實有點泛,可以看公式,第三個公式,就是說我們來預測 Yt,Y 小於 t 了,我們知道了前面已經生成的 t-1 個詞, x 是整個源端的資訊,它需要參考一個 ct,ct 就是這個 Attention 完的一個結果。
前面剛生成完的一個 Decoder 頂層的一個狀態,它在算源端的一個相關程度的時候,用的就是中間這一項公式。這個地方歸比較繞,大家可以看一下公式。後面一個關於 Attention 機制的另外一個視角的看法,可能會更好理解一些。
還有一個是從檢索的視角來看 Attention 機制,實際上就是一個 query 的過程,有一個 query key,然後來檢索一個 Memory 的區域,實際上在上面的這個過程當中,拿前面這個 Decoder 的狀態,它作為 query 的 key 去查 Encoder 的 Memory,這個 Memory 長度是 m,寬度是源端的表示維度,大概是查每一塊對它的權重。我們做一個類比的話,知道計算機記憶體裡面去儲存,一般是有一個定位的過程,再一個就是儲存的一個過程。
不同的是這個定位是 soft 的定位,假如你有 10 個格子去訪問,不是說定位到第 3 個格子就讀第 3 個格子的資訊,而是要計算這 10 個格子裡面的內容,構成最後那個內容的一個權重。比如給第一個格子分了 0.1,第二個格子分了 0.2,第三個格子分 了0.3,依此類推,那到最後整個表示的時候,就是每個格子內容乘上它的權重,然後加起來。這可以認為是一個 query 的過程,檢索一個 Memory 的過程,不再是計算機硬體裡面這種硬性的 query,而是一個 soft 的 query。
這個 query 裡主要是存在著兩個 key 的運算,一個就是 query 可以和 Memory 裡面 key 的一個運算來計算相關程度。相關程度計算完以後,通過 softmax 做概率的規劃,然後把它轉到概率空間上面,再根據這個概率對每一個值做權重的加和,得到最後的 result,大家可以看這一塊的公式。relation 函式就是一個怎麼來衡量兩個東西關係的一個 relation 函式,一般可以用一個 BP 神經網路,就是一個前向網路來做。relation 函式有很多種選擇方式,但它的目的就是算 relation。
廣義的 Encoder-Decoder 框架現在用來做泛文字生成的一個問題,對話機器人、機器翻譯或者寫文章、寫詩、寫歌詞這種都可以用 Encoder-Decoder 來做。
對它做一個大概總結的話,Encoder-Decoder 就可以把裡面的構件隨便地替換掉,比如 Encoder 用 RNN,Decoder 用 CNN ,所以我們前面提到一個神經網路裡面構建的這些你完全可以在這個框架裡任意去替換,把它當做模組化的東西來使用。

Attention 的計算過程是基於加法或者基於乘法的,全域性的或者區域性的,再一個就是它其實可以融入更多的特徵進來。在這個框架裡融入更多的模組。不變的是 Encoder 就是對文字做表示的,Decoder 就是用來做生成的。前面說了泛文字生成的任務都可以基於該框架來做,所以它是一個非常經典的框架。
2.機器翻譯系統VS對話系統
現在來說機器翻譯系統和對話系統之間的區別,前面說都可以用序列到序列的模型來進行建模,但是區別在哪?首先是機器翻譯系統的訓練語料是一個句對,一個是源語言,一個是目標語言,它們在語義上具有一個非常強的一致性關係,是一個非常標準的序列到序列的任務。再一個就是可以通過大量的平行語料來覆蓋近乎全量的翻譯現象。
對話系統其實場景非常複雜,那就是源端句子和目標端句子並不是語義上的一致性,不是表達語義,而只是一個相關性或者一個回覆的關係,你說一句話,可能有上百種、上千種回覆關係,所以很難去拿語料去覆蓋對話場景,並且語料變大的時候,可能會因為回覆的多樣性導致知識衝突。再一個就是使用序列到序列的建模模型可以很方便地去搭建一個聊天機器人,就是你說一句話,它返回來給你一句話,看上去像在聊天,但是很難去搭一個實用的面向任務的對話系統,比如訂機票,更多的是說前面做意圖分析,後面再去具體地執行。
對話前面也說了,機器翻譯也需要知識庫,但是對話這個系統更需要知識庫,還有多媒體內容平臺,比如你要看電影,它需要有一個電影庫在後面支援,那就是對話系統和機器翻譯系統區別非常大的一個地方。
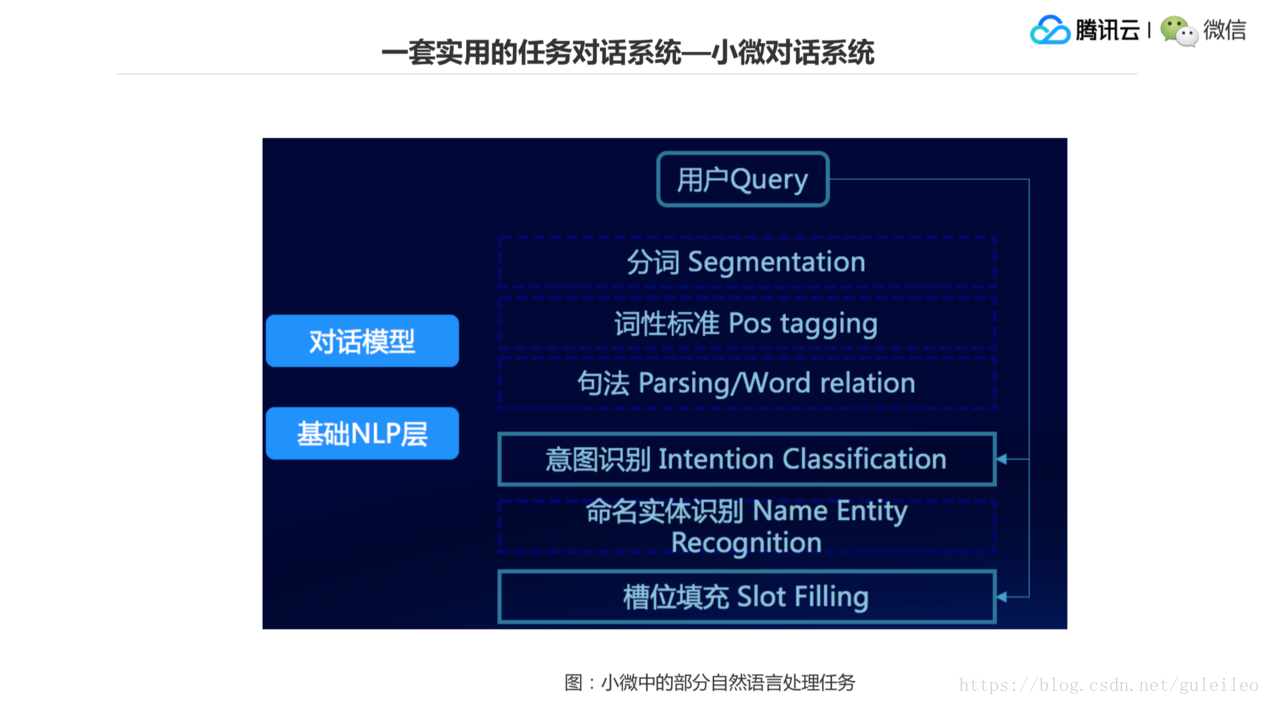
3.小微對話系統
介紹一下我們微信研發的一套小微對話系統,目前是搭載到了很多硬體上。裡面主要的 NLP 任務,大家看這個圖,會有分詞、詞性標註、Parsing,還有意圖識別、命名實體識別、槽位填充等 NLP 的任務都可以設計到這個系統裡,也就是我們前面說的構建一個產品級的自然語言處理系統,一定會涉及到多個層面,多種技術的使用,才最後拼起來這麼一個大的系統。

這個對話系統實際上在周邊還需要很多支援的系統,現在就是語音交付,前面就是一個語音識別,語音識別可以糾錯,然後放到這個對話系統裡面,對話系統可以返回一個語音合成的結果或者說一個螢幕展示的結果。所謂語音合成的結果是這樣,比如說你問對話系統明天的天氣怎麼樣,那麼它就直接給你一段語音就好了。
再一個就是螢幕展現,比如要看一個什麼電影,語音合成肯定不滿足你的需求了,那麼就是到螢幕展現了,電影就被調出來播放。微信裡面語音識別這個系統叫“智聆”,給它一個輸入,交到小微裡面去,小微做對話方面的計算,然後呈現使用者結果。
一些標杆的案例,一個是客服,對話系統可以來做客服,你問它一個問題,它返回相應的答案。再一個就是閒聊對話機器人,賢二機器僧是一個公眾號,你可以跟它去聊一些事情。還有就是車上的對話系統,比如讓它去導航、播放音樂、新聞之類的。還有就是外交部自動回覆的助手。再一個就是現在大家能接觸到的智慧音箱或者智慧機器人,基本上都要搭載這樣一套對話系統。一個對話系統可以搭載到不同的硬體上去,構成不同的一些應用場景。
四、開發者的技能進階建議
基礎篇,其實還是要基於很大量的數學知識,比如說線性代數、矩陣運算這一塊,整個神經網路所有的這個模型都是基於矩陣運算來做的,所以這一塊要熟悉。再一個就是概率論,統計模型是以概率為基礎的。還有就是高等數學,在神經網路或者深度學習技術裡面用到的就是函式、導數、級數、公式推導這些,在數學模型統計方法裡面,這些都是基礎的基礎,非常重要。
第二個建議是熟練使用一種深度學習的平臺,現在 Python 基本上成了人工智慧的一種流程型的語言,大家可以去熟練地掌握,還有其他的深度學習平臺,像 TensorFlow 這種,能夠讓你非常方便地來搭建神經網路模型,不用再去關注非常底層的一些運算。
推薦一些公開課,像 Chris Manning,自然語言處理或者 Standford 裡面的 Deep Learning 課程,還有 Coursera 裡面的一些自然語言處理課程,大家都可以看一下。還有一些非常好的資源,大家可以去聽別人講,然後接觸基礎資料,去入門。
進階篇,進階篇去研讀一下現在優秀的一些深度學習的活動,像 Word2Vec 這種大家用得都非常多的。再複雜一點的,像 GNMT,就是谷歌開源出來的一套神經網路的程式碼。然後 Tensor2Tensor,大家在看的時候,一方面可以去學習模型,另一方面可以學習深度學習平臺的使用方法。也就是讀別人的程式碼,可以學到很多東西。再一個就是培養問題建模的能力,就是說要對問題和模型比較熟悉,給你一個問題大概能判斷出它大概用哪個模型去解決會好一點。再一個模型實現,就是你能把它實現出來,跑出實驗結果出來,就要效能分析、調優,然後加一些訓練方法進去,能夠很好地實現任務。
創新篇,這是更高階段的一個目標。要去研究最新的方法,要讀論文,對這個領域的研究現狀和方法都有一個比較清晰的認識,看透問題的本質大概是怎樣的,然後嘗試提出自己的觀點和創新性的解決方法,能拿合理的實驗方法去驗證。
五、答聽眾問
Q:中文分詞和深度學習的演算法相比差距有多少?還需要學習傳統演算法嗎?
A:我讀博前兩年做了分詞相關的研究,用深度學習方法做過,也用統計的方法做過。那實際上在一個標準的語料上,就是有一個標準的任務,比如在 3 萬個句子上做訓練,在幾百個句子上做分詞的話,神經網路的方法在表現上面並不具備比傳統方法特別好的一個表現,但在標準的任務上,神經網路方法一個好處是它不需要設計特徵模板。
Q:序列化標註模型有什麼成熟的模型?
A:其實有很多很成熟的模型和工具,問題模型就是序列標註問題,模型有 CRF 或者 MEMM等,這些都有一些開源的包,你就直接拿著它然後搞一下特徵,輸進去,就可以訓練了,都是非常成熟的,神經網路也可以做序列標註任務。
Q:有監督和無監督方法哪個更有優勢或者兩者區別,可以具體說個例子嗎?
A:有監督方法和無監督方法的應用場景不一樣。目前自然語言處理任務在產品當中應用的難點,一個就是有限的標註資料,要完成很多工,先是要去標註資料,需要的人力成本比較高,人與人之間的標註資料也會存在一些不一致性,並且針對某一個具體任務標註的資料它很難遷移到其他任務上去使用,所以這個有監督的方法還是比較侷限,成本比較高。
無監督方法就想解決這個問題,就是怎麼把這個成本降下來,但問題是無監督的方法現在的效果不太好,因為無監督確實知識很少,離應用也會更差一些,但是無監督是一個非常值得研究的問題,如果真的哪天這個問題能夠很好地解決,不再需要標資料的方式,那麼無監督方法就可以通用了。
—【完】—