
機器學習與深度學習系列連載: 第二部分 深度學習(十一)卷積神經網路 2 Why CNN for Image?
阿新 • • 發佈:2018-11-12
卷積神經網路 2 Why CNN
為什麼處理圖片要用CNN?

原因是:
- 一個神經元無法看到整張圖片
- 能夠聯絡到小的區域,並且引數更少
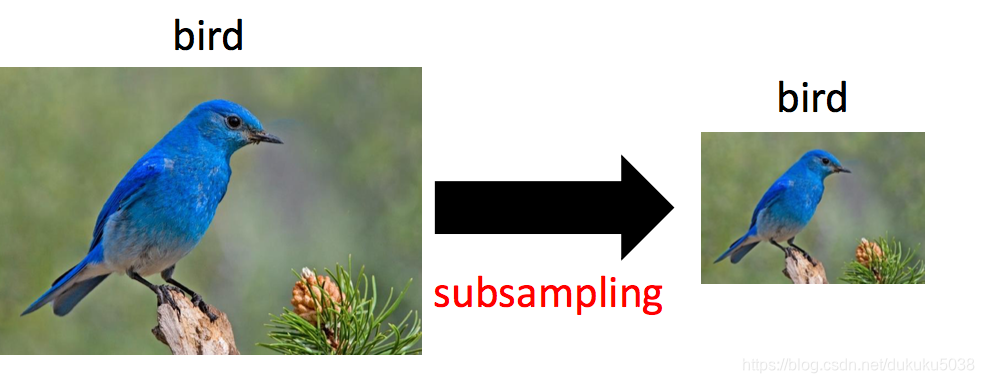
- 圖片壓縮畫素不改變圖片內容
1. CNN 的特點
- 卷積: 一些卷積核遠遠小於圖片大小; 同樣的pattern 已在圖片的不同區域出現
- 抽樣:抽樣壓縮,不影響圖片的含義
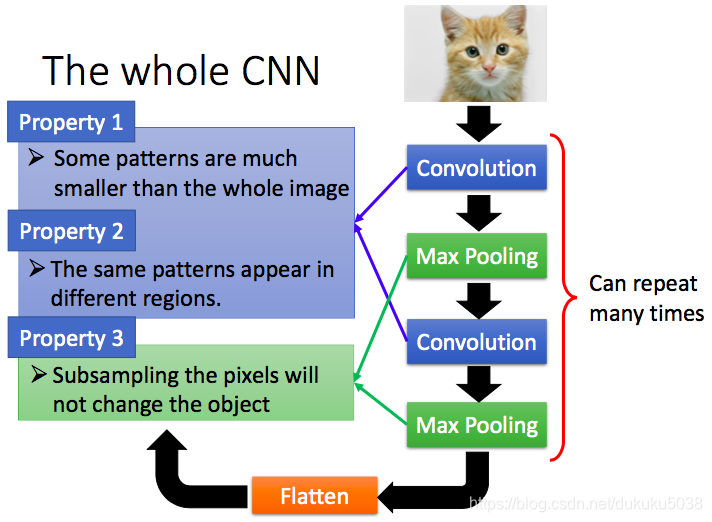
2. CNN 為什麼適用於圖片處理?
一般來講,單層神經網路可以表示任何函式(數學已經證明),那麼我們為什麼不用全連線神經網路,而用複雜的,人為設計的CNN取處理圖片呢?祕密在於,CNN能夠大量減少引數,提高效率。
(1)模型比較
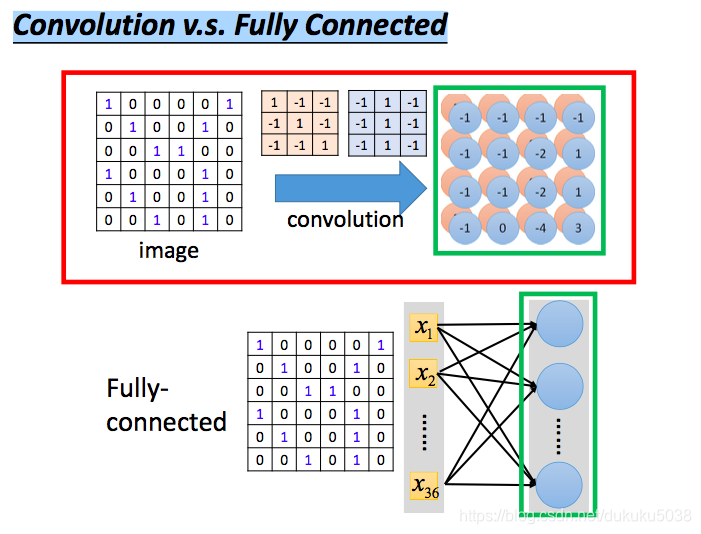
(2)減參祕密
我們拿6*6大小的圖片為例,filter是3*3,filter中每個引數是一個引數,用不同的顏色表示,就會生成activemap,粉色表示的圖層
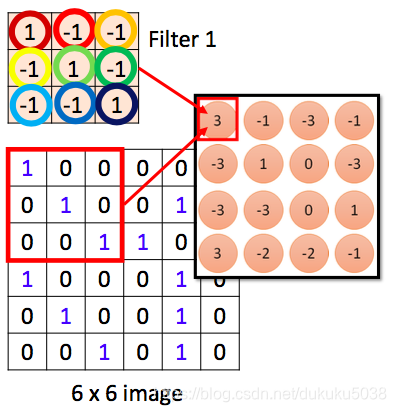
以activemap 中第一個數值3為例,在全連線網路中(完全展開CNN),至少需要16個引數,但是隻需要9個輸入。

3. CNN in Keras
(1)圖片輸入Input需要reshape到3D 的tensor
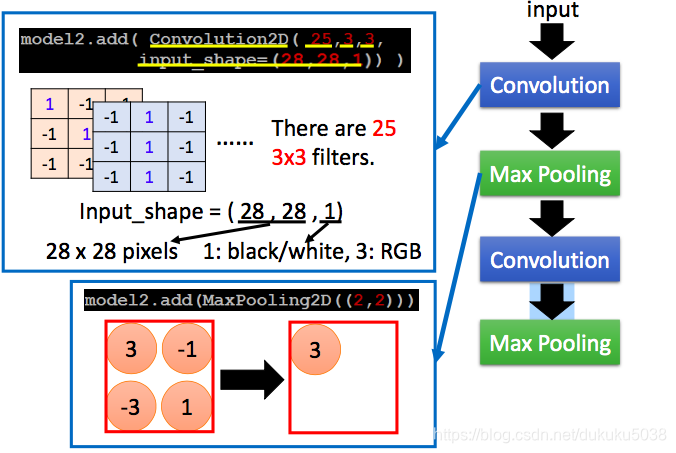
(2)繼續新增maxpooling 和convolution層
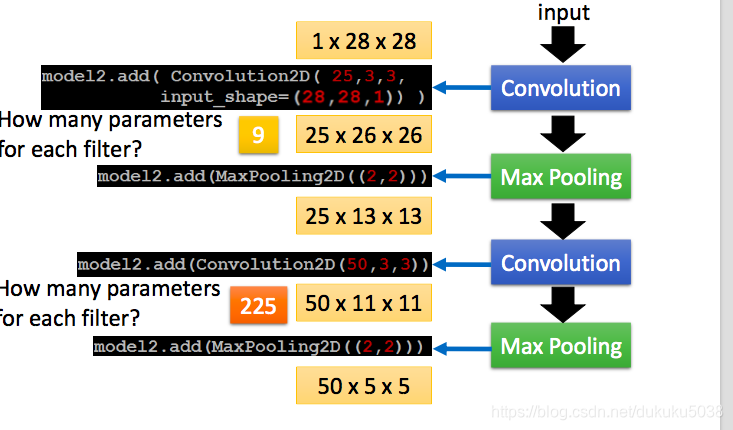
(3)展開用全連線層,softmax輸出分類結果
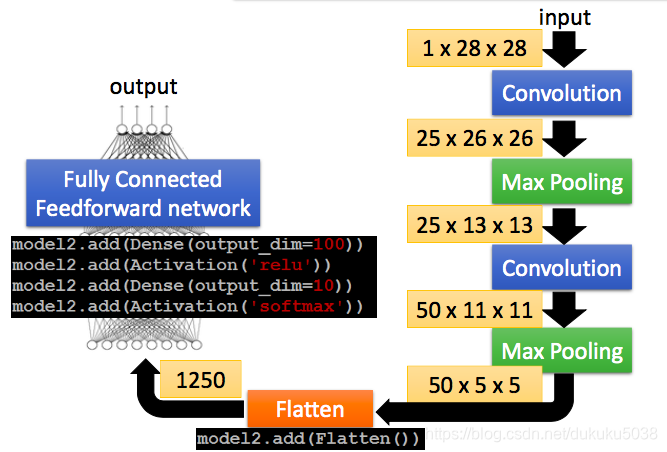
本專欄圖片、公式很多來自臺灣大學李弘毅老師、斯坦福大學cs229,斯坦福大學cs231n 、斯坦福大學cs224n課程。在這裡,感謝這些經典課程,向他們致敬!