
RNN for Image caption
RNN for image caption
v1:只記錄整體過程,沒有數學推理過程,沒有圖,寫的很隨便,全憑剛做完cs231n-assignment3的RNN第一感覺寫的
2017-12-31
具體的推導過程和一些細節,後邊看心情再補吧
圖示
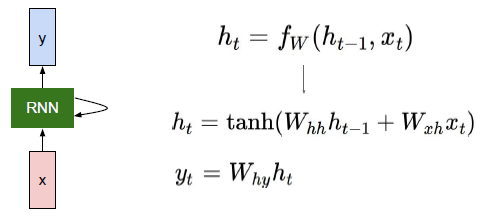
訓練
輸入
features
多來自卷積神經網路提取的影象特徵,如AGG,GoogleNet等其他網路
captions
大多來自手動標註
訓練過程
需要訓練的變數:
Wxh, Whh, b, Why, bhy
- 與上圖基本對應,不過上圖把偏置b給省了
- 這些變數在RNN傳播中的每一步是共用的
- 所以,這些變數的梯度變化,受每一步的共同影響
- 下邊的對應關係:Wxh - Wx,Whh - Wh,b - b,Why - W_vocab, by - vocab
Word embedding matrix:W_emed
- 這是,詞跟詞向量對應的一個矩陣
- 這個矩陣也是要訓練得到的,具體是什麼,要跟訓練集有關
- 一個圖片對應的caption是由一個T維向量構成的,T維向量的每一個元素i,代表的詞對應的詞向量就是W_emed第i行代表的向量
正向傳播
下面是一次輸入N個數據集的一次前向傳播過程,其中
1. features:NxH
2. caption:T維向量
3. caption_in = caption[0:T-1]
4. caption_out = caption[1:T]
整體框架
#首先對features,和caption進行處理,
#這個仿射變換affine_forward不是太理解,似乎只是多了一步,彷彿是避免讓features直接作為輸入輸入到網路中,但暫時說不出為什麼
h0,h0_cache = affine_forward(features, W_proj, b_proj)
#下面就是將每個caption_in中的單詞變成詞向量,T-1維變成T-1 x H維
#N個數據,就是 N x T-1 變成 N x T-1 x H維
data,word_cache = word_embedding_forward(captions_in,W_embed)# * rnn_forward(data,h0,Wx,Wh,b) *
如下圖,再每個單元重複執行 rnn_step_forward(x, prev_h, Wx, Wh, b)
1. 其中x是由序列決定的,每次輸入當前應該序列輪到的單詞
2. prev_h是前一個單元的輸出
3. Wx,Wh,b是每個單元公用的直接輸入一序列的資料,返回每個隱藏層的狀態
def rnn_step_forward(x, prev_h, Wx, Wh, b):
next_h = np.tanh(np.dot(x,Wx) + np.dot(prev_h,Wh) + b)
cache = (Wx, Wh, x,b, prev_h,next_h)
return next_h,cache反向傳播
整體框架
流程基本就是正向傳播過程每一步都反向來一遍
需要注意的是
1. 反向傳播的起點為前向傳播給出的dx
2. 由哪些是需要訓練的,確定反向傳播的終點
#
dhidden_states,grads['W_vocab'], grads['b_vocab'] = temporal_affine_backward(dx,cache_affine)
ddata,dh0,grads['Wx'],grads['Wh'],grads['b'] = rnn_backward(dhidden_states,cache_rnn_forward)
grads['W_embed'] = word_embedding_backward(ddata,word_cache)
_,grads['W_proj'],grads['b_proj'] = affine_backward(dh0,h0_cache)rnn_backward(data,h0,Wx,Wh,b)
如下圖,基本是每個單元重複執行 rnn_step_backward(x, prev_h, Wx, Wh, b)
但要注意rnn_backward中dWx、dWh 、db是由每一步的梯度累加得到的,就像前邊提到的一樣
def rnn_backward(dh, cache):
Wx, Wh, x, b,prev_h ,next_h= cache[0]
#Wx, Wh, x, h0,h,b = cache[0]
N,T,H = np.shape(dh)
D,_ = Wx.shape
dx = np.zeros([N,T,D])
dprev_h = np.zeros_like(prev_h)
dWh = np.zeros_like(Wh)
dWx = np.zeros_like(Wx)
db = np.zeros_like(b)
for i in range(T)[-1::-1]:#dx[:,0,:] == d1
dnext_h = dprev_h + dh[:,i,:]
dx[:,i,:], dprev_h, dWxi, dWhi, dbi = rnn_step_backward(dnext_h, cache[i])
dnext_h = dh[:,i,:]
dWx = dWx + dWxi
dWh = dWh + dWhi
db = db + dbi
dh0 = dprev_h
return dx, dh0, dWx, dWh, db
def rnn_step_backward(dnext_h, cache):
dx, dprev_h, dWx, dWh, db = None, None, None, None, None
Wx, Wh, x, b,prev_h ,next_h= cache
der = 1.0 - next_h**2
middle = der*dnext_h
dx = middle.dot(Wx.T)
dprev_h = middle.dot(Wh.T)
dWx = x.T.dot(middle)
dWh = prev_h.T.dot(middle)
db = middle.sum(axis = 0)
return dx, dprev_h, dWx, dWh, db
測試過程
輸入
基本流程就是將,正向傳播的過程實現一邊
但還有一些細節
後邊補充吧