
Python爬蟲--使用cookies登入豆瓣網
阿新 • • 發佈:2019-01-26
用python做網路爬蟲時,有時需要登入某些網站。
例如使用requests請求登入豆瓣網的時候需要輸入使用者密碼,可能還需要輸入驗證碼,比較麻煩。
現在在請求豆瓣網連結www.douban.com的時候,使用post加上cookies,可以不用輸入賬號和密碼直接登入。
方法如下:
開啟瀏覽器,開啟豆瓣的主頁,按下鍵盤上的F12鍵(開啟瀏覽器的開發者工具),此時輸入賬號和密碼登入豆瓣網。檢視開發者工具中請求登入時的cookies資訊,如圖:
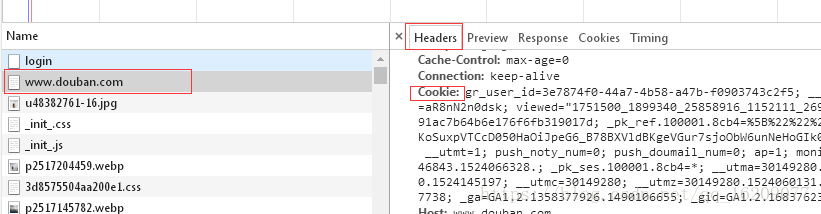
把右側Cookies對應的內容儲存下來。
下面使用python程式登入豆瓣:
import requests
headers = {'User-Agent' 檢視douban.txt檔案,如果檔案中”xxx的帳號”, xxx是你豆瓣的賬號名,即為登入成功。