
趟過spark的坑
坑一:
使用idea使用
setMaster("local[4]")
模式執行寫好的程式碼沒有問題,一旦使用
setMaster("spark://192.168.160.112:8090")
這種方式就會報classnotfound的錯誤,如下圖,下例中使用了elasticsearch的驅動
[[email protected] estest_jar]# spark-submit --class EStest --master spark://192.168.160.135:7077 --name estest estest.jar
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/12/15 16:06:26 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/15 16:06:28 WARN SparkContext: Using an existing SparkContext; some configuration may not take effect.
17/12/15 16:06:31 INFO Version: Elasticsearch Hadoop v6.0.0 [8b59a8f82d]
17/12/15 16:06:31 INFO ScalaEsRDD: Reading from [bank2]
[Stage 0:> (0 + 0) / 5]17/12/15 16:06:31 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, 192.168.160.135, executor 0): java.lang.ClassNotFoundException: org.elasticsearch.spark.rdd.EsPartition
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
解決方案分為2種:1.在寫程式碼的時候,直接指明使用jar檔案的路徑
var jars=Seq("/home/javajars/elasticsearch-spark-20_2.11-6.0.0.jar","/home/javajars/postgresql-42.1.4.jar") val conf = new SparkConf().setAppName("estest").setMaster("spark://192.168.160.135:7077").setJars(jars) conf.set("es.nodes", "192.168.160.135") conf.set("es.port", "9200")
2.通過分析spark-worker的log發現,spark工作時只使用sparkhome/jars下的jar檔案
log片段如下:紅色部分是spark工作時使用的jar檔案
17/12/15 00:06:27 INFO ExecutorRunner: Launch command: "/root/Downloads/jdk/bin/java" "-cp" "/spark/conf/:/spark/jars/*" "-Xmx1024M" "-Dspark.driver.port=33208" "org.apache.spark.executor.CoarseGrainedExecutorBackend" "--driver-url" "spark://[email protected]:33208" "--executor-id" "0" "--hostname" "192.168.160.135" "--cores" "2" "--app-id" "app-20171215000627-0012" "--worker-url" "spark://[email protected]:33341"
只要將所需的jar檔案拷貝到sparkhome/jars下即可,叢集模式我也是在每一個slave的sparkhome/jars下添加了jar檔案坑二:
在提交打好的jar檔案時報錯找不到--class引數指定的類,報錯如下:
[[email protected] estest_jar]# spark-submit --class EStest --master spark://192.168.160.135:7077 --name estest estest.jar
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/12/14 21:28:45 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/14 21:28:46 WARN SparkContext: Using an existing SparkContext; some configuration may not take effect.
17/12/14 21:28:47 INFO Version: Elasticsearch Hadoop v6.0.0 [8b59a8f82d]
17/12/14 21:28:47 INFO ScalaEsRDD: Reading from [bank2]
17/12/14 21:28:49 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, 192.168.160.135, executor 0): java.lang.ClassNotFoundException: EStest$$anonfun$1
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
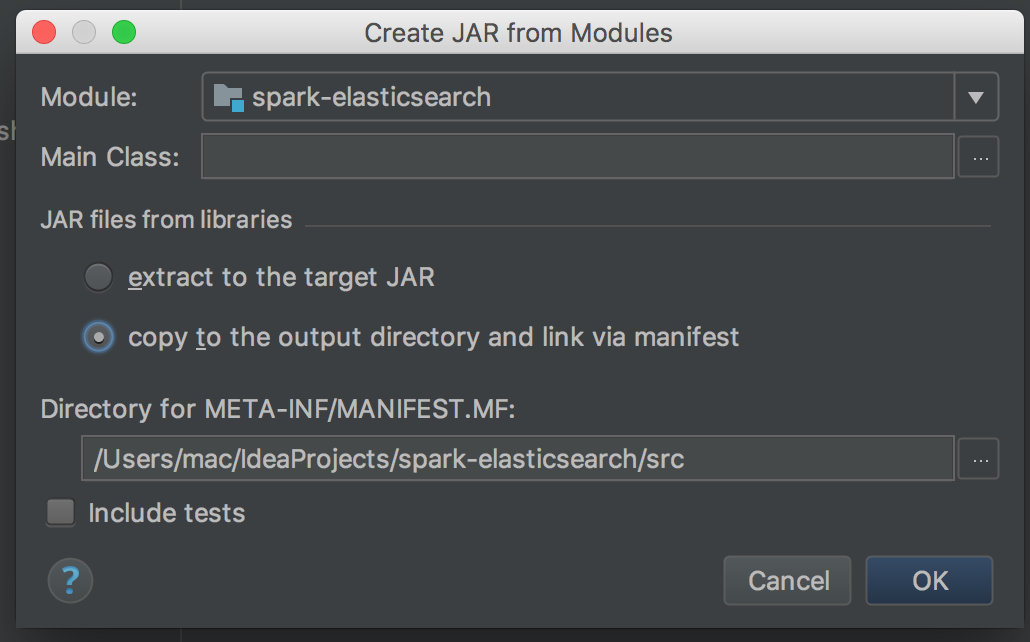
解決方法和坑一類似,一個是吧你打好的jar檔案也包含在程式碼裡,紅色部分是我自己打的jar檔案,包含在自己的程式碼裡。。。。。(自己要證明自己是自己的感覺)var jars=Seq("/root/Downloads/jar/elasticsearch-spark-20_2.11-6.0.0.jar","/root/IdeaProjects/EStest/out/artifacts/estest_jar/estest.jar") val conf = new SparkConf().setAppName("estest").setMaster("spark://192.168.160.135:7077") conf.set("es.nodes", "192.168.160.135") conf.set("es.port", "9200")還有一種 估計直接把jar檔案打到sparkhome/jars下估計也可行。 坑三: idea打jar包 首先打jar包的方式最好是不包含引用的其他jar檔案,選擇copy to output direc......那個選項。
相關推薦
趟過spark的坑
坑一: 使用idea使用 setMaster("local[4]") 模式執行寫好的程式碼沒有問題,一旦使用 setMaster("spark://192.168.160.112:8090") 這種方式就會報classnotfound的錯誤,如下圖,下例中使用了el
ExtJS 折線圖趟過的坑
繪制 source cal func rebar sda ace .cn move 問題: 1、根據條件檢索後繪制折線圖,之前的坐標沒有清除如圖 解決方案: 在繪制之前,清空坐票: leftLine.surface.removeAll(); leftLine.redraw
微信支付趟過的坑
這段時間在做微信支付開發,在公司的公眾號審批下來後,我這邊的測試用例也已經開發完畢,於是拿著具體的資料來除錯了,大段大段的程式碼就不貼了,demo裡有,這裡就說說除錯過程中遇到的坑。
那些年趟過的坑—log4j和slf4j-api衝突Maven版
slf4j-api-1.6.6.jar slf4j-log4j12-1.7.5.jar slf4j-simple-1.7.7.jar 在使用到log4j和slf4j的同時slf4j-api-1.6.6.jar依賴的兩個jar包也必須同時依賴,故加入以下依賴即可: &l
django 趟過的坑。。
django使用models讀取資料庫的資訊時: requirement是我定義的一個model r=requirement.objects.filter(id=1) print(type(r)) print(r)結果是<class 'django.db.m
記一次Win10環境python3.7安裝dlib模組趟過的坑
在頭條看了一篇文章,說五行程式碼實現人臉識別,一時感興趣了,來搞搞 先是按照文章說的 操作了幾步,到後面雖然,import dlib 不報錯,但是 程式碼裡面執行的時候 detector = dlib.get_frontal_face_detector() 這句話報錯,說
關於android WebView我趟過的坑!
最近發現偶爾還是會踩到以前踩過的坑,所以開始了我的部落格之旅,自己備忘,也可以將這些坑分享出來,幫助大家快速解決問題: 1. ## webview記憶體洩露 -異常加日誌截圖 ## Activity com.dejia.demo.webview.WebVi
spring-boot-start-data-redis-reactive包使用趟過的坑
[2019-01-10 11:05:03] [INFO ] [io.lettuce.core.protocol.ConnectionWatchdog:106]-- Reconnecting, last destination was host/ip:port [2019-01-10 11:05:03]
Unity接安卓微信SDK所趟過的坑
今天使用eclipse接微信sdk,作為一個小白。過程實在坎坷,也深知各位新手和我一樣趟坑時的艱辛與無奈。現把接微信安卓SDK的經驗以及注意事提示如下,大家可以根據這個百度。 1、unity中匯入安卓的jar包需要嚴格的folder順序,Plugins->
python高階—— 從趟過的坑中聊聊爬蟲、反爬、反反爬,附送一套高階爬蟲試題
前言: 時隔數月,我終於又更新部落格了,然而,在這期間的粉絲數也就跟著我停更部落格而漲停了,唉 是的,我改了部落格名,不知道為什麼要改,就感覺現在這個名字看起來要洋氣一點。 那麼最近到底咋不更新部落格了呢?說起原因那就多了,最主要的還是沒時間了,是真的沒時間,前面的那些系
微信小程式自動化,記錄趟過的坑!
 ### 專案思想:關鍵字+資料驅動混合測試
編譯Spark原始碼與子專案GraphX中踩過的坑
編譯Spark原始碼與子專案GraphX中踩過的坑 原始目標:在三臺虛擬機器上真實分散式安裝spark平臺,並通過修改graphx對應的原始碼,觀察graphx的分散式效能,為進一步做圖劃分做準備。 官網文件:http://spark.apachecn.org/do
Hadoop及spark叢集搭建踩過的坑
本叢集總共有三臺主機,一臺master,兩臺slave Hadoop有一個節點無法啟動 在按照教程子雨大資料之Spark入門教程(Python版)搭建Hadoop叢集時,執行jps命令,發現master和其中一個slave能正常工作,執行./bin/yarn node -lis
搭建Spark所遇過的坑
原文連結:https://mp.csdn.net/postedit/82423831 出現此類問題有很多種, 當時遇到這問題的因為是在spark未改動的情況下, 更換了Hive的版本導致版本不對出現了此問題, 一.經驗 Spark Streaming包含三種計算模式:no
在Makefile趟過的一些坑
“make: Nothing to be done for xxx” && “ *** missing separator. Stop.” 我實際的操作是在Makefile裡面添加了一
Mr.ShyZhang趟過的前端“小路坑”
button type屬性submit該按鈕是提交按鈕(除了 Internet Explorer,該值是其他瀏覽器的預設值)button該按鈕是可點選的按鈕(Internet Explorer 的預設值)reset該按鈕是重置按鈕(清除表單資料)總結:其他瀏覽器(除IE瀏覽器
安裝spark-1.5.0-cdh5.5.2所踩過的坑
我一開始想安裝spark-1.5.0-cdh5.5.2的standalone模式,於是乎(已安裝有hadoop叢集):[[email protected] ~]$ tar -zxvf spark-1.5.0-cdh5.5.2.tar.gz[[email p
阿里雲伺服器配置SSL證書成功開啟Https(記錄趟過的各種坑)
環境: 阿里云云伺服器 Windows Server 2008 標準版 SP2 中文版(趁1212優惠買的一年的水貨配置) 阿里雲購買的域名(已備案、已解析) 伺服器:phpstudy:php5.4.45+Apache(因為是phpstudy
java設定jvm引數,我趟過的那些坑
最近 讀到一篇文章,介紹 後端服務壓測的 https://mp.weixin.qq.com/s/XW9geHZ9odHdI7srDiKBIg 裡面提到 gclog,剛好前端時間公司的app 總是出現out of memory 的錯誤,就想看看 gc日誌,自己列印個瞭解下。
自己趟過epoll的坑
坑的背景 本人用epoll來實現多路複用,epoll觸發模式有兩種: ET(邊緣模式)LT(水平模式)LT模式 是標準模式,意味著每次epoll_wait()返回後,事件處理後,如果之後還有資料,會不斷觸發,也就是說,一個套接字上一次完整的資料,epoll_wait()可