
Kafka原始碼深度解析-系列1 -訊息佇列的策略與語義
-Kafka關鍵概念介紹
-訊息佇列的各種策略與語義
作為一個訊息佇列,Kafka在業界已經相當有名。相對傳統的RabbitMq/ActiveMq,Kafka天生就是分散式的,支援資料的分片、複製以及叢集的方便擴充套件。
與此同時,Kafka是高可靠的、持久化的訊息佇列,並且這種可靠性沒有以犧牲效能為前提。
同時,在允許丟訊息的業務場景下,Kafka可以以非ACK、非同步的方式來執行,從而最大程度的提高效能。
從本篇開始,本序列將會由淺入深、從使用方式到原理再到原始碼,全面的剖析Kafka這個訊息中介軟體的方方面面。(所用Kafka原始碼為0.9.0)
關鍵概念介紹
topic
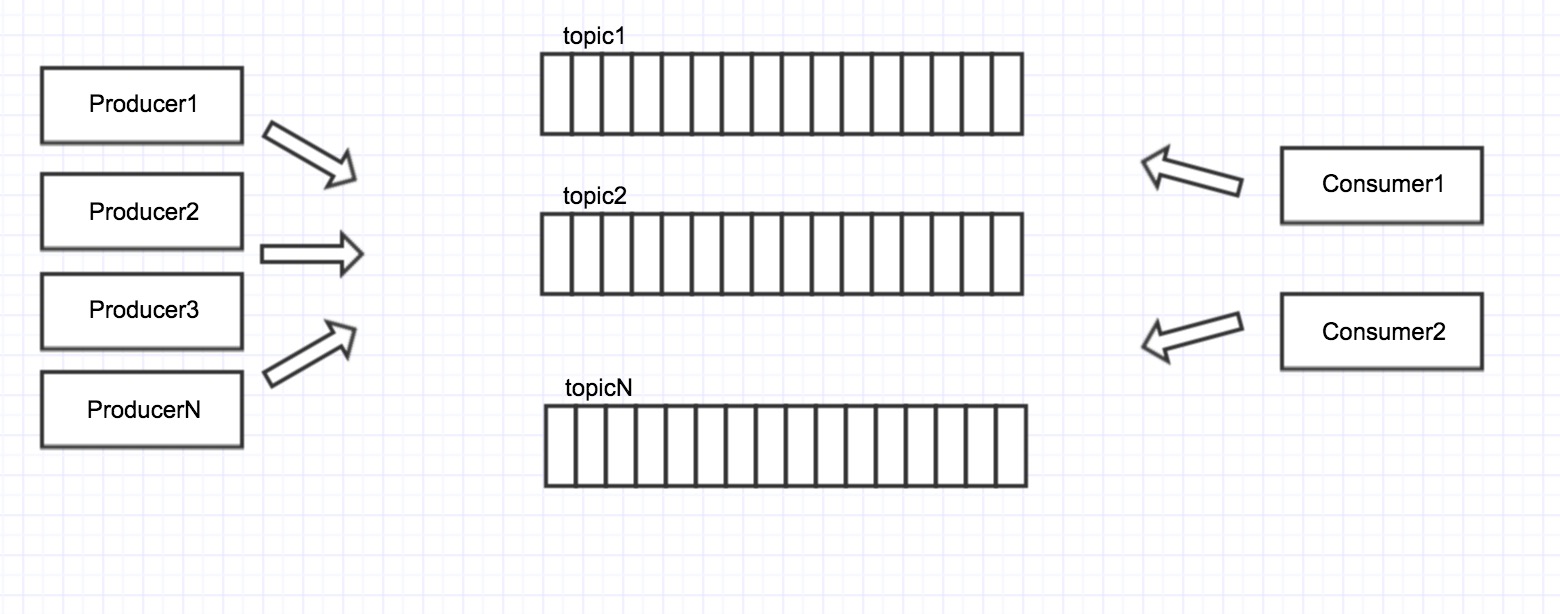
以下是kafka的邏輯結構圖: 每個topic也就是自定義的一個佇列,producer往佇列中放訊息,consumer從佇列中取訊息,topic之間相互獨立。
broker
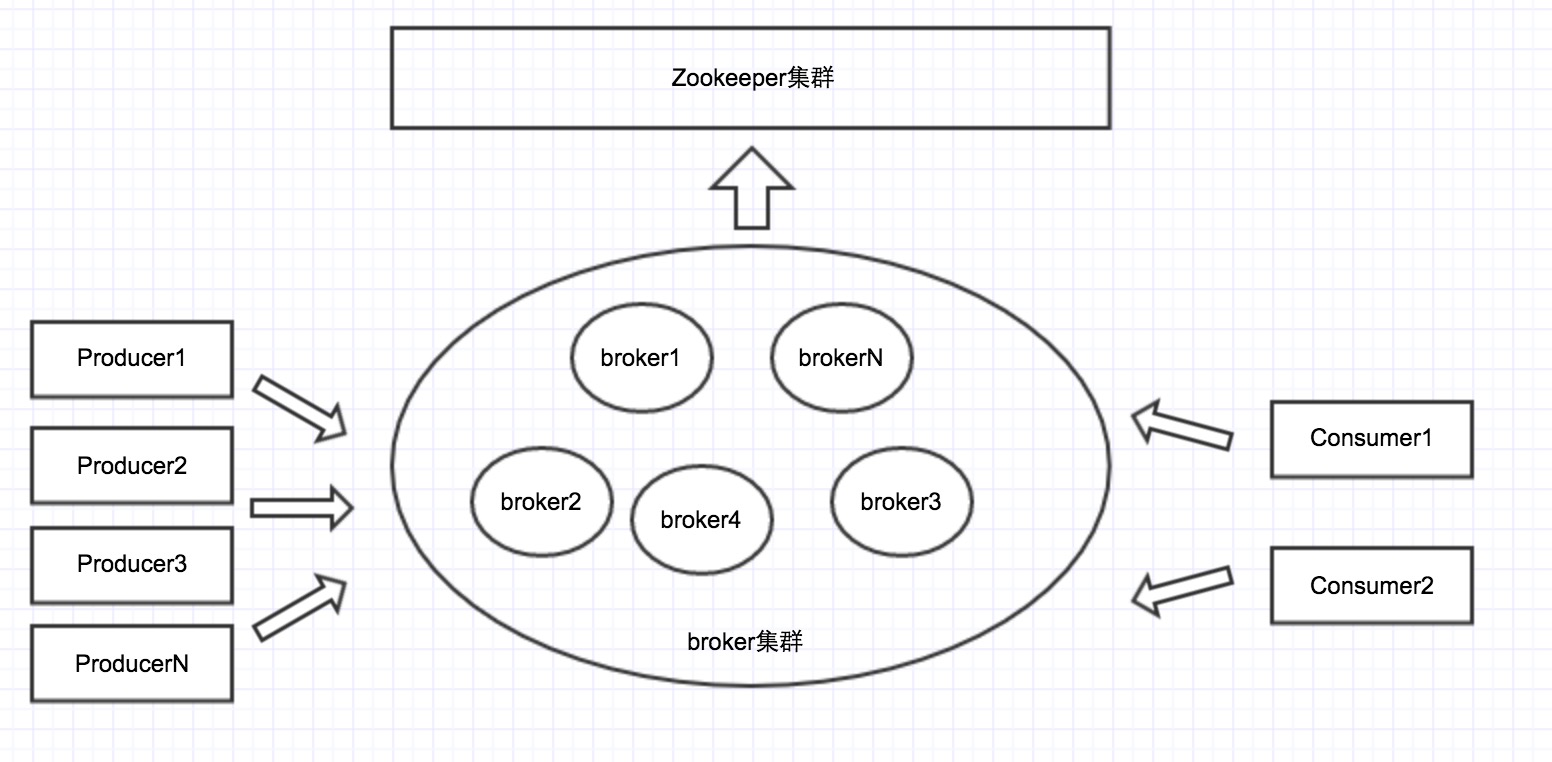
與上圖對應的是kafka的物理結構圖:每個broker通常就是一臺物理機器,在上面執行kafka server的一個例項,所有這些broker例項組成kafka的伺服器叢集。
每個broker會給自己分配一個唯一的broker id。broker叢集是通過zookeeper叢集來管理的。每個broker都會註冊到zookeeper上,有某個機器掛了,有新的機器加入,zookeeper都會收到通知。
在0.9.0中,producer/consumer已經不會依賴Zookeeper來獲取叢集的配置資訊,而是通過任意一個broker來獲取整個叢集的配置資訊。如下圖所示:只有服務端依賴zk,客戶端不依賴zk。
partition
kafka的topic,在每個機器上,是用檔案儲存的。而這些檔案呢,會分目錄。partition就是檔案的目錄。比如一個topic叫abc,分了10個partion,則在機器的目錄上,就是:
abc_0
abc_1
abc_2
abc_3
…
abc_9
然後每個目錄裡面,存放了一堆訊息檔案,訊息是順序append log方式儲存的。關於這個,後面會詳細闡述。
replica/leader/follower
每個topic的partion的所有訊息,都不是隻存1份,而是在多個broker上冗餘儲存,從而提高系統的可靠性。這多臺機器就叫一個replica集合。
在這個replica集合中,需要選出1個leader,剩下的是follower。也就是master/slave。
傳送訊息的時候,只會傳送給leader,然後leader再把訊息同步給followers(以pull的方式,followers去leader上pull,而不是leader push給followers)。
那這裡面就有一個問題:leader收到訊息之後,是直接返回給producer呢,還是等所有followers都寫完訊息之後,再返回? 關於這個,後面會相信闡述。
關鍵點:這裡replica/leader/follower都是邏輯概念,並且是相對”partion”來講的,而不是”topic”。也就說,同一個topic的不同partion,對於的replica集合可以是不一樣的。
比如
“abc-0” <1,3,5> //abc_0的replica集合是borker 1, 3, 5, leader是1, follower是3, 5
“abc-1” <1,3,7> //abc_1的replica集合是broker 1, 3, 7,leader是1, follower是3, 7
“abc_2” <3,7,9>
“abc_3” <1,7,9>
“abc_4” <1,3,5>
訊息佇列的各種策略和語義
對於訊息佇列的使用,表面上看起來很簡單,一端往裡面放,一端從裡面取。但就在這一放一取中,存在著諸多策略。
Producer的策略
是否ACK
所謂ACK,是指伺服器收到訊息之後,是存下來之後,再給客戶端返回,還是直接返回。很顯然,是否ACK,是影響效能的一個重要指標。在kafka中,request.required.acks有3個取值,分別對應3種策略:
request.required.acks
//0: 不等伺服器ack就返回了,效能最高,可能丟資料
//1. leader確認訊息存下來了,再返回
//all: leader和當前ISR中所有replica都確認訊息存下來了,再返回(這種方式最可靠)
備註:在0.9.0以前的版本,是用-1表示all
同步傳送 vs 非同步傳送
所謂非同步傳送,就是指客戶端有個本地緩衝區,訊息先存放到本地緩衝區,然後有後臺執行緒來發送。
在0.8.2和0.8.2之前的版本中,同步傳送和非同步傳送是分開實現的,用的Scala語言。從0.8.2開始,引入了1套新的Java版的client api。在這套api中,同步實際上是用非同步間接實現的:
在非同步傳送下,有以下4個引數需要配置:
(1)佇列的最大長度
buffer.memory //預設為33554432, 即32M
(2)佇列滿了,客戶端是阻塞,還是拋異常出來(預設是true)
block.on.buffer.full
//true: 阻塞訊息
//false:拋異常
(3)傳送的時候,可以批量傳送的資料量
batch.size //預設16384位元組,即16K
(4)最長等多長時間,批量傳送
linger.ms //預設是0
//類似TCP/IP協議中的linger algorithm,> 0 表示傳送的請求,會在佇列中積攥,然後批量傳送。
很顯然,非同步傳送可以提高發送的效能,但一旦客戶端掛了,就可能丟資料。
對於RabbitMQ, ActiveMQ,他們都強調可靠性,因此不允許非ACK的傳送,也沒有非同步傳送模式。Kafka提供了這個靈活性,允許使用者在效能與可靠性之間做權衡。
(5)訊息的最大長度
max.request.size //預設是1048576,即1M
這個引數會影響batch的大小,如果單個訊息的大小 > batch的最大值(16k),那麼batch會相應的增大
Consumer的策略
Push vs Pull
所有的訊息佇列都要面對一個問題,是broker把訊息Push給消費者呢,還是消費者主動去broker Pull訊息?
kafka選擇了pull的方式,為什麼呢? 因為pull的方式更靈活:訊息傳送頻率應該如何,訊息是否可以延遲然後batch傳送,這些資訊只有消費者自己最清楚!
因此把控制權交給消費者,消費者自己控制消費的速率,當消費者處理訊息很慢時,它可以選擇減緩消費速率;當處理訊息很快時,它可以選擇加快消費速率。而在push的方式下,要實現這種靈活的控制策略,就需要額外的協議,讓消費者告訴broker,要減緩還是加快消費速率,這增加了實現的複雜性。
另外pull的方式下,消費者可以很容易的自適應控制訊息是batch的傳送,還是最低限度的減少延遲,每來1個就傳送1個。
消費的confirm
在消費端,所有訊息佇列都要解決的一個問題就是“消費確認問題”:消費者拿到一個訊息,然後處理這個訊息的時候掛了,如果這個時候broker認為這個訊息已經消費了,那這條訊息就丟失了。
一個解決辦法就是,消費者在消費完之後,再往broker發個confirm訊息。broker收到confirm訊息之後,再把訊息刪除。
要實現這個,broker就要維護每個訊息的狀態,已傳送/已消費,很顯然,這會增大broker的實現難度。同時,這還有另外一個問題,就是消費者消費完訊息,傳送confirm的時候,掛了。這個時候會出現重複消費的問題。
kafka沒有直接解決這個問題,而是引入offset回退機制,變相解決了這個問題。在kafka裡面,訊息會存放一個星期,才會被刪除。並且在一個partion裡面,訊息是按序號遞增的順序存放的,因此消費者可以回退到某一個歷史的offset,進行重新消費。
當然,對於重複消費的問題,需要消費者去解決。
broker的策略
訊息的順序問題
在某些業務場景下,需要訊息的順序不能亂:傳送順序和消費順序要嚴格一致。而在kafka中,同一個topic,被分成了多個partition,這多個partition之間是互相獨立的。
之所以要分成多個partition,是為了提高併發度,多個partition並行的進行傳送/消費,但這卻沒有辦法保證訊息的順序問題。
一個解決辦法是,一個topic只用一個partition,但這樣很顯然限制了靈活性。
還有一個辦法就是,所有傳送的訊息,用同一個key,這樣同樣的key會落在一個partition裡面。
訊息的刷盤機制
我們都知道,作業系統本身是有page cache的。即使我們用無緩衝的io,訊息也不會立即落到磁碟上,而是在作業系統的page cache裡面。作業系統會控制page cache裡面的內容,什麼時候寫回到磁碟。在應用層,對應的就是fsync函式。
我們可以指定每條訊息都呼叫一次fsync存檔,但這會較低效能,也增大了磁碟IO。也可以讓作業系統去控制存檔。
訊息的不重不漏 – Exactly Once
一個完美的訊息佇列,應該做到訊息的“不重不漏”,這裡麵包含了4重語義:
訊息不會重複儲存;
訊息不會重複消費;
訊息不會丟失儲存;
訊息不會丟失消費。
先說第1個:重複儲存。傳送者傳送一個訊息之後,伺服器返回超時了。那請問,這條訊息是儲存成功了,還是沒有呢?
要解決這個問題:傳送者需要給每條訊息增加一個primary key,同時伺服器要記錄所有傳送過的訊息,用於判重。很顯然,要實現這個,代價很大
重複消費:上面說過了,要避免這個,消費者需要訊息confirm。但同樣,會引入其他一些問題,比如消費完了,傳送confirm的時候,掛了怎麼辦? 一個訊息一直處於已傳送,但沒有confirm狀態怎麼辦?
丟失儲存:這個已經解決
丟失消費:同丟失儲存一樣,需要confirm。
總結一下:真正做到不重不漏,exactly once,是很難的。這個需要broker、producer、consumer和業務方的協調配合。
在kafka裡面,是保證訊息不漏,也就是at least once。至於重複消費問題,需要業務自己去保證,比如業務加判重表。