
使用java實現網路爬蟲
之前學習j2ee的搭建,基本完成了。
接下來想學習下爬蟲技術。要研究一項技術,首先得知道它的原理。
那麼網路爬蟲的原理是什麼呢?
網路爬蟲是一個自動提取網頁的程式,它為搜尋引擎從全球資訊網上下載網頁,是搜尋引擎的重要組成。傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的
URL,在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入佇列,直到滿足系統的一定停止條件。
接下來我會一邊研究網路爬蟲的實現,一邊記錄產生的問題和解決方案。加油吧^_^!!
這裡在網上找了個demo,先給大家看看:以下是利用Java模擬的一個程式,提取新浪頁面上的連結,存放在一個檔案裡:
package testspider; /** * Descriptions * * @version 2017年3月31日 * @since JDK1.6 * */ import java.io.BufferedReader; import java.io.FileWriter; import java.io.IOException; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.MalformedURLException; import java.net.URL; import java.net.URLConnection; import java.util.regex.Matcher; import java.util.regex.Pattern; public class WebSpider { public static void main(String[] args) { URL url = null; URLConnection urlconn = null; BufferedReader br = null; PrintWriter pw = null; String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+"; Pattern p = Pattern.compile(regex); try { url = new URL("http://www.sina.com.cn/"); urlconn = url.openConnection(); pw = new PrintWriter(new FileWriter("f:/url.txt"), true);//這裡我們把收集到的連結儲存在了E盤底下的一個叫做url的txt檔案中 br = new BufferedReader(new InputStreamReader( urlconn.getInputStream())); String buf = null; while ((buf = br.readLine()) != null) { Matcher buf_m = p.matcher(buf); while (buf_m.find()) { pw.println(buf_m.group()); } } System.out.println("獲取成功!"); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { br.close(); } catch (IOException e) { e.printStackTrace(); } pw.close(); } } }
建立一個java project把程式碼直接放到裡面,執行之後會抓取新浪的所有URL存放在本地的F:/url.txt中
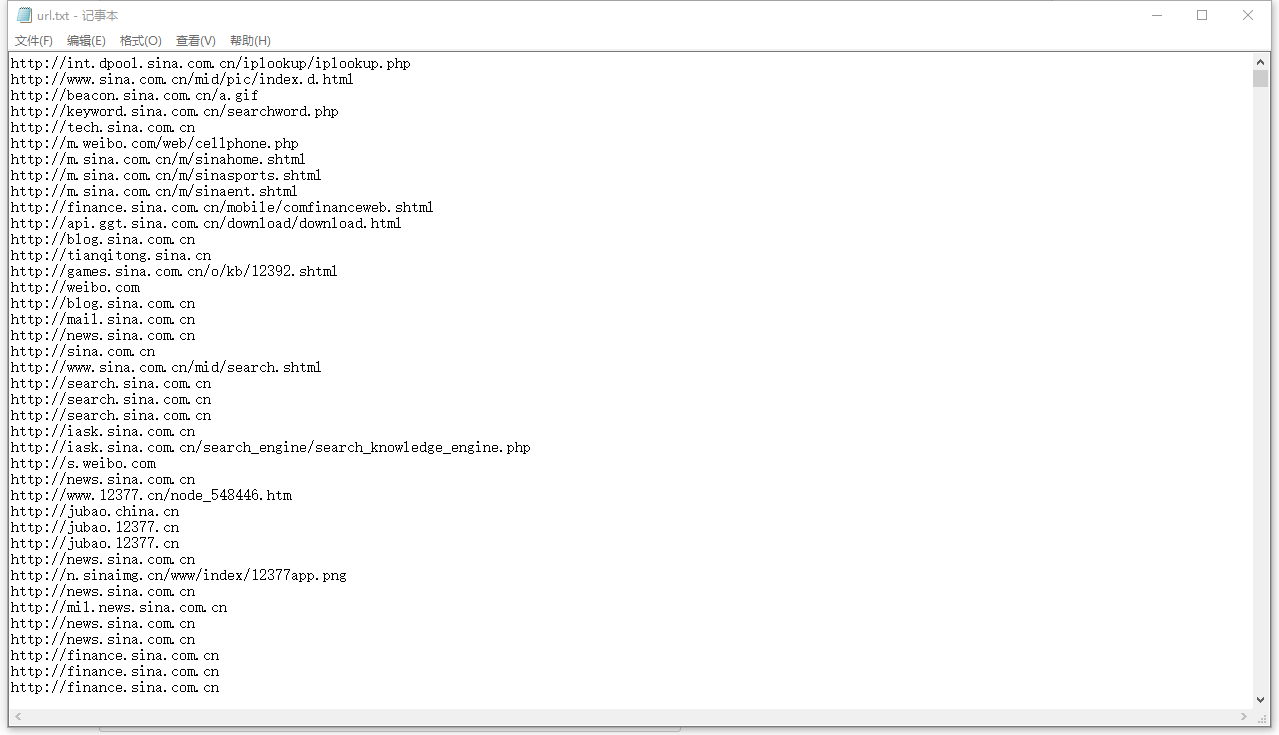
隨便選擇一條url訪問,比如http://beacon.sina.com.cn/a.gif
是可以得到圖片的,這只是爬蟲的簡單實現,接下來我會深入研究它的實現。
網路爬蟲:
開發工具:eclipse JDK1.6
從網上找的demo並沒有用到伺服器。所以我也不用伺服器了。也不涉及資料庫。把爬到的資訊儲存在本地目錄下。
首先,建一個java工程。第一個類根據URL獲取對應網頁內容。
package webspilder; import java.io.IOException; import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.HttpClient; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.DefaultHttpClient; import org.apache.http.util.EntityUtils; @SuppressWarnings("deprecation") public class DownloadPage { /** * 根據URL抓取網頁內容 * * @param url * @return */ public static String getContentFormUrl(String url) { /* 例項化一個HttpClient客戶端 */ @SuppressWarnings({"resource"}) HttpClient client = new DefaultHttpClient(); HttpGet getHttp = new HttpGet(url); String content = null; HttpResponse response; try { /*獲得資訊載體*/ response = client.execute(getHttp); HttpEntity entity = response.getEntity(); VisitedUrlQueue.addElem(url); if (entity != null) { /* 轉化為文字資訊 */ content = EntityUtils.toString(entity); /* 判斷是否符合下載網頁原始碼到本地的條件 */ if (FunctionUtils.isCreateFile(url)) //&& FunctionUtils.isHasGoalContent(content) != -1 { FunctionUtils.createFile(FunctionUtils .getGoalContent(content), url); } } } catch (ClientProtocolException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { client.getConnectionManager().shutdown(); } return content; } }
第二個類用正則表示式匹配URL,下載檔案並儲存在本地。如果有資料庫,則可以儲存在資料庫。
package webspilder; import java.io.BufferedWriter; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStreamWriter; import java.util.regex.Matcher; import java.util.regex.Pattern; public class FunctionUtils { /** * 匹配超連結的正則表示式 */ private static String pat = "http://([\\w*\\.]*[\\w*])"; private static Pattern pattern = Pattern.compile(pat); private static BufferedWriter writer = null; /** * 爬蟲搜尋深度 */ public static int depth = 0; /** * 以"/"來分割URL,獲得超連結的元素 * * @param url * @return */ public static String[] divUrl(String url) { return url.split("/"); } /** * 判斷是否建立檔案 * * @param url * @return */ public static boolean isCreateFile(String url) { Matcher matcher = pattern.matcher(url); return matcher.matches(); } /** * 建立對應檔案 * * @param content * @param urlPath */ public static void createFile(String content, String urlPath) { /* 分割url */ String[] elems = divUrl(urlPath); StringBuffer path = new StringBuffer(); File file = null; for (int i = 1; i < elems.length; i++) { if (i != elems.length - 1) { path.append(elems[i]); path.append(File.separator); file = new File("D:" + File.separator + path.toString()); } if (i == elems.length - 1) { Pattern pattern = Pattern.compile("[\\w*\\.]*[\\w*]"); Matcher matcher = pattern.matcher(elems[i]); if ((matcher.matches())) { if (!file.exists()) { file.mkdirs(); } String fileName = elems[i]; file = new File("D:" + File.separator + path.toString() + File.separator + fileName + ".html"); System.out.println("檔案儲存路徑為:"+"D:" + File.separator + path.toString() + fileName + ".html"); try { file.createNewFile(); writer = new BufferedWriter(new OutputStreamWriter( new FileOutputStream(file))); writer.write(content); writer.flush(); writer.close(); System.out.println("建立檔案成功"); } catch (IOException e) { e.printStackTrace(); } } } } } /** * 獲取頁面的超連結並將其轉換為正式的A標籤 * * @param href * @return */ public static String getHrefOfInOut(String href) { /* 內外部連結最終轉化為完整的連結格式 */ String resultHref = null; /* 判斷是否為外部連結 */ if (href.startsWith("http://")) { resultHref = href; } else { /* 如果是內部連結,則補充完整的連結地址,其他的格式忽略不處理,如:a href="#" */ if (href.startsWith("/")) { resultHref = "http://www.oschina.net" + href; } } return resultHref; } /** * 擷取網頁網頁原始檔的目標內容 * * @param content * @return */ public static String getGoalContent(String content) { int sign = content.indexOf("<html"); String signContent = content.substring(sign); int start = signContent.indexOf("<html"); int end = signContent.indexOf("</html>"); return signContent.substring(start , end+7); } /** * 檢查網頁原始檔中是否有目標檔案 * * @param content * @return */ public static int isHasGoalContent(String content) { return content.indexOf("<"); } }
獲取該URL取得頁面中,其他頁面的超連結,用於深度爬蟲和廣度爬蟲。
package webspilder;
public class HrefOfPage
{
/**
* 獲得頁面原始碼中超連結
*/
public static void getHrefOfContent(String content)
{
System.out.println("開始");
String[] contents = content.split("<a href=\"");
for (int i = 1; i < contents.length; i++)
{
int endHref = contents[i].indexOf("\"");
String aHref = FunctionUtils.getHrefOfInOut(contents[i].substring(
0, endHref));
if (aHref != null)
{
String href = FunctionUtils.getHrefOfInOut(aHref);
if (!UrlQueue.isContains(href)
&& href.indexOf("/code/explore") != -1
&& !VisitedUrlQueue.isContains(href))
{
UrlQueue.addElem(href);
}
}
}
System.out.println(UrlQueue.size() + "--抓取到的連線數");
System.out.println(VisitedUrlQueue.size() + "--已處理的頁面數");
}
}儲存未訪問過的URL,廣度爬蟲時避免重複。
package webspilder;
public class UrlDataHanding implements Runnable
{
/**
* 下載對應頁面並分析出頁面對應的URL放在未訪問佇列中。
* @param url
*/
public void dataHanding(String url)
{
HrefOfPage.getHrefOfContent(DownloadPage.getContentFormUrl(url));
}
public void run()
{
while(!UrlQueue.isEmpty())
{
dataHanding(UrlQueue.outElem());
}
}
}
儲存訪問過的URL,廣度爬蟲時避免重複。
package webspilder;
import java.util.HashSet;
/**
* 已訪問url佇列
* @author HHZ
*
*/
public class VisitedUrlQueue
{
public static HashSet<String> visitedUrlQueue = new HashSet<String>();
public synchronized static void addElem(String url)
{
visitedUrlQueue.add(url);
}
public synchronized static boolean isContains(String url)
{
return visitedUrlQueue.contains(url);
}
public synchronized static int size()
{
return visitedUrlQueue.size();
}
}
package webspilder;
/**
* Descriptions
*
* @version 2017年3月31日
* @author
* @since JDK1.6
*
*/
import java.util.LinkedList;
public class UrlQueue
{
/**超連結佇列*/
public static LinkedList<String> urlQueue = new LinkedList<String>();
/**佇列中對應最多的超連結數量*/
public static final int MAX_SIZE = 10000;
public synchronized static void addElem(String url)
{
urlQueue.add(url);
}
public synchronized static String outElem()
{
return urlQueue.removeFirst();
}
public synchronized static boolean isEmpty()
{
return urlQueue.isEmpty();
}
public static int size()
{
return urlQueue.size();
}
public static boolean isContains(String url)
{
return urlQueue.contains(url);
}
}
------------------2017.12.11補充類end-----------------------------------
主函式,執行此函式,開始爬蟲
package webspilder;
import java.sql.SQLException;
import webspilder.UrlDataHanding;
import webspilder.UrlQueue;
public class Test
{
public static void main(String[] args) throws SQLException
{
String url = "http://baidu.com";
String url1 = "http://www.sina.com.cn";
String url2 = "http://finance.qq.com";
String url3 = "http://www.mi.com";
UrlQueue.addElem(url);
UrlQueue.addElem(url1);
UrlQueue.addElem(url2);
UrlQueue.addElem(url3);
UrlDataHanding[] url_Handings = new UrlDataHanding[10];
for(int i = 0 ; i < 10 ; i++)
{
url_Handings[i] = new UrlDataHanding();
new Thread(url_Handings[i]).start();
}
}
}本文爬取百度,新浪,QQ財經和小米的網頁。成功後儲存在本地的D盤:
執行效果截圖:

我儲存成html檔案了,大家也可以儲存成txt檔案。然後檢視電腦D盤:
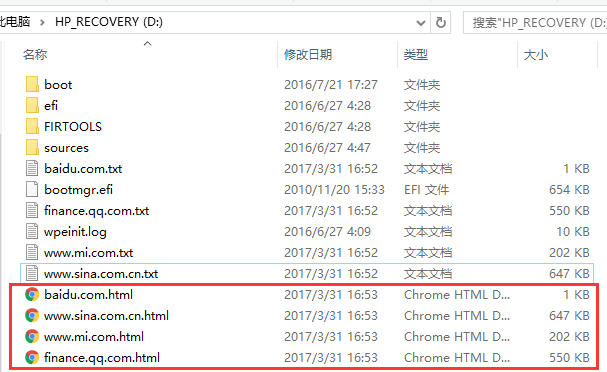
發現檔案已經儲存成功。這其中遇到的問題主要是正則表示式的書寫,這個很重要大家要注意。
到這裡只是把對應網站的頁面抓取了下來,那麼怎樣從對應頁面中獲取自己想要的資料呢?
這裡使用了java 的jsoup技術。
問題
你有一個HTML文件要從中提取資料,並瞭解這個HTML文件的結構。
方法
將HTML解析成一個Document之後,就可以使用類似於DOM的方法進行操作。示例程式碼:
File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
我們把上面接取的baidu.con.html用jsoup解析成document物件,然後使用DOM的方法接取我們想要的資料。
比如,我們想要網站中<input>標籤的內容,那就用DOM方法自己獲取把!!
最後用jsoup寫了一個簡單例子:
package webspilder;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* Descriptions
*
* @version 2017年4月1日
* @author
* @since JDK1.6
*
*/
public class Jsouptemp {
//從本地檔案中獲取
public static void getHrefByLocal()
{
File input = new File("D:\\www.mi.com.html");
Document doc = null;
try {
doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/"); //這裡後面加了網址是為了解決後面絕對路徑和相對路徑的問題
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Elements links = doc.select("a[href]");
for(Element link:links){
String linkHref = link.attr("href");
String linkText = link.text();
System.out.println(linkText+":"+linkHref);
}
}
public static void main(String[] args) {
getHrefByLocal();
}
}
得到小米官網包含的a標籤連結:
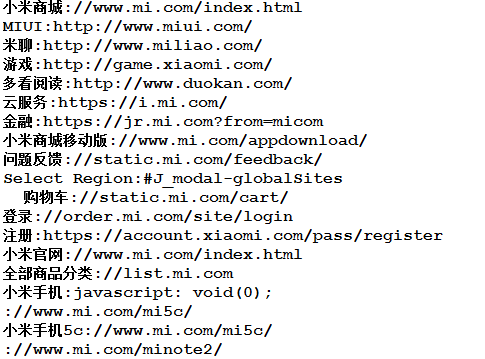
基本就到這裡啦!拜了個拜!^_^