
ThreadPoolExecutor運轉機制詳解
最近發現幾起對ThreadPoolExecutor的誤用,其中包括自己,發現都是因為沒有仔細看註釋和內部運轉機制,想當然的揣測引數導致,先看一下新建一個ThreadPoolExecutor的構建引數:
- public ThreadPoolExecutor(int corePoolSize,
- int maximumPoolSize,
- long keepAliveTime,
- TimeUnit unit,
-
BlockingQueue<Runnable> workQueue,
- ThreadFactory threadFactory,
- RejectedExecutionHandler handler)
看這個引數很容易讓人以為是執行緒池裡保持corePoolSize個執行緒,如果不夠用,就加執行緒入池直至maximumPoolSize大小,如果還不夠就往workQueue里加,如果workQueue也不夠就用RejectedExecutionHandler來做拒絕處理。
但實際情況不是這樣,具體流程如下:
1)當池子大小小於corePoolSize就新建執行緒,並處理請求
2)當池子大小等於corePoolSize,把請求放入workQueue中,池子裡的空閒執行緒就去從workQueue中取任務並處理
3)當workQueue放不下新入的任務時,新建執行緒入池,並處理請求,如果池子大小撐到了maximumPoolSize就用RejectedExecutionHandler來做拒絕處理
4)另外,當池子的執行緒數大於corePoolSize的時候,多餘的執行緒會等待keepAliveTime長的時間,如果無請求可處理就自行銷燬
內部結構如下所示:
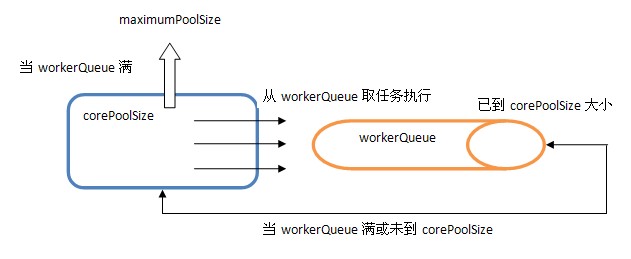
從中可以發現ThreadPoolExecutor就是依靠BlockingQueue的阻塞機制來維持執行緒池,當池子裡的執行緒無事可幹的時候就通過workQueue.take()阻塞住。
其實可以通過Executes來學學幾種特殊的ThreadPoolExecutor是如何構建的。
- publicstatic ExecutorService newFixedThreadPool(int nThreads) {
- returnnew ThreadPoolExecutor(nThreads, nThreads,
- 0L, TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue<Runnable>());
- }
newFixedThreadPool就是一個固定大小的ThreadPool
- publicstatic ExecutorService newCachedThreadPool() {
- returnnew ThreadPoolExecutor(0, Integer.MAX_VALUE,
- 60L, TimeUnit.SECONDS,
- new SynchronousQueue<Runnable>());
- }
newCachedThreadPool比較適合沒有固定大小並且比較快速就能完成的小任務,沒必要維持一個Pool,這比直接new Thread來處理的好處是能在60秒內重用已建立的執行緒。
其他型別的ThreadPool看看構建引數再結合上面所說的特性就大致知道它的特性
http://blog.csdn.net/cutesource/article/details/6061229