
centos下搭建hadoop2.6.5
一 、centos叢集環境配置
1.建立一個namenode節點,5個datanode節點
| IP | |
| namenodezsw | 192.168.129.158 |
| datanode1zsw | 192.168.129.159 |
| datanode2zsw | 192.168.129.160 |
| datanode3zsw | 192.168.129.161 |
| datanode4zsw | 192.168.129.162 |
| datanode5zsw | 192.168.129.163 |
2.關閉防火牆,設定selinux為disabled
#service iptables stop
#chkconfig iptables off
#vim /etc/selinux/config
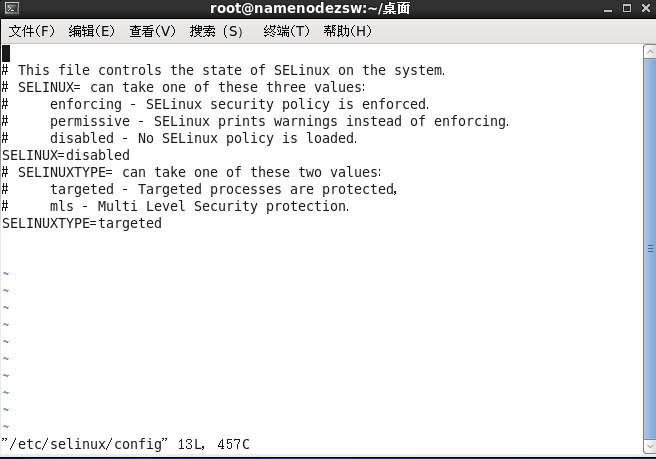
重啟後生效,建議全部配置完成後再全部重啟。
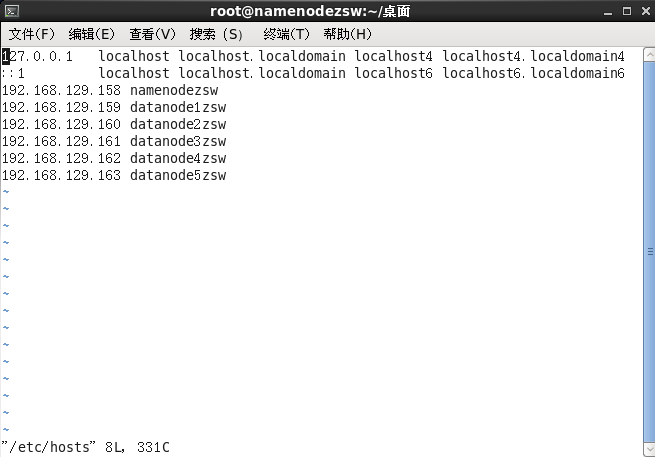
3.配置hosts檔案
將各節點對應的主機名與IP地址記錄在hosts檔案中
vi /etc/hosts
本文所用java安裝包為jdk-7u25-Linux-x64.tar.gz(百度上各種版本的都有)
解壓到/opt目錄下
修改環境變數:
#vi /etc/profile
在檔案末尾新增以下內容
export JAVA_HOME=/opt/jdk1.7.0_25
export JAR_HOME=/opt/jdk1.7.0_25/jre
export ClASSPATH=$
export PATH=$JAVA_HOME/bin:$PATH
儲存後退出,執行
#source /etc/profile
檢視java版本:
#java -version
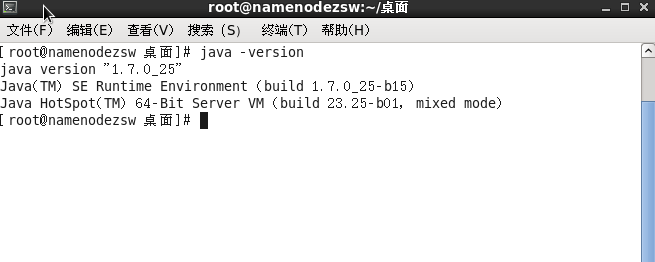
顯示上圖結果說明配置成功
注意:使用source \etc\profile命令盡在本終端有效,重啟後才全部生效
提示:namenode節點和datanode節點上述配置都相同
二、設定各節點間SSH無密碼通訊
在一個節點namenodezsw上操作
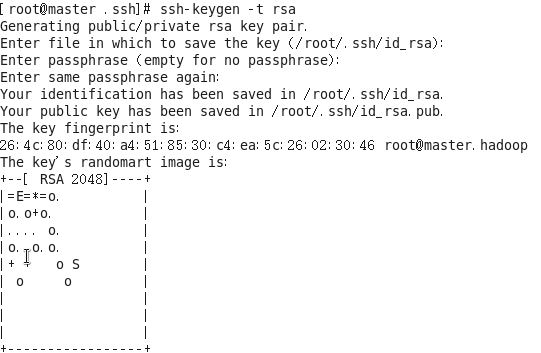
1.生成金鑰對
#ssh-keygen -t rsa
按三次回車,結果如下圖
2.將各個節點生成的公有金鑰新增到authorized_keys
#cat .ssh/id_rsa.pub > .ssh/authorized_keys
#ssh 192.168.129.159 ssh-keygen -t rsa
#ssh 192.168.129.159 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.160 ssh-keygen -t rsa
#ssh 192.168.129.160 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.161 ssh-keygen -t rsa
#ssh 192.168.129.161 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.162 ssh-keygen -t rsa
#ssh 192.168.129.162 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.163 ssh-keygen -t rsa
#ssh 192.168.129.163 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
3.將authorized_keys檔案傳到各個節點
#scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/authorized_keys
#ssh 192.168.129.159 date
#ssh datanode1zsw date
1個namenode節點,5個datanode節點以此類推
兩次ssh命令:
第一遍都需要輸入yes,然後顯示時間
第二遍則直接顯示時間,說明配置成功
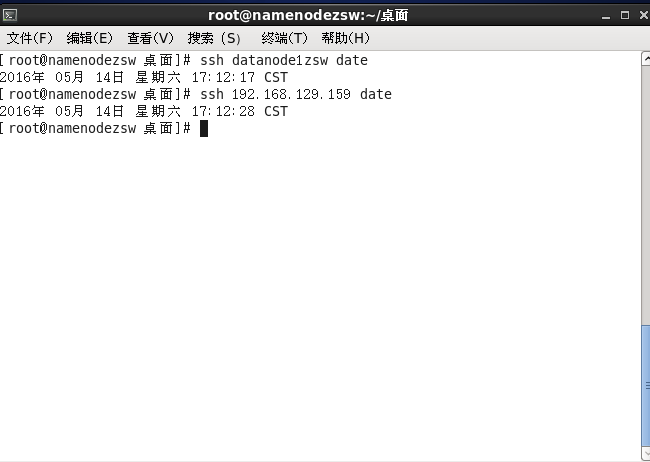
說明:每個節點上都要ssh命令其他的節點主機名和IP一下,檢測是否可以
1.去hadoop官網或者百度下載hadoop-2.6.0-tar.gz,然後解壓到namenode的/opt目錄下
2.修改配置檔案
#cd /opt/hadoop-2.6.0/etc/hadoop
①修改 hadoop-env.sh和yarn-env.sh
export JAVA_HOME=/opt/jdk1.7.0_25
②修改core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.0/tmp</value>
<description>Abase for other temporarydirectories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenodezsw:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>③修改hdfs-site.xml檔案
configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-2.6.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-2.6.0/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>h1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>namenodezsw:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>④修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>namenodezsw:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>namenodezsw:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>namenodezsw:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://namenodezsw:9001</value>
</property>
</configuration>⑤修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>namenodezsw</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>namenodezsw:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>namenodezsw:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>namenodezsw:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>namenodezsw:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>namenodezsw:8088</value>
</property>
</configuration>⑥修改slaves檔案
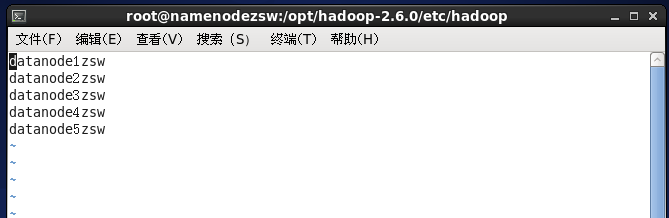
⑦配置環境變數
# vi /etc/profile
export JAVA_HOME=/opt/jdk1.7.0_25
export HADOOP_HOME=/opt/hadoop-2.6.0
export JAR_HOME=/opt/jdk1.7.0_25/jre
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAR_HOME/lib
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
環境變數配置同樣source /etc/profile命令本終端有效,重啟後都有效
至此,修改完成
3.啟動hadoop
使用scp -r /opt/hadoop-2.6.0/ hostname:/opt/命令將hadoop檔案依次拷貝到5個datanode節點上。
在namenode上操作:
首先格式化
#hadoop namenode -format
啟動所有服務
#start-all.sh
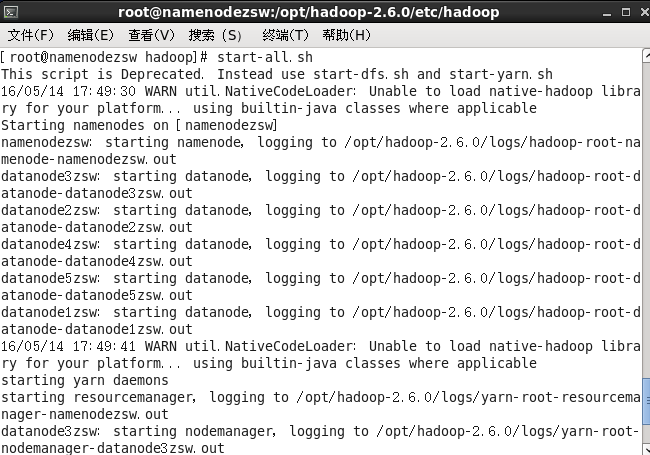
4.驗證
namenode上:
#jps
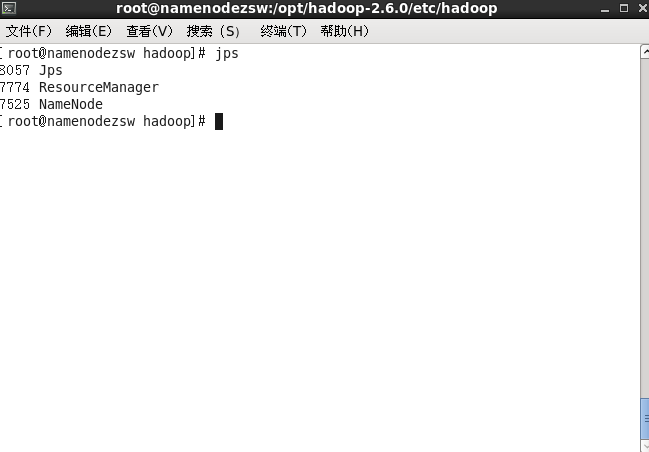
datanode上:
#jps
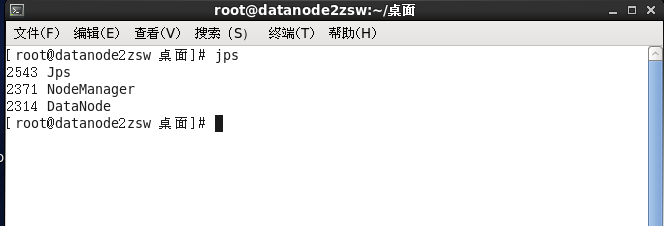
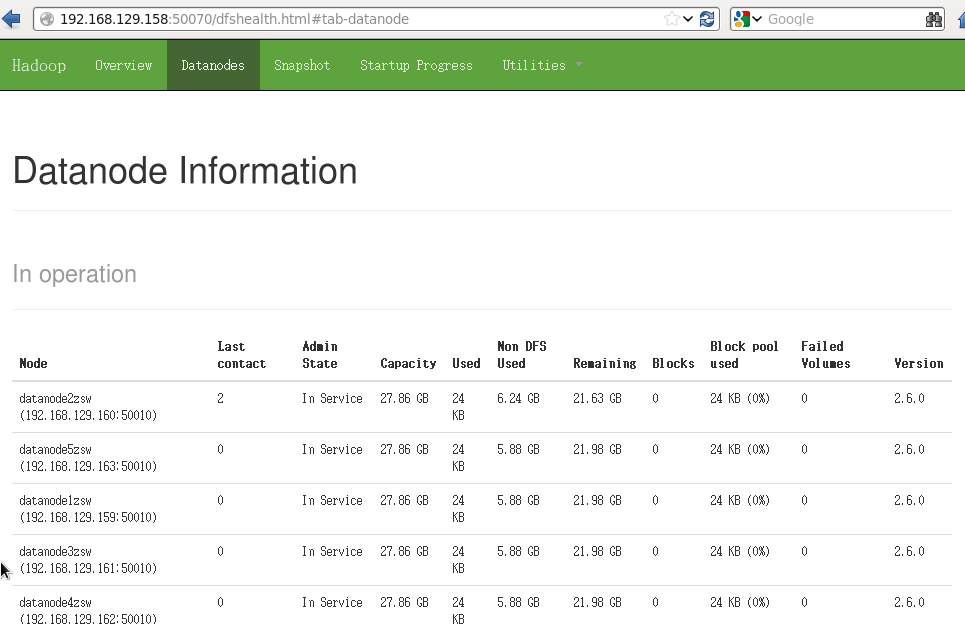
也可以使用 hadoop dfsadmin -report命令檢視總體情況
至此叢集搭建全部完成
遇到的問題
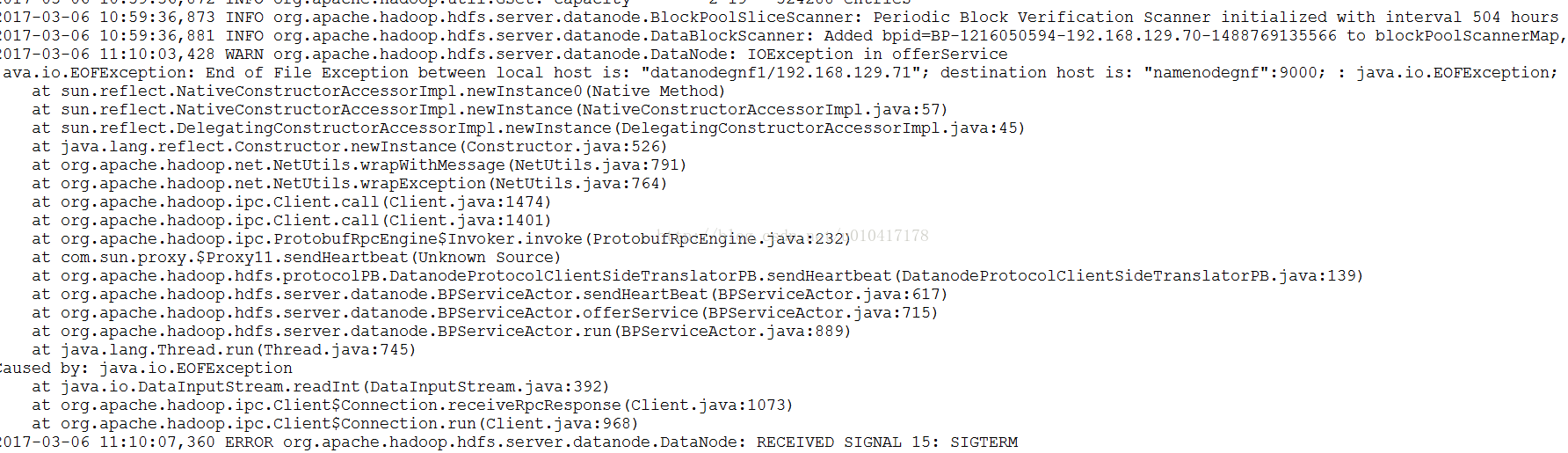

原因是hadoop格式化多次,導致namenode和datanode的clusterid不一樣
解決方法:在hdfs-site.xml中有如下配置
在hadoop-2.6.5/dfs/data下有current/version,開啟version,找到裡面的clusterId
找到log檔案(在hadoop-2.6.5中的logs下),找到clusterId,並用該clusterId替換掉version中的clusterId
注意:改完後注意重啟所有節點,改完後如果直接start-all.sh,可能又會生成不一樣的clusterId
轉載自:http://blog.csdn.net/zsw_2015/article/details/51406644
相關推薦
centos下搭建hadoop2.6.5
一 、centos叢集環境配置1.建立一個namenode節點,5個datanode節點 主機名 IP namenodezsw 192.168.129.158 datanode1zsw 192.168.129.159 datanode2zsw 192.168.129.16
在Eclipse開發環境下搭建Hadoop2.6.0
Eclipse版本Luna 4.4.1 安裝外掛hadoop-eclipse-plugin-2.6.0.jar,下載後放到eclipse/plugins目錄即可。 2. 配置外掛 2.1 配置hadoop主目錄 解壓縮hadoop-2.6.0.tar.g
Centos下使用Hadoop2.6.0-eclipse-plugin外掛
我的開發環境: 作業系統centos5.5 一個namenode 兩個datanode Hadoop版本:hadoop-0.20.203.0 Eclipse版本:eclipse-java-helios-SR2-linux-gtk.tar.gz(使用3.7的版本總是崩潰,讓人鬱悶) 第一步:先啟動hadoop
CentOS 6.8 下編譯hadoop2.7.5
本文測試環境:虛擬機器VMware Workstation Pro、作業系統 CentOS 6.8 64 位 基於上述環境成功編譯hadoop2.7.5、hadoop-2.6.5,其它環境或版本請參照編譯。 本文以編譯hadoop2.7.5的過程作介紹 一、編譯前準備 下載
Centos下Yum安裝PHP 5.5、5.6、7.0
mbstring eas common mysql 編譯安裝 test .rpm mysq cli Centos系統自帶的php版本很低,如果我們需要使用高版本的php,可以不用編譯安裝,直接用yum安裝會非常省時省力。 1.檢查當前安裝的PHP包yum list inst
Centos下Yum安裝PHP5.5,5.6,7.0
eas yum安裝 remove dap web select mysql style -s 默認的版本太低了,手動安裝有一些麻煩,想采用Yum安裝的可以使用下面的方案: 1.檢查當前安裝的PHP包 yum list installed | grep php 如果有安裝
在CentOS6.4下使用Eclipse編譯執行MapReduce程式Hadoop2.6.5
本文是本人按照廈門大學林子雨老師的教程然後自己在使用Eclipse編譯執行MapReduce程式的時候所做的一個部落格教程,意在幫助更多的人。廈門大學林子雨老師的教程地址:http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-ecli
Centos-7.2 下搭建 Zookeeper-3.5.3 叢集的搭建與測試
《 Centos7下Zookeeper叢集的搭建與測試 》 前言: 在這兒通過搭建三個 zookeeper 例項,實現 zookeeper 的叢集環境的搭建工作,在實際開發工作中,將對應的 zookeeper 例項修改為各個 zookeeper 伺服器節點即可實
centos下hadoop-2.6.0完全分散式搭建
一、Hadoop執行模式: Hadoop有三種執行模式,分別如下: 單機(非分散式)模式 偽分散式(用不同程序模仿分散式執行中的各類節點)模式 完全分散式模式 注:前兩種可以在單機執行,最後一種用於真
CentOS 7.4 下搭建 Elasticsearch 6.3 搜尋群集
上個月 13 號,Elasticsearch 6.3 如約而至,該版本和以往版本相比,新增了很多新功能,其中最令人矚目的莫過於集成了 X-Pack 模組。而在最新的 X-Pack 中 Elasticsearch SQL 已經可用,雖然還處於實驗階段,但是相對於編寫複雜的 DSL 查詢語
hadoop學習第二天~Hadoop2.6.5完全分散式叢集搭建和測試
環境配置: 系統 centos7 節點 192.168.1.111 namenode 192.168.1.115 datanode2 192.168.1.116 datanode3 java 環境 :
Hadoop2.6.5高可用叢集搭建
軟體環境: linux系統: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主機配置: 一共m1, m2, m3這五部機, 每部主機的使用者名稱都為centos 192.168.179.201: m
CentOS 下HBase1.2.6 單機和 偽分散式平臺搭建
前篇文章搭建了 hadoop hbase 1.2.6 安裝 一 hbase 安裝 1. 下載解壓 解壓到 /usr/hbase/ 2. 修改環境 命令 : vi /etc/profile 新增 export HBASE_HOME=/usr/hbase/hbase-1
Hadoop2.6.5搭建教程
最近需要搭一個HBase環境,所以第一步就是要搭建Hadoop了。搭建過程主要參考了張良均、樊哲、位文超、劉名軍等人著作的《Hadoop大資料探勘》(機械工業出版社),部分環節參考了網上查閱的資料,現在也找不到出處了,十分抱歉。 Hadoop2.6.5叢集搭建 搭建環境
Centos 下搭建SVN + Apache 服務器
httpd restart svnadmin author stat pac 目錄 創建 etc 摘要: 搭建SVN + Apache 服務器 安裝軟件包 # yum install httpd # yum install mod_dav_svn # yum in
centos下搭建redis集群
div nec dump ont wait bin 1-1 實例 設置 必備的工具: redis-3.0.0.tar redis-3.0.0.gem(ruby和redis接口) 分析: 首先,集群數需要基數,這裏搭建一個簡單的redis集群(6個redis實例進行集
centos下搭建多項目svn服務器
服務器環境 出現 配置文件 png 演示 sta 圖形界面 -a 3.4 svn是多人協作開發中的利器,是一個開放源代碼的版本控制系統。 相比與git,他的操作更加簡單,windows下有優秀的圖形界面,並且支持的文件類型比較多。 本文講述如何在linux下搭建一個sv
Centos下搭建Confluence
centos下搭建confluenceCentos下搭建Confluence下載安裝Confluence搭建包百度雲鏈接http://pan.baidu.com/s/1dFiyThR 密碼:9jb2或者官網下載:https://confluence.atlassian.com/conf54/conflue
CentOS下搭建智能DNS系統wdDNS 的方法
mage 1.5 cto 線路 升級版 適合 ado 系統 ffffff CentOS下搭建智能DNS系統wdDNS 的方法 導讀 wdDNS是由wdlinux團隊於2011年推出的智能DNS解析系統,基於開源
Centos下搭建golang環境
centos版本 -s 系統版本 path www wget 6.4 font lang 一、下載安裝包 先查看一下我的Centos版本,這裏是6.4. # cat /etc/redhat-release CentOS release 6.4 (Final)