
Spark運算元使用示例
1. 運算元分類
從大方向來說,Spark 運算元大致可以分為以下兩類
- Transformation:操作是延遲計算的,也就是說從一個RDD 轉換生成另一個 RDD 的轉換操作不是馬上執行,需要等到有 Action 操作的時候才會真正觸發運算。
- Action:會觸發 Spark 提交作業(Job),並將資料輸出 Spark系統。
從小方向來說,Spark 運算元大致可以分為以下三類:
- Value資料型別的Transformation運算元。
- Key-Value資料型別的Transfromation運算元。
- Action運算元
1.1 Value資料型別的Transformation運算元
| 型別 | 運算元 |
|---|---|
| 輸入分割槽與輸出分割槽一對一型 | map、flatMap、mapPartitions、glom |
| 輸入分割槽與輸出分割槽多對一型 | union、cartesian |
| 輸入分割槽與輸出分割槽多對多型 | groupBy |
| 輸出分割槽為輸入分割槽子集型 | filter、distinct、subtract、sample、takeSample |
| Cache型 | cache、persist |
1.2 Key-Value資料型別的Transfromation運算元
| 型別 | 運算元 |
|---|---|
| 輸入分割槽與輸出分割槽一對一 | mapValues |
| 對單個RDD | combineByKey、reduceByKey、partitionBy |
| 兩個RDD聚集 | Cogroup |
| 連線 | join、leftOutJoin、rightOutJoin |
1.3 Action運算元
| 型別 | 運算元 |
|---|---|
| 無輸出 | foreach |
| HDFS | saveAsTextFile、saveAsObjectFile |
| Scala集合和資料型別 | collect、collectAsMap、reduceByKeyLocally、lookup、count、top、reduce、fold、aggregate |
2. Transformation
2.1 map
2.1.1 概述
語法(scala):
def map[U: ClassTag](f: T => U): RDD[U]說明:
將原來RDD的每個資料項通過map中的使用者自定義函式f對映轉變為一個新的元素
2.1.2 Java示例
/**
* map運算元
* <p>
* map和foreach運算元:
* 1. 迴圈map呼叫元的每一個元素;
* 2. 執行call函式, 並返回.
* </p>
*/
private static void map() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> datas = Arrays.asList(
"{'id':1,'name':'xl1','pwd':'xl123','sex':2}",
"{'id':2,'name':'xl2','pwd':'xl123','sex':1}",
"{'id':3,'name':'xl3','pwd':'xl123','sex':2}");
JavaRDD<String> datasRDD = sc.parallelize(datas);
JavaRDD<User> mapRDD = datasRDD.map(
new Function<String, User>() {
public User call(String v) throws Exception {
Gson gson = new Gson();
return gson.fromJson(v, User.class);
}
});
mapRDD.foreach(new VoidFunction<User>() {
public void call(User user) throws Exception {
System.out.println("id: " + user.id
+ " name: " + user.name
+ " pwd: " + user.pwd
+ " sex:" + user.sex);
}
});
sc.close();
}
// 結果
id: 1 name: xl1 pwd: xl123 sex:2
id: 2 name: xl2 pwd: xl123 sex:1
id: 3 name: xl3 pwd: xl123 sex:22.1.3 Scala示例
private def map() {
val conf = new SparkConf().setAppName(ScalaOperatorDemo.getClass.getSimpleName).setMaster("local")
val sc = new SparkContext(conf)
val datas: Array[String] = Array(
"{'id':1,'name':'xl1','pwd':'xl123','sex':2}",
"{'id':2,'name':'xl2','pwd':'xl123','sex':1}",
"{'id':3,'name':'xl3','pwd':'xl123','sex':2}")
sc.parallelize(datas)
.map(v => {
new Gson().fromJson(v, classOf[User])
})
.foreach(user => {
println("id: " + user.id
+ " name: " + user.name
+ " pwd: " + user.pwd
+ " sex:" + user.sex)
})
}2.2 filter
2.2.1 概述
語法(scala):
def filter(f: T => Boolean): RDD[T]說明:
對元素進行過濾,對每個元素應用f函式,返回值為true的元素在RDD中保留,返回為false的將過濾掉
2.2.2 Java示例
static void filter() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> datas = Arrays.asList(1, 2, 3, 7, 4, 5, 8);
JavaRDD<Integer> rddData = sc.parallelize(datas);
JavaRDD<Integer> filterRDD = rddData.filter(
// jdk1.8
// v1 -> v1 >= 3
new Function<Integer, Boolean>() {
public Boolean call(Integer v) throws Exception {
return v >= 3;
}
}
);
filterRDD.foreach(
// jdk1.8
// v -> System.out.println(v)
new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
System.out.println(integer);
}
}
);
sc.close();
}
// 結果
3
7
4
5
82.2.3 Scala示例
def filter {
val conf = new SparkConf().setAppName(ScalaOperatorDemo.getClass.getSimpleName).setMaster("local")
val sc = new SparkContext(conf)
val datas = Array(1, 2, 3, 7, 4, 5, 8)
sc.parallelize(datas)
.filter(v => v >= 3)
.foreach(println)
}2.3 flatMap
2.3.1 簡述
語法(scala):
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]說明:
與map類似,但每個輸入的RDD成員可以產生0或多個輸出成員
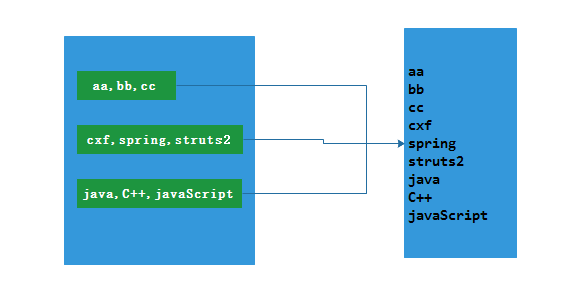
2.3.2 Java示例
static void flatMap() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> data = Arrays.asList(
"aa,bb,cc",
"cxf,spring,struts2",
"java,C++,javaScript");
JavaRDD<String> rddData = sc.parallelize(data);
JavaRDD<String> flatMapData = rddData.flatMap(
v -> Arrays.asList(v.split(",")).iterator()
// new FlatMapFunction<String, String>() {
// @Override
// public Iterator<String> call(String t) throws Exception {
// List<String> list= Arrays.asList(t.split(","));
// return list.iterator();
// }
// }
);
flatMapData.foreach(v -> System.out.println(v));
sc.close();
}
// 結果
aa
bb
cc
cxf
spring
struts2
java
C++
javaScript2.3.3 Scala示例
sc.parallelize(datas)
.flatMap(line => line.split(","))
.foreach(println)2.4 mapPartitions
2.4.1 概述
語法(scala):
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]說明:
與Map類似,但map中的func作用的是RDD中的每個元素,而mapPartitions中的func作用的物件是RDD的一整個分割槽。所以func的型別是
Iterator<T> => Iterator<U>,其中T是輸入RDD元素的型別。preservesPartitioning表示是否保留輸入函式的partitioner,預設false。
2.4.2 Java示例
static void mapPartitions() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> names = Arrays.asList("張三1", "李四1", "王五1", "張三2", "李四2",
"王五2", "張三3", "李四3", "王五3", "張三4");
JavaRDD<String> namesRDD = sc.parallelize(names, 3);
JavaRDD<String> mapPartitionsRDD = namesRDD.mapPartitions(
new FlatMapFunction<Iterator<String>, String>() {
int count = 0;
@Override
public Iterator<String> call(Iterator<String> stringIterator) throws Exception {
List<String> list = new ArrayList<String>();
while (stringIterator.hasNext()) {
list.add("分割槽索引:" + count++ + "\t" + stringIterator.next());
}
return list.iterator();
}
}
);
// 從叢集獲取資料到本地記憶體中
List<String> result = mapPartitionsRDD.collect();
result.forEach(System.out::println);
sc.close();
}
// 結果
分割槽索引:0 張三1
分割槽索引:1 李四1
分割槽索引:2 王五1
分割槽索引:0 張三2
分割槽索引:1 李四2
分割槽索引:2 王五2
分割槽索引:0 張三3
分割槽索引:1 李四3
分割槽索引:2 王五3
分割槽索引:3 張三42.4.3 Scala示例
sc.parallelize(datas, 3)
.mapPartitions(
n => {
val result = ArrayBuffer[String]()
while (n.hasNext) {
result.append(n.next())
}
result.iterator
}
)
.foreach(println)2.5 mapPartitionsWithIndex
2.5.1 概述
語法(scala):
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]說明:
與mapPartitions類似,但輸入會多提供一個整數表示分割槽的編號,所以func的型別是
(Int, Iterator<T>) => Iterator<R>,多了一個Int
2.5.2 Java示例
private static void mapPartitionsWithIndex() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> names = Arrays.asList("張三1", "李四1", "王五1", "張三2", "李四2",
"王五2", "張三3", "李四3", "王五3", "張三4");
// 初始化,分為3個分割槽
JavaRDD<String> namesRDD = sc.parallelize(names, 3);
JavaRDD<String> mapPartitionsWithIndexRDD = namesRDD.mapPartitionsWithIndex(
new Function2<Integer, Iterator<String>, Iterator<String>>() {
private static final long serialVersionUID = 1L;
public Iterator<String> call(Integer v1, Iterator<String> v2) throws Exception {
List<String> list = new ArrayList<String>();
while (v2.hasNext()) {
list.add("分割槽索引:" + v1 + "\t" + v2.next());
}
return list.iterator();
}
},
true);
// 從叢集獲取資料到本地記憶體中
List<String> result = mapPartitionsWithIndexRDD.collect();
result.forEach(System.out::println);
sc.close();
}
// 結果
分割槽索引:0 張三1
分割槽索引:0 李四1
分割槽索引:0 王五1
分割槽索引:1 張三2
分割槽索引:1 李四2
分割槽索引:1 王五2
分割槽索引:2 張三3
分割槽索引:2 李四3
分割槽索引:2 王五3
分割槽索引:2 張三42.5.3 Scala示例
sc.parallelize(datas, 3)
.mapPartitionsWithIndex(
(m, n) => {
val result = ArrayBuffer[String]()
while (n.hasNext) {
result.append("分割槽索引:" + m + "\t" + n.next())
}
result.iterator
}
)
.foreach(println)2.6 sample
2.6.1 概述
語法(scala):
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]說明:
對RDD進行抽樣,其中引數withReplacement為true時表示抽樣之後還放回,可以被多次抽樣,false表示不放回;fraction表示抽樣比例;seed為隨機數種子,比如當前時間戳
2.6.2 Java示例
static void sample() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> datas = Arrays.asList(1, 2, 3, 7, 4, 5, 8);
JavaRDD<Integer> dataRDD = sc.parallelize(datas);
JavaRDD<Integer> sampleRDD = dataRDD.sample(false, 0.5, System.currentTimeMillis());
sampleRDD.foreach(v -> System.out.println(v));
sc.close();
}
// 結果
7
4
52.6.3 Scala示例
sc.parallelize(datas)
.sample(withReplacement = false, 0.5, System.currentTimeMillis)
.foreach(println)2.7 union
2.7.1 概述
語法(scala):
def union(other: RDD[T]): RDD[T]說明:
合併兩個RDD,不去重,要求兩個RDD中的元素型別一致
2.7.2 Java示例
static void union() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> datas1 = Arrays.asList("張三", "李四");
List<String> datas2 = Arrays.asList("tom", "gim");
JavaRDD<String> data1RDD = sc.parallelize(datas1);
JavaRDD<String> data2RDD = sc.parallelize(datas2);
JavaRDD<String> unionRDD = data1RDD
.union(data2RDD);
unionRDD.foreach(v -> System.out.println(v));
sc.close();
}
// 結果
張三
李四
tom
gim2.7.3 Scala示例
// sc.parallelize(datas1)
// .union(sc.parallelize(datas2))
// .foreach(println)
// 或
(sc.parallelize(datas1) ++ sc.parallelize(datas2))
.foreach(println)2.8 intersection
2.8.1 概述
語法(scala):
def intersection(other: RDD[T]): RDD[T]說明:
返回兩個RDD的交集
2.8.2 Java示例
static void intersection(JavaSparkContext sc) {
List<String> datas1 = Arrays.asList("張三", "李四", "tom");
List<String> datas2 = Arrays.asList("tom", "gim");
sc.parallelize(datas1)
.intersection(sc.parallelize(datas2))
.foreach(v -> System.out.println(v));
}
// 結果
tom2.8.3 Scala示例
sc.parallelize(datas1)
.intersection(sc.parallelize(datas2))
.foreach(println)2.9 distinct
2.9.1 概述
語法(scala):
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
def distinct(): RDD[T]說明:
對原RDD進行去重操作,返回RDD中沒有重複的成員
2.9.2 Java示例
static void distinct(JavaSparkContext sc) {
List<String> datas = Arrays.asList("張三", "李四", "tom", "張三");
sc.parallelize(datas)
.distinct()
.foreach(v -> System.out.println(v));
}
// 結果
張三
tom
李四2.9.3 Scala示例
sc.parallelize(datas)
.distinct()
.foreach(println)2.10 groupByKey
2.10.1 概述
語法(scala):
# RDD類中
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
def groupBy[K](
f: T => K,
numPartitions: Int)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
def groupBy[K](f: T => K, p: Partitioner)(implicit kt: ClassTag[K], ord: Ordering[K] = null)
: RDD[(K, Iterable[T])]
# PairRDDFunctions類中
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(): RDD[(K, Iterable[V])]說明:
對
<key, value>結構的RDD進行類似RMDB的group by聚合操作,具有相同key的RDD成員的value會被聚合在一起,返回的RDD的結構是(key, Iterator<value>)
2.10.2 Java示例
static void groupBy(JavaSparkContext sc) {
List<Integer> datas = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
sc.parallelize(datas)
.groupBy(new Function<Integer, Object>() {
@Override
public Object call(Integer v1) throws Exception {
return (v1 % 2 == 0) ? "偶數" : "奇數";
}
})
.collect()
.forEach(System.out::println);
List<String> datas2 = Arrays.asList("dog", "tiger", "lion", "cat", "spider", "eagle");
sc.parallelize(datas2)
.keyBy(v1 -> v1.length())
.groupByKey()
.collect()
.forEach(System.out::println);
}
// 結果
(奇數,[1, 3, 5, 7, 9])
(偶數,[2, 4, 6, 8])
(4,[lion])
(6,[spider])
(3,[dog, cat])
(5,[tiger, eagle])2.10.3 Scala示例
def groupBy(sc: SparkContext): Unit = {
sc.parallelize(1 to 9, 3)
.groupBy(x => {
if (x % 2 == 0) "偶數"
else "奇數"
})
.collect()
.foreach(println)
val datas2 = Array("dog", "tiger", "lion", "cat", "spider", "eagle")
sc.parallelize(datas2)
.keyBy(_.length)
.groupByKey()
.collect()
.foreach(println)
}2.11 reduceByKey
2.11.1 概述
語法(scala):
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(func: (V, V) => V): RDD[(K, V)]說明:
對
<key, value>結構的RDD進行聚合,對具有相同key的value呼叫func來進行reduce操作,func的型別必須是(V, V) => V
2.11.2 Java示例
static void reduceByKey(JavaSparkContext sc) {
JavaRDD<String> lines = sc.textFile("file:///Users/zhangws/opt/spark-2.0.1-bin-hadoop2.6/README.md");
JavaRDD<String> wordsRDD = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
public Iterator<String> call(String line) throws Exception {
List<String> words = Arrays.asList(line.split(" "));
return words.iterator();
}
});
JavaPairRDD<String, Integer> wordsCount = wordsRDD.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> resultRDD = wordsCount.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
resultRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
private static final long serialVersionUID = 1L;
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1 + "\t" + t._2());
}
});
sc.close();
}
// 結果
package 1
For 3
Programs 1
(略)2.11.3 Scala示例
val textFile = sc.textFile("file:///home/zkpk/spark-2.0.1/README.md")
val words = textFile.flatMap(line => line.split(" "))
val wordPairs = words.map(word => (word, 1))
val wordCounts = wordPairs.reduceByKey((a, b) => a + b)
println("wordCounts: ")
wordCounts.collect().foreach(println)2.12 aggregateByKey
2.12.1 概述
語法(java):
<U> JavaPairRDD<K,U> aggregateByKey(U zeroValue,
Partitioner partitioner,
Function2<U,V,U> seqFunc,
Function2<U,U,U> combFunc)
<U> JavaPairRDD<K,U> aggregateByKey(U zeroValue,
int numPartitions,
Function2<U,V,U> seqFunc,
Function2<U,U,U> combFunc)
<U> JavaPairRDD<K,U> aggregateByKey(U zeroValue,
Function2<U,V,U> seqFunc,
Function2<U,U,U> combFunc)說明:
aggregateByKey函式對PairRDD中相同Key的值進行聚合操作,在聚合過程中同樣使用了一箇中立的初始值。和aggregate函式類似,aggregateByKey返回值得型別不需要和RDD中value的型別一致。因為aggregateByKey是對相同Key中的值進行聚合操作,所以aggregateByKey函式最終返回的型別還是Pair RDD,對應的結果是Key和聚合好的值;而aggregate函式直接返回非RDD的結果。
引數:
- zeroValue:表示在每個分割槽中第一次拿到key值時,用於建立一個返回型別的函式,這個函式最終會被包裝成先生成一個返回型別,然後通過呼叫seqOp函式,把第一個key對應的value新增到這個型別U的變數中。
- seqOp:這個用於把迭代分割槽中key對應的值新增到zeroValue建立的U型別例項中。
- combOp:這個用於合併每個分割槽中聚合過來的兩個U型別的值。
2.12.2 Java示例
static void aggregateByKey(JavaSparkContext sc) {
List<Tuple2<Integer, Integer>> datas = new ArrayList<>();
datas.add(new Tuple2<>(1, 3));
datas.add(new Tuple2<>(1, 2));
datas.add(new Tuple2<>(1, 4));
datas.add(new Tuple2<>(2, 3));
sc.parallelizePairs(datas, 2)
.aggregateByKey(
0,
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("seq: " + v1 + "\t" + v2);
return Math.max(v1, v2);
}
},
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("comb: " + v1 + "\t" + v2);
return v1 + v2;
}
})
.collect()
.forEach(System.out::println);
}2.12.3 Scala示例
def aggregateByKey(sc: SparkContext): Unit = {
// 合併在同一個partition中的值,a的資料型別為zeroValue的資料型別,b的資料型別為原value的資料型別
def seq(a:Int, b:Int): Int = {
println("seq: " + a + "\t" + b)
math.max(a, b)
}
// 合併在不同partition中的值,a,b的資料型別為zeroValue的資料型別
def comb(a:Int, b:Int): Int = {
println("comb: " + a + "\t" + b)
a + b
}
// 資料拆分成兩個分割槽
// 分割槽一資料: (1,3) (1,2)
// 分割槽二資料: (1,4) (2,3)
// zeroValue 中立值,定義返回value的型別,並參與運算
// seqOp 用來在一個partition中合併值的
// 分割槽一相同key的資料進行合併
// seq: 0 3 (1,3)開始和中位值合併為3
// seq: 3 2 (1,2)再次合併為3
// 分割槽二相同key的資料進行合併
// seq: 0 4 (1,4)開始和中位值合併為4
// seq: 0 3 (2,3)開始和中位值合併為3
// comb 用來在不同partition中合併值的
// 將兩個分割槽的結果進行合併
// key為1的, 兩個分割槽都有, 合併為(1,7)
// key為2的, 只有一個分割槽有, 不需要合併(2,3)
sc.parallelize(List((1, 3), (1, 2), (1, 4), (2, 3)), 2)
.aggregateByKey(0)(seq, comb)
.collect()
.foreach(println)
}
// 結果
(2,3)
(1,7)2.13 sortByKey
2.13.1 概述
語法(java):
JavaRDD<T> sortBy(Function<T,S> f,
boolean ascending,
int numPartitions)
JavaPairRDD<K,V> sortByKey()
JavaPairRDD<K,V> sortByKey(boolean ascending)
JavaPairRDD<K,V> sortByKey(boolean ascending,
int numPartitions)
JavaPairRDD<K,V> sortByKey(java.util.Comparator<K> comp)
JavaPairRDD<K,V> sortByKey(java.util.Comparator<K> comp,
boolean ascending)
JavaPairRDD<K,V> sortByKey(java.util.Comparator<K> comp,
boolean ascending,
int numPartitions)說明:
對
<key, value>結構的RDD進行升序或降序排列
引數:
- comp:排序時的比較運算方式。
- ascending:false降序;true升序。
2.13.2 Java示例
static void sortByKey(JavaSparkContext sc) {
List<Integer> datas = Arrays.asList(60, 70, 80, 55, 45, 75);
// sc.parallelize(datas)
// .sortBy(new Function<Integer, Object>() {
// @Override
// public Object call(Integer v1) throws Exception {
// return v1;
// }
// }, true, 1)
// .foreach(v -> System.out.println(v));
sc.parallelize(datas)
.sortBy((Integer v1) -> v1, false, 1)
.foreach(v -> System.out.println(v));
List<Tuple2<Integer, Integer>> datas2 = new ArrayList<>();
datas2.add(new Tuple2<>(3, 3));
datas2.add(new Tuple2<>(2, 2));
datas2.add(new Tuple2<>(1, 4));
datas2.add(new Tuple2<>(2, 3));
sc.parallelizePairs(datas2)
.sortByKey(false)
.foreach(v -> System.out.println(v));
}
// 結果
80
75
70
60
55
45
(3,3)
(2,2)
(2,3)
(1,4)2.13.3 Scala示例
def sortByKey(sc: SparkContext) : Unit = {
sc.parallelize(Array(60, 70,