
Kafka原始碼深度解析-序列5 -Producer -RecordAccumulator佇列分析
在Kafka原始碼分析-序列2中,我們提到了整個Producer client的架構圖,如下所示:
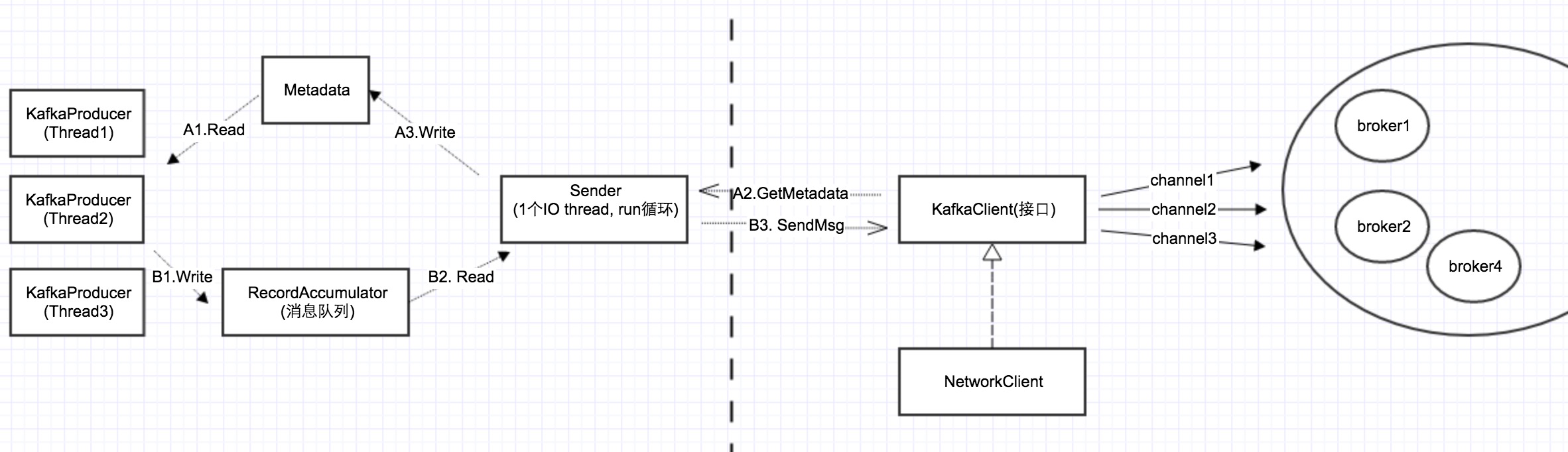
其它幾個元件我們在前面都講過了,今天講述最後一個元件RecordAccumulator.
Batch傳送
在以前的kafka client中,每條訊息稱為 “Message”,而在Java版client中,稱之為”Record”,同時又因為有批量傳送累積功能,所以稱之為RecordAccumulator.
RecordAccumulator最大的一個特性就是batch訊息,扔到佇列中的多個訊息,可能組成一個RecordBatch,然後由Sender一次性發送出去。
每個TopicPartition一個佇列
下面是RecordAccumulator的內部結構,可以看到,每個TopicPartition對應一個訊息佇列,只有同一個TopicPartition的訊息,才可能被batch。
public final class RecordAccumulator {
private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches;
...
}
batch的策略
那什麼時候,訊息會被batch,什麼時候不會呢?下面從KafkaProducer的send方法看起:
//KafkaProducer
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
try 從上面程式碼可以看到,batch邏輯,都在accumulator.append函式裡面:
public RecordAppendResult append(TopicPartition tp, byte[] key, byte[] value, Callback callback, long maxTimeToBlock) throws InterruptedException {
appendsInProgress.incrementAndGet();
try {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
Deque<RecordBatch> dq = dequeFor(tp); //找到該topicPartiton對應的訊息佇列
synchronized (dq) {
RecordBatch last = dq.peekLast(); //拿出佇列的最後1個元素
if (last != null) {
FutureRecordMetadata future = last.tryAppend(key, value, callback, time.milliseconds()); //最後一個元素, 即RecordBatch不為空,把該Record加入該RecordBatch
if (future != null)
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordBatch last = dq.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(key, value, callback, time.milliseconds());
if (future != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
free.deallocate(buffer);
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
//佇列裡面沒有RecordBatch,建一個新的,然後把Record放進去
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
private Deque<RecordBatch> dequeFor(TopicPartition tp) {
Deque<RecordBatch> d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
Deque<RecordBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}從上面程式碼我們可以看出Batch的策略:
1。如果是同步傳送,每次去佇列取,RecordBatch都會為空。這個時候,訊息就不會batch,一個Record形成一個RecordBatch
2。Producer 入隊速率 < Sender出隊速率 && lingerMs = 0 ,訊息也不會被batch
3。Producer 入隊速率 > Sender出對速率, 訊息會被batch
4。lingerMs > 0,這個時候Sender會等待,直到lingerMs > 0 或者 佇列滿了,或者超過了一個RecordBatch的最大值,就會發送。這個邏輯在RecordAccumulator的ready函式裡面。
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
Set<Node> readyNodes = new HashSet<Node>();
long nextReadyCheckDelayMs = Long.MAX_VALUE;
boolean unknownLeadersExist = false;
boolean exhausted = this.free.queued() > 0;
for (Map.Entry<TopicPartition, Deque<RecordBatch>> entry : this.batches.entrySet()) {
TopicPartition part = entry.getKey();
Deque<RecordBatch> deque = entry.getValue();
Node leader = cluster.leaderFor(part);
if (leader == null) {
unknownLeadersExist = true;
} else if (!readyNodes.contains(leader)) {
synchronized (deque) {
RecordBatch batch = deque.peekFirst();
if (batch != null) {
boolean backingOff = batch.attempts > 0 && batch.lastAttemptMs + retryBackoffMs > nowMs;
long waitedTimeMs = nowMs - batch.lastAttemptMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
boolean full = deque.size() > 1 || batch.records.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress(); //關鍵的一句話
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeadersExist);
}為什麼是Deque?
在上面我們看到,訊息佇列用的是一個“雙端佇列“,而不是普通的佇列。
一端生產,一端消費,用一個普通的佇列不就可以嗎,為什麼要“雙端“呢?
這其實是為了處理“傳送失敗,重試“的問題:當訊息傳送失敗,要重發的時候,需要把訊息優先放入佇列頭部重新發送,這就需要用到雙端佇列,在頭部,而不是尾部加入。
當然,即使如此,該訊息發出去的順序,還是和Producer放進去的順序不一致了。