
爬取資料儲存至mysql資料庫
做爬蟲,免不了將抓取下來的資料儲存到資料庫,但是如何儲存到資料庫呢,下面我通過我工作中抓取的一個網站來展示,程式碼有點多,但是邏輯很簡單,此例是將view Details的連結儲存在了mysql中,先看看網站是什麼樣子:

下邊這個圖是頁碼
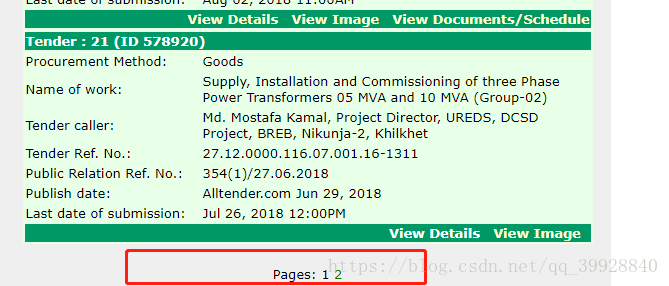
網站是這個樣子,我在程式碼中有個判斷,就是判斷連結是否有三個,分別執行不同操作,就是根據圖中標記來的
此次請求是get請求,不需要傳參,只需要重新拼接url進行翻頁即可
以下是程式碼全圖:
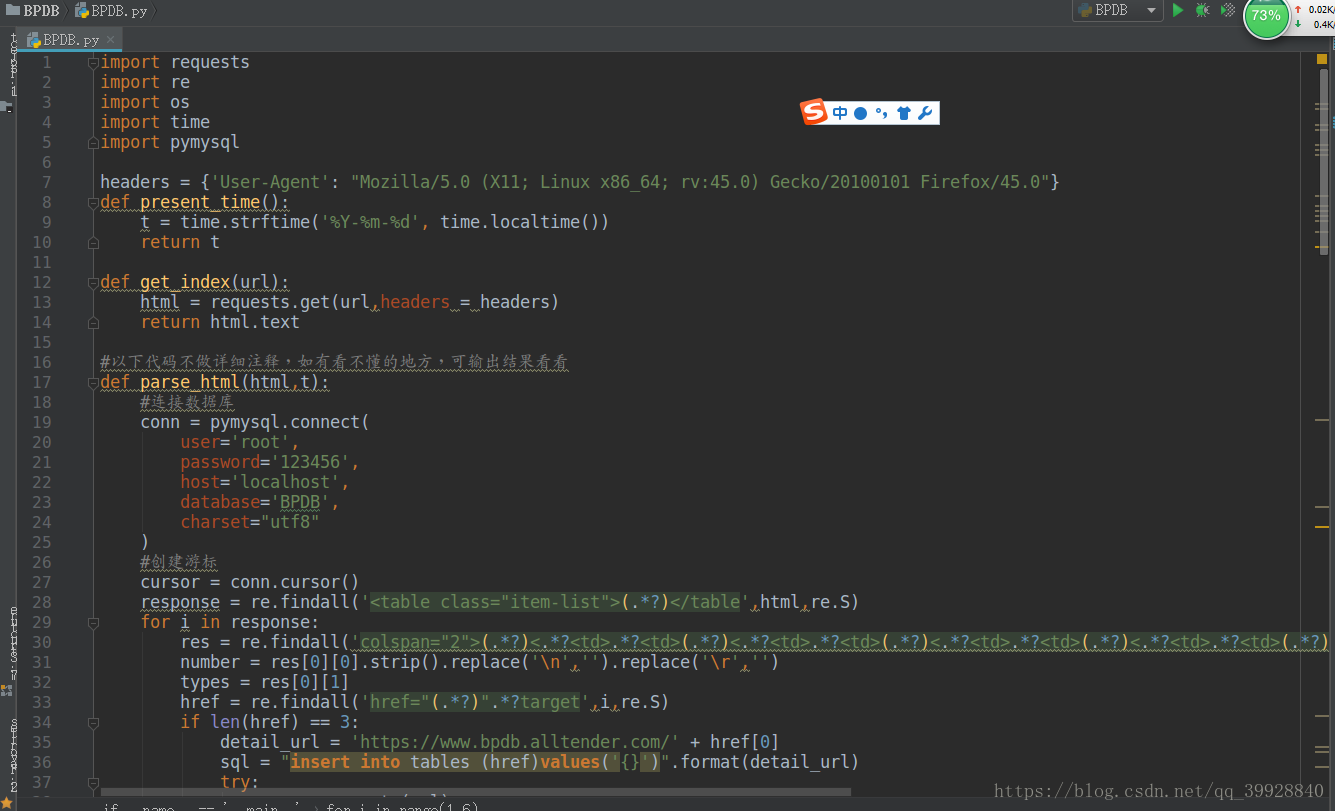
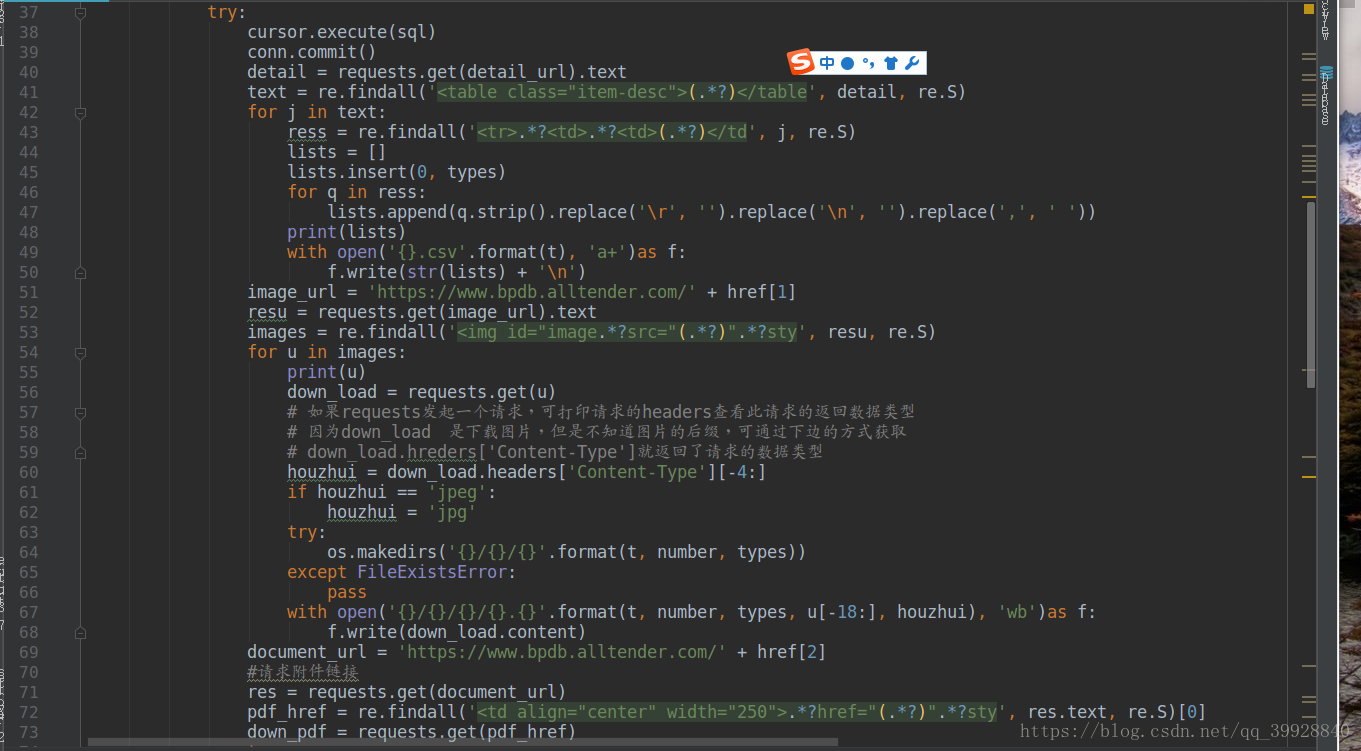
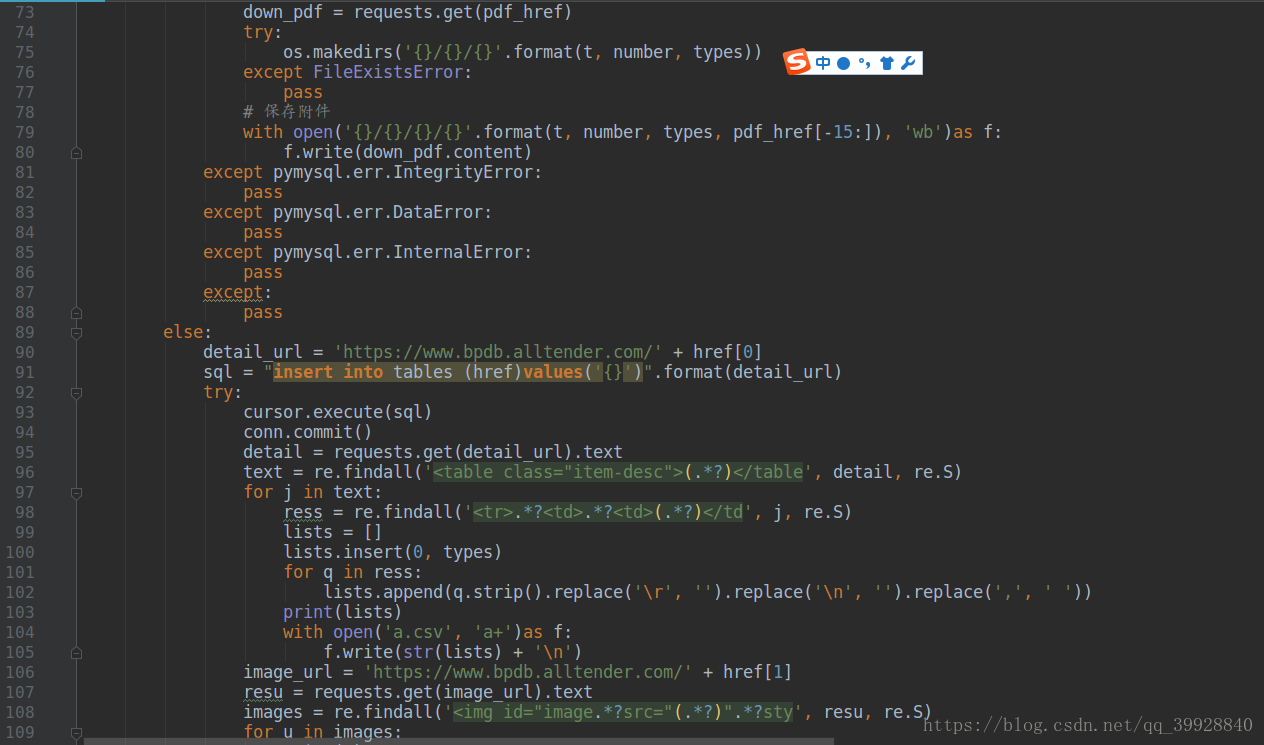
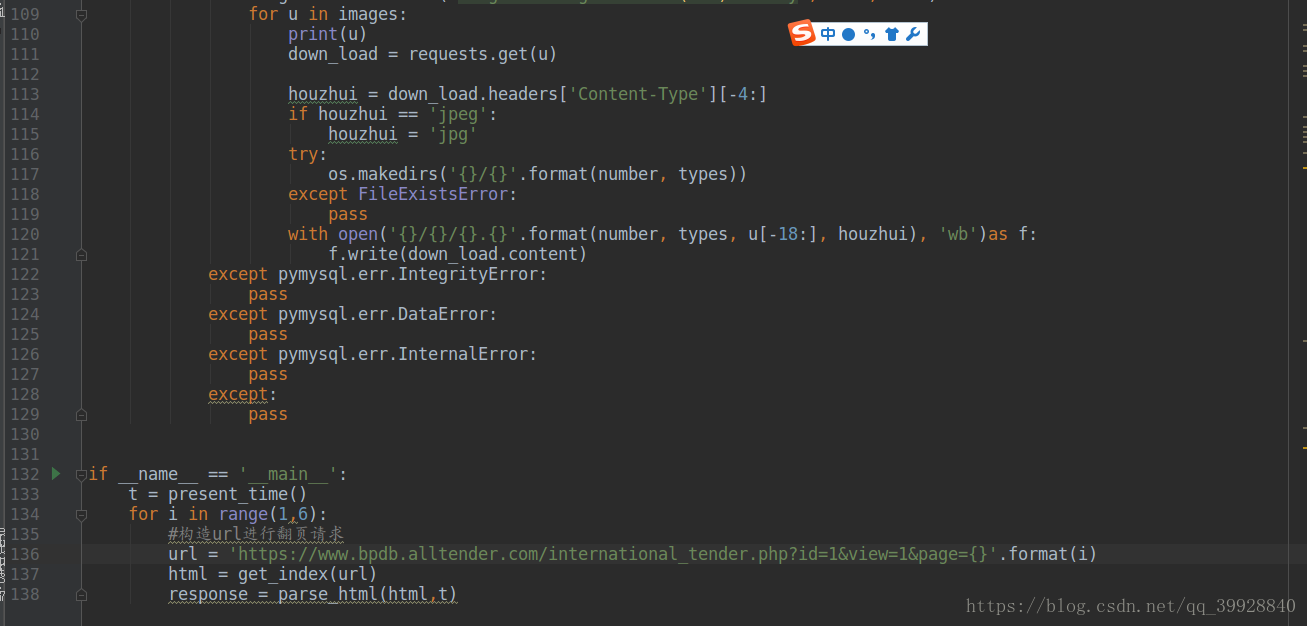
其中有註釋的才是需要注意的地方,程式碼這麼多,著重看吧!
相關推薦
爬取資料儲存至mysql資料庫
做爬蟲,免不了將抓取下來的資料儲存到資料庫,但是如何儲存到資料庫呢,下面我通過我工作中抓取的一個網站來展示,程式碼有點多,但是邏輯很簡單,此例是將view Details的連結儲存在了mysql中,先看看網站是什麼樣子: 下邊這個圖是頁碼 網站是這個
Python爬蟲-利用百度地圖API介面爬取資料並儲存至MySQL資料庫
首先,我這裡有一份相關城市以及該城市的公園數量的txt檔案: 其次,利用百度地圖API提供的介面爬取城市公園的相關資訊。 所利用的API介面有兩個: 1、http://api.map.baidu.com/place/v2/search?q=公園&
python爬取拉勾網資料儲存到mysql資料庫
環境:python3 相關包:requests , json , pymysql 思路:1.通過chrome F12找到拉鉤請求介面,分析request的各項引數 2.模擬瀏覽器請求拉鉤介面 3.預設返回的json不是標準格式 ,
scrapy爬取資料儲存csv、mysql、mongodb、json
目錄 前言 Items Pipelines 前言 用Scrapy進行資料的儲存進行一個常用的方法進行解析 Items item 是我們儲存資料的容器,其類似於 python 中的字典。使用 item 的好處在於: Item 提供了額外保護機制來避免拼寫錯誤導致
將豆瓣排名前250爬取資料通過sqlite3存入資料庫
#爬取豆瓣top250電影,並儲存到資料庫 import requests from bs4 import BeautifulSoup import sqlite3 def get_html(web_url): user_agent = 'Mozilla/5.0 (Linux; Andro
python爬蟲系列(4.3-資料儲存到mysql資料庫中)
一、如果你對mysql資料庫還不太熟悉 二、基本操作 1、在python中使用pymysql連線mysql 2、安裝包 pip3 install pymysql 3、定義一個建立資料庫的方法(或者手動、SQL語句建立資料庫) # 定義一個建立資料庫的函
python爬取資料儲存為Excel格式
#encoding:'utf-8' import urllib.request from bs4 import BeautifulSoup import os import time import xlrd import xlwt from xlutils.copy impo
如何在python3中將網頁爬蟲資料儲存到mysql資料庫
前兩篇文章都在說在py中用BeautfulSoup爬取本地網頁的事情,本來準備去真實網頁試一下的,但是老林說不如把你之前學的mysql資料庫溫習一下,順道學著把你現在爬到的網頁存取到mysql資料庫之中~ 由此 本文的主題就出現了: 如何在python3中將網頁爬蟲資料儲存到mysql資
關於爬取資料儲存到json檔案,中文是unicode解決方式
原帖地址: https://www.cnblogs.com/yuyang26/p/7813097.html 流程: 爬取的資料處理為列表,包含字典。裡面包含中文, 經過json.dumps,儲存到json檔案中, 發現裡面的中文顯示未\ue768這樣子 查閱資
python爬取的小說存入mysql資料庫
特別需要注意的是需要存的程式碼的編碼格式一定要與庫的編碼格式相同。其實還是相當於有一個類似模板的內容:importMySQLdbconn = MySQLdb.connect(host='127.0.0.1', db='msl', user='root', passwd='z
scrapy----將資料儲存到MySQL資料庫中
1.在pipelines.py中自定義自己的pipelineimport pymysql class PymysqlPipeline(object): def __init__(self): # 連線資料庫 self.connect =
【Python爬蟲】 輕鬆幾步 將 scrapy 框架 獲取得到的 資料 儲存到 MySQL 資料庫中
以下操作 是在 一個 完整的 scrapy 專案中 新增 程式碼: 中介軟體 和 spiders 中的程式碼 都不需要修改 只需要 做下面兩件事就可以將資料儲存到資料庫了,不過在寫程式碼之前 我們要先: 在終端 執行命令:net star
cheerio爬取網頁資料,儲存到MySQL資料庫
最近在做物流專案成本分析,需要爬取柴油價格資料,使用到了cheerio,cheerio實現了jQuery核心的一個子集。以下為爬取程式碼。 //getHtml.js,獲取HTML頁面資料 var http = require("http"); function gethtml(url,
將爬取的資料儲存到mysql中
為了把資料儲存到mysql費了很多周折,早上再來折騰,終於折騰好了 安裝資料庫 1、pip install pymysql(根據版本來裝) 2、建立資料 開啟終端 鍵入mysql -u root -p 回車輸入密碼 &
JAVA 爬取指定網站的資料並存入MySQL資料庫中 maven +httpclient+jsoup+mysql
最近在做一個小專案,因為要用的資料爬取,所以研究了好多天,分享一下自己的方法 目錄結構: 自己建立maven工程,匯入相關依賴:pom.xml <?xml version="1.0" enco
[python爬蟲] Selenium爬取內容並存儲至MySQL資料庫
前面我通過一篇文章講述瞭如何爬取CSDN的部落格摘要等資訊。通常,在使用Selenium爬蟲爬取資料後,需要儲存在TXT文字中,但是這是很難進行資料處理和資料分析的。這篇文章主要講述通過Selenium爬取我的個人部落格資訊,然後儲存在資料庫MySQL中,以便
Python爬取網頁資訊並且儲存到MySQL資料庫
今天在執行一小Python爬取某網頁的資訊的時候,結果,報錯了,根據錯誤,應該是資料庫連線失敗,密碼有錯誤 檢查程式密碼應該沒錯呀,然後直接訪問資料庫,我的天,試了好多次,都快放棄自己了,昨晚明明成功的呀 然後開啟Navicat,檢視昨晚設定的連線屬性,沒錯呀,密碼就是
Scrapy爬取知名技術網站文章並儲存到MySQL資料庫
之前的幾篇文章都是在講如何把資料爬下來,今天記錄一下把資料爬下來並儲存到MySQL資料庫。 文章中有講同步和非同步兩種方法。 所有文章文章的地址:http://blog.jobbole.com/all-posts/ 對所有文章
python 遠端連線MySQL資料庫 拉取資料存至本地檔案
1.連線資料庫 這裡預設大家都已經配置安裝好 MySQL 和 Python 的MySQL 模組,且預設大家的DB內表和訪問賬號許可權均已設定無誤,下面直接程式碼演示: # -*- codin
Pyspider例項之抓取資料並儲存到MySQL資料庫
本次主要是在Pyspider例項之抓取小米眾籌產品的基礎上修改的, 本來想直接在之前那篇文章修改的,但是感覺有點長了,所以決定另外寫一篇。 閒話少說,直接進入正題: 1、在Pyspider的指令碼開頭引入: from pyspider.databas