
R+python︱XGBoost極端梯度上升以及forecastxgb(預測)+xgboost(迴歸)雙案例解讀
XGBoost不僅僅可以用來做分類還可以做時間序列方面的預測,而且已經有人做的很好,可以見最後的案例。
應用一:XGBoost用來做預測
——————————————————————————————————————————————————
一、XGBoost來歷
xgboost的全稱是eXtreme Gradient Boosting。正如其名,它是Gradient Boosting Machine的一個c++實現,作者為正在華盛頓大學研究機器學習的大牛陳天奇。他在研究中深感自己受制於現有庫的計算速度和精度,因此在一年前開始著手搭建xgboost專案,並在去年夏天逐漸成型。xgboost最大的特點在於,它能夠自動利用CPU的多執行緒進行並行,同時在演算法上加以改進提高了精度。它的處女秀是Kaggle的
為了方便大家使用,陳天奇將xgboost封裝成了python庫。我有幸和他合作,製作了xgboost工具的R語言介面,並將其提交到了CRAN上。也有使用者將其封裝成了julia庫。python和R介面的功能一直在不斷更新,大家可以通過下文了解大致的功能,然後選擇自己最熟悉的語言進行學習。
(非本部落格主,詳細可見參考文獻)
————————————————————————————————————————————
二、優勢、價效比
大致其有三個優點:高效、準確度、模型的互動性。
1、高效
xgboost藉助OpenMP,能自動利用單機CPU的多核進行平行計算
Mac上的Clang對OpenMP的支援較差,所以預設情況下只能單核執行
xgboost自定義了一個數據矩陣類DMatrix,會在訓練開始時進行一遍預處理,從而提高之後每次迭代的效率
它類似於梯度上升框架,但是更加高效。它兼具線性模型求解器和樹學習演算法。因此,它快速的祕訣在於演算法在單機上也可以平行計算的能力。這使得xgboost至少比現有的梯度上升實現有至少10倍的提升。它提供多種目標函式,包括迴歸,分類和排序。
2、準確性
準確度提升的主要原因在於,xgboost的模型和傳統的GBDT相比加入了對於模型複雜度的控制以及後期的剪枝處理,使得學習出來的模型更加不容易過擬合。
由於它在預測效能上的強大但是相對緩慢的實現,"xgboost" 成為很多比賽的理想選擇。它還有做交叉驗證和發現關鍵變數的額外功能。在優化模型時,這個演算法還有非常多的引數需要調整。
3、模型的互動性
能夠求出目標函式的梯度和Hessian矩陣,使用者就可以自定義訓練模型時的目標函式
允許使用者在交叉驗證時自定義誤差衡量方法,例如迴歸中使用RMSE還是RMSLE,分類中使用AUC,分類錯誤率或是F1-score。甚至是在希格斯子比賽中的“奇葩”衡量標準AMS
交叉驗證時可以返回模型在每一折作為預測集時的預測結果,方便構建ensemble模型。
允許使用者先迭代1000次,檢視此時模型的預測效果,然後繼續迭代1000次,最後模型等價於一次性迭代2000次
可以知道每棵樹將樣本分類到哪片葉子上,facebook介紹過如何利用這個資訊提高模型的表現
可以計算變數重要性並畫出樹狀圖
可以選擇使用線性模型替代樹模型,從而得到帶L1+L2懲罰的線性迴歸或者logistic迴歸
————————————————————————————————————————————
三、用R語言實現Xgboost案例
1、如何實現?
看到在Python和R上都有自己的package。
R中直接install.packages即可。也可以從github上呼叫:
devtools::install_github('dmlc/xgboost',subdir='R-package')
但是,注意!! XGBoost僅適用於數值型向量。是的!你需要使用中區分資料型別。如果是名義,比如“一年級”、“二年級”之類的,需要變成啞變數,然後進行後續的處理。
XGBoost有自己獨有的資料結構,將資料數值化,可以進行稀疏處理。極大地加快了運算。這種獨特的資料結構得著重介紹一下。
2、one-hot encode 獨熱編碼——獨有的資料結構
這個詞源於數位電路語言,這意味著一個數組的二進位制訊號,只有合法的值是0和1。
在R中,一個獨熱編碼非常簡單。這一步(如下所示)會在每一個可能值的變數使用標誌建立一個稀疏矩陣。稀疏矩陣是一個矩陣的零的值。稀疏矩陣是一個大多數值為零的矩陣。相反,一個稠密矩陣是大多數值非零的矩陣。
sparse_matrix <- Matrix::sparse.model.matrix(response ~ .-1, data = campaign)現在讓我們分解這個程式碼如下:
-
sparse.model.matrix這條命令的圓括號裡面包含了所有其他輸入引數。 -
引數“反應”說這句話應該忽略“響應”變數。
-
“-1”意味著該命令會刪除矩陣的第一列。
-
最後你需要指定資料集名稱。
其中這個-1很有意思,response代表因變數,那麼為什麼還要“-1”,刪去第一列?
答:這個根據題意自己調整,此時的-1可能是需要分拆的變數,比如此時第一列變數名稱是“治療”,其中是二分類,“治療”與“安慰劑治療”。此時的-1代表把這個變數二分類變成兩個變數,一個變數為“是否治療”,另外一個是“是否安慰劑治療”,那麼就由一個名義變數轉化成了0-1數值型變量了。
想要轉化目標變數,你可以使用下面的程式碼:
output_vector = df[,response] == "Responder"程式碼解釋:
-
設 output_vector 初值為0。
-
在 output_vector 中,將響應變數的值為 "Responder" 的數值設為1;
-
返回 output_vector。
3、XGBoost數之不盡的引數
XGBoost的引數超級多,詳情可以看:官方解釋網站
它有三種類型的引數:通用引數、輔助引數和任務引數。
-
通用引數為我們提供在上升過程中選擇哪種上升模型。常用的是樹或線性模型。
-
輔助引數取決於你選擇的上升模型。
-
任務引數,決定學習場景,例如,迴歸任務在排序任務中可能使用不同的引數。
讓我們詳細瞭解這些引數。我需要你注意,這是實現xgboost演算法最關鍵的部分:
一般引數
-
silent : 預設值是0。您需要指定0連續列印訊息,靜默模式1。
-
booster : 預設值是gbtree。你需要指定要使用的上升模型:gbtree(樹)或gblinear(線性函式)。
-
num_pbuffer : 這是由xgboost自動設定,不需要由使用者設定。閱讀xgboost文件的更多細節。
-
num_feature : 這是由xgboost自動設定,不需要由使用者設定。
輔助引數
具體引數樹狀圖:
-
eta:預設值設定為0.3。您需要指定用於更新步長收縮來防止過度擬合。每個提升步驟後,我們可以直接獲得新特性的權重。實際上 eta 收縮特徵權重的提高過程更為保守。範圍是0到1。低η值意味著模型過度擬合更健壯。
-
gamma:預設值設定為0。您需要指定最小損失減少應進一步劃分樹的葉節點。更大,更保守的演算法。範圍是0到∞。γ越大演算法越保守。
-
max_depth:預設值設定為6。您需要指定一個樹的最大深度。引數範圍是1到∞。
-
min_child_weight:預設值設定為1。您需要在子樹中指定最小的(海塞)例項權重的和,然後這個構建過程將放棄進一步的分割。線上性迴歸模式中,在每個節點最少所需例項數量將簡單的同時部署。更大,更保守的演算法。引數範圍是0到∞。
-
max_delta_step:預設值設定為0。max_delta_step 允許我們估計每棵樹的權重。如果該值設定為0,這意味著沒有約束。如果它被設定為一個正值,它可以幫助更新步驟更為保守。通常不需要此引數,但是在邏輯迴歸中當分類是極為不均衡時需要用到。將其設定為1 - 10的價值可能有助於控制更新。引數範圍是0到∞。
-
subsample: 預設值設定為1。您需要指定訓練例項的子樣品比。設定為0.5意味著XGBoost隨機收集一半的資料例項來生成樹來防止過度擬合。引數範圍是0到1。
-
colsample_bytree : 預設值設定為1。在構建每棵樹時,您需要指定列的子樣品比。範圍是0到1。
-
colsample_bylevel:預設為1
-
max_leaf_nodes:葉結點最大數量,預設為2^6
線性上升具體引數
-
lambda and alpha : L2正則化項,預設為1、L1正則化項,預設為1。這些都是正則化項權重。λ預設值假設是1和α= 0。
-
lambda_bias : L2正則化項在偏差上的預設值為0。
-
scale_pos_weight:加快收斂速度,預設為1
任務引數
-
base_score : 預設值設定為0.5。您需要指定初始預測分數作為全域性偏差。
-
objective : 預設值設定為reg:linear。您需要指定你想要的型別的學習者,包括線性迴歸、邏輯迴歸、泊松迴歸等。
-
eval_metric : 您需要指定驗證資料的評估指標,一個預設的指標分配根據客觀(rmse迴歸,錯誤分類,意味著平均精度等級
-
seed : 隨機數種子,確保重現資料相同的輸出。
4、具體案例——官方案例 discoverYourData
案例的主要內容是:服用安慰劑對病情康復的情況,其他指標還有年齡、性別。
(1)資料匯入與包的載入
操作時對包的要求,在載入的時候也會一些報錯。後面換了版本就OK了。
require(xgboost)
require(Matrix)
require(data.table)
if (!require('vcd')) install.packages('vcd')
data(Arthritis)
df <- data.table(Arthritis, keep.rownames = F)
接下來對資料進行一些處理。
head(df[,AgeDiscret := as.factor(round(Age/10,0))]) #:= 新增加一列
head(df[,AgeCat:= as.factor(ifelse(Age > 30, "Old", "Young"))]) #ifelse
df[,ID:=NULL]
首先看一下這個程式碼寫的很棒,比如:ifelse的用法,以及:=用法(直接在[]框中對資料進行一定操作)
(2)生成特定的資料格式
sparse_matrix <- sparse.model.matrix(Improved~.-1, data = df) #變成稀疏資料,然後0變成.,便於佔用記憶體最小
生成了one-hot encode資料,獨熱編碼。Improved是Y變數,-1是將treament變數(名義變數)拆分。
(3)設定因變數(多分類)
output_vector = df[,Improved] == "Marked" (4)xgboost建模
bst <- xgboost(data = sparse_matrix, label = output_vector, max.depth = 4,
eta = 1, nthread = 2, nround = 10,objective = "binary:logistic")其中nround是迭代次數,可以用此來調節過擬合問題;
nthread代表執行執行緒,如果不指定,則表示執行緒全開;
objective代表所使用的方法:binary:logistic是以非線性的方式,分支。reg:linear(預設)、reg:logistic、count:poisson(泊松分佈)、multi:softmax
(5)特徵重要性排名
importance <- xgb.importance([email protected][[2]], model = bst)
head(importance)
會出來比較多的指標,Gain是增益,樹分支的主要參考因素;cover是特徵觀察的相對數值;Frequence是gain的一種簡單版,他是在所有生成樹中,特徵的數量(慎用!)
(6)特徵篩選與檢驗
知道特徵的重要性是一回事兒,現在想知道年齡對最後的治療的影響。所以需要可以用一些方式來反映出來。以下是官方自帶的。
importanceRaw <- xgb.importance([email protected][[2]], model = bst, data = sparse_matrix, label = output_vector)
# Cleaning for better display
importanceClean <- importanceRaw[,`:=`(Cover=NULL, Frequence=NULL)] #同時去掉cover frequence
head(importanceClean)
比第一種方式多了split列,代表此時特徵分割的界線,比如特徵2: Age 61.5,代表分割在61.5歲以下治療了就痊癒了。同時,多了RealCover 和RealCover %列,前者代表在這個特徵的個數,後者代表個數的比例。
繪製重要性圖譜:
xgb.plot.importance(importance_matrix = importanceRaw)
需要載入install.packages("Ckmeans.1d.dp"),其中輸出的是兩個特徵,這個特徵數量是可以自定義的,可以定義為10族。
變數之間影響力的檢驗,官方用的卡方檢驗:
c2 <- chisq.test(df$Age, output_vector)
檢驗年齡對最終結果的影響。
(7)疑問?
#Random Forest™ - 1000 trees
bst <- xgboost(data = train$data, label = train$label, max.depth = 4, num_parallel_tree = 1000, subsample = 0.5, colsample_bytree =0.5, nround = 1, objective = "binary:logistic")
#num_parallel_tree這個是什麼?
#Boosting - 3 rounds
bst <- xgboost(data = train$data, label = train$label, max.depth = 4, nround = 3, objective = "binary:logistic")
#???代表boosting
話說最後有一個疑問,這幾個程式碼是可以區分XGBoost、隨機森林以及boosting嗎?
(8)一些進階功能的嘗試
作為比賽型演算法,真的超級好。下面列舉一些我比較看中的功能:
1、交叉驗證每一折顯示預測情況
挑選比較優質的驗證集。
# do cross validation with prediction values for each fold
res <- xgb.cv(params = param, data = dtrain, nrounds = nround, nfold = 5, prediction = TRUE)
res$evaluation_log
length(res$pred)交叉驗證時可以返回模型在每一折作為預測集時的預測結果,方便構建ensemble模型。
2、迴圈迭代
允許使用者先迭代1000次,檢視此時模型的預測效果,然後繼續迭代1000次,最後模型等價於一次性迭代2000次。
# do predict with output_margin=TRUE, will always give you margin values before logistic transformation
ptrain <- predict(bst, dtrain, outputmargin=TRUE)
ptest <- predict(bst, dtest, outputmargin=TRUE)
3、每棵樹將樣本分類到哪片葉子上
# training the model for two rounds
bst = xgb.train(params = param, data = dtrain, nrounds = nround, nthread = 2)
4、線性模型替代樹模型
可以選擇使用線性模型替代樹模型,從而得到帶L1+L2懲罰的線性迴歸或者logistic迴歸。
# you can also set lambda_bias which is L2 regularizer on the bias term
param <- list(objective = "binary:logistic", booster = "gblinear",
nthread = 2, alpha = 0.0001, lambda = 1)——————————————————————————————————————————————————
四、用Python實現XGBoost
官方文件路徑:Python API Reference,作者使用的是python3,跟py2的一些code可能有些區別
!pip3 install xgboost
import xgboost as xgb即可對付多分類也可以對付迴歸。如果是分類的話,就是: xgb.XGBClassifier(),其他基本沒差。
主要嘗試了迴歸,就來簡單說說迴歸,主要引數:
XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True, objective='reg:linear', booster='gbtree', n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)可以看到objective='reg:linear'代表線性迴歸。
1、XGBoost迴歸案例
其中一個簡單模型擬合案例:
from sklearn.metrics import confusion_matrix, mean_squared_error
import xgboost as xgb
gbm = xgb.XGBRegressor().fit(data.ix[:,25:], data['y'])
predictions = gbm.predict(data.ix[:,25:])
actuals = data['y']
print(mean_squared_error(actuals, predictions))data就是一個普通的dataframe格式,其中'y'就是因變數,然後可以直接fit擬合函式。
最後,輸出mean_squared_error平方誤差,衡量模型預測好壞。
2、畫出XGBoost節點圖
如果y是分類變數,可以直接畫出節點圖:
from matplotlib import pyplot
from xgboost import plot_tree
plot_tree(gbm, num_trees=0, rankdir='LR')
pyplot.show()可以直接通過plot_tree畫出節點圖,但是plot_tree很醜,很模糊!
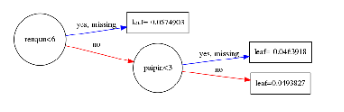
一種解決方案,參考https://github.com/dmlc/xgboost/issues/1725:
xgb.plot_tree(bst, num_trees=2)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(150, 100)
fig.savefig('tree.png')於是乎,就需要來一張清晰一些的圖片還有一種畫法如下:
xgb.to_graphviz(gbm, num_trees=80, rankdir='LR')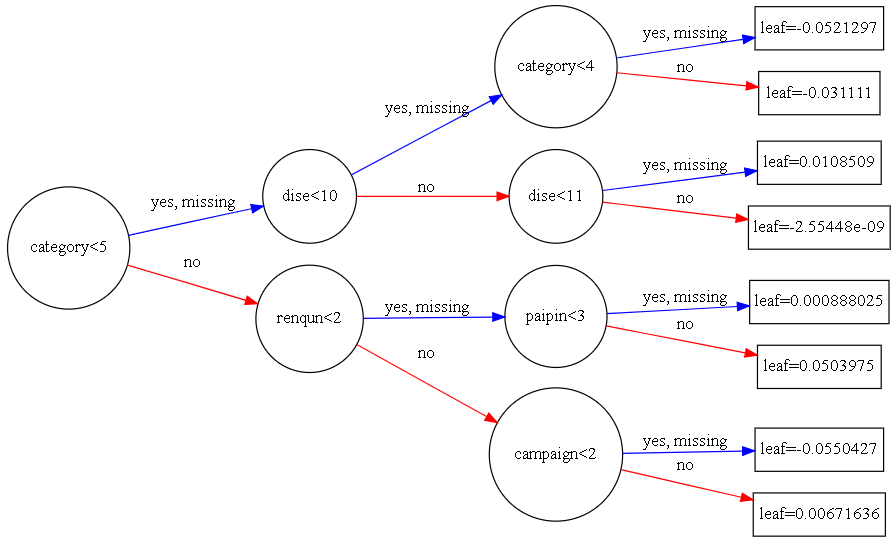
來觀察一下圖型:
其中分支代表,category<5,兩條路,代表條件成立,yes;條件不成立,no
每個節點都帶有節點名,但是圓圈的大小,有人說是樣本量越大,圓圈越大,也有可能是根據節點名稱的多少來劃定。
引數介面:https://xgboost.readthedocs.io/en/latest/python/python_api.html
3、模型中指標的重要性輸出
XGBoost模型中的三種重要性:Gain是增益,樹分支的主要參考因素; cover是特徵觀察的相對數值; Frequence是gain的一種簡單版,他是在所有生成樹中,特徵的數量
'weight' - the number of times a feature is used to split the data across all trees. 'gain' - the average gain of the feature when it is used in trees 'cover' - the average coverage of the feature when it is used in trees
直接畫出:
from xgboost import plot_importance
from matplotlib import pyplot
plot_importance(gbm,importance_type = 'cover')
pyplot.show()其中importance_type = 'cover',也可以等於'weight'以及'gain'
但是這輸出的是圖片,如何獲得重要性的List數值?

——應用get_socre()
gbm.booster().get_score(importance_type='gain')4、調參工具
GridSearchCV 來進行調參會更方便一些:
可以調的超引數組合有:
樹的個數和大小 (n_estimators and max_depth).
學習率和樹的個數 (learning_rate and n_estimators).
行列的 subsampling rates (subsample, colsample_bytree and colsample_bylevel).
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
設定要調節的 learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
和原始碼相比就是在 model 後面加上 grid search 這幾行:
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X, Y)
最後會給出最佳的學習率為 0.1
Best: -0.483013 using {'learning_rate': 0.1}
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
我們還可以用下面的程式碼打印出每一個學習率對應的分數:
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
-0.689650 (0.000242) with: {'learning_rate': 0.0001}
-0.661274 (0.001954) with: {'learning_rate': 0.001}
-0.530747 (0.022961) with: {'learning_rate': 0.01}
-0.483013 (0.060755) with: {'learning_rate': 0.1}
-0.515440 (0.068974) with: {'learning_rate': 0.2}
-0.557315 (0.081738) with: {'learning_rate': 0.3}
————————————————————————————————————————————————————————————
應用一:XGBoost用來做預測
R語言中XGBoost用來做預測的新包,forecastxgb來看看一個簡單的案例。
devtools::install_github("ellisp/forecastxgb-r-package/pkg")
以上是包的載入,是在github上面的。
一個官方的案例是:
library(forecastxgb)
model <- xgbts(gas)
summary一下就可以看到以下的內容:
summary(model)
Importance of features in the xgboost model:
Feature Gain Cover Frequence
1: lag12 4.866644e-01 0.126320210 0.075503356
2: lag11 2.793567e-01 0.049217848 0.035234899
3: lag13 1.044469e-01 0.037102362 0.030201342
4: lag24 7.987905e-02 0.150929134 0.080536913
5: time 2.817163e-02 0.125291339 0.077181208
6: lag1 1.190114e-02 0.131002625 0.152684564
7: lag23 5.306595e-03 0.015685039 0.018456376
8: lag2 7.431663e-04 0.072188976 0.063758389
9: lag14 5.801733e-04 0.014152231 0.021812081
10: lag6 4.071911e-04 0.013480315 0.031879195
11: lag18 3.345186e-04 0.026120735 0.021812081
12: lag5 2.781746e-04 0.023244094 0.043624161
13: lag16 2.564357e-04 0.012262467 0.020134228
14: lag17 2.067079e-04 0.011128609 0.021812081
15: lag21 1.918721e-04 0.015769029 0.023489933
16: lag4 1.698715e-04 0.012703412 0.036912752
17: lag22 1.417012e-04 0.019485564 0.025167785
18: lag19 1.291178e-04 0.009511811 0.016778523
19: lag20 1.188570e-04 0.005312336 0.010067114
20: lag8 1.115240e-04 0.016629921 0.023489933
21: lag9 1.051375e-04 0.021375328 0.026845638
22: lag10 1.035566e-04 0.036829396 0.035234899
23: season7 1.008707e-04 0.006950131 0.008389262
24: lag7 8.698124e-05 0.007097113 0.021812081
25: lag3 7.582023e-05 0.006740157 0.038590604
26: lag15 6.305601e-05 0.006677165 0.013422819
27: season4 5.440121e-05 0.001805774 0.003355705
28: season5 7.204729e-06 0.002918635 0.008389262
29: season8 3.280837e-06 0.003422572 0.003355705
30: season6 2.090122e-06 0.008923885 0.005033557
31: season10 1.287062e-06 0.007307087 0.001677852
32: season12 5.436832e-07 0.002414698 0.003355705
Feature Gain Cover Frequence
36 features considered.
476 original observations.
452 effective observations after creating lagged features.
建好模之後就是進行預測:
fc <- forecast(model, h = 12)
plot(fc)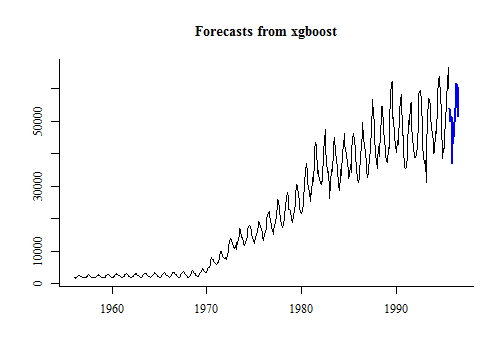
如果有額外的自變數需要加入:
library(fpp)
consumption <- usconsumption[ ,1]
income <- matrix(usconsumption[ ,2], dimnames = list(NULL, "Income"))
consumption_model <- xgbts(y = consumption, xreg = income)
Stopping. Best iteration: 20
預測以及畫圖:
income_future <- matrix(forecast(xgbts(usconsumption[,2]), h = 10)$mean,
dimnames = list(NULL, "Income"))
Stopping. Best iteration: 1
plot(forecast(consumption_model, xreg = income_future))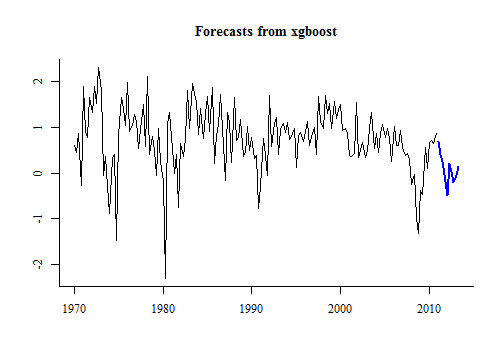
季節調整
三種處理季節的方式。
第一種:把季節效應變成啞變數處理;
第二種:季節調整方式,乘法效應(計量中還有加法效應)。
第三種:傅立葉變換後的變數當做X,作為變數
來看看具體效果,不過三款模型都不好,因為存在趨勢項,沒有做平穩處理。
類似BOX-COX資料變換
在negative資料上使用資料變換,預設值為BoxCox.lambda(abs(y))
不過,目前為止資料轉換並沒有很好地強化模型的效能
非平穩的情況
較多使用ARIMA來進行趨勢預測
model <- xgbar(AirPassengers, trend_method = "differencing", seas_method = "fourier")
plot(forecast(model, 24))
未來的進展:
一些特殊時間點的加入,交易日、復活節
加入向量自迴歸模型
更好的封裝,譬如傅立葉變換等
——————————————————————————————————————
參考文獻
XGBoost的PPT材料:https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
——————————————————————————————————————
延伸一:來看看LightGBM和XGboosting的差異:
XGBoost是一款經過優化的分散式梯度提升(Gradient Boosting)庫,具有高效,靈活和高可移植性的特點。基於梯度提升框架,XGBoost實現了並行方式的決策樹提升(Tree Boosting),從而能夠快速準確地解決各種資料科學問題。
LightGBM(Light Gradient Boosting Machine)同樣是一款基於決策樹演算法的分散式梯度提升框架。
1. 速度:速度上xgboost 比LightGBM在慢了10倍
2. 呼叫核心效率:隨著執行緒數的增加,比率變小了。這也很容易解釋,因為你不可能讓執行緒的利用率是100%,執行緒的切入切出以及執行緒有時要等待,這都需要耗費很多時間。保持使用邏輯核心建立一定量的執行緒,並且不要超過該數。不然反而速度會下降。
3. 記憶體佔用:xgboost:約 1684 MB;LightGBM: 1425 MB,LightGBM在訓練期間的RAM使用率較低,但是記憶體中資料的RAM使用量增加
相關推薦
R+python︱XGBoost極端梯度上升以及forecastxgb(預測)+xgboost(迴歸)雙案例解讀
XGBoost不僅僅可以用來做分類還可以做時間序列方面的預測,而且已經有人做的很好,可以見最後的案例。 應用一:XGBoost用來做預測 ———————————————————————————————————————
Python中 with open(file_abs,'r') as f: 的用法以及意義
轉自https://www.cnblogs.com/tianyiliang/p/8192703.html Python內建了讀寫檔案的函式,用法和C是相容的。本節介紹內容大致有:檔案的開啟/關閉、檔案物件、檔案的讀寫等。 本章節僅示例介紹 TXT 型別文件的讀寫,也就是最基礎的檔案讀寫,
Python機器學習演算法實踐——梯度上升演算法
一:理論部分 給定一個樣本集,每個樣本點有兩個維度值(X1,X2)和一個類別值,類別只有兩類,我們以0和1代表。資料如下所示: 樣本 X1 X2 類別 1
Python 叠代器協議以及可叠代對象、叠代器對象
統一 for循環 無法 缺點 import ins 一個 需要 實現 一、叠代器協議定義: 叠代:是一個重復的過程,每一次重復,都是基於上一次的結果而來 while True: #單純的重復 print(‘你瞅啥‘) l=[‘a‘,‘b‘,‘c‘,‘d‘]
Python模塊詳解以及import本質,獲得文件當前路徑os.path.abspath,獲得文件的父目錄os.path.dirname,放到系統變量的第一位sys.path.insert(0,x)
alt 獲取 詳解 nbsp spa 絕對路徑 解釋 系統 port 模塊介紹 1、定義: 模塊:用來從邏輯上組織python代碼(變量,函數,類,邏輯:實現一個功能),本質就是.py結尾的python文件(文件名:test.py,對應的模塊名:test) 包:用來從邏輯上
檢測Python項目依賴包以及版本
bsp $2 bin xargs imp gre div one awk #!/bin/env/bash find . -type f |grep py|xargs grep -E ‘^from|^import‘| awk -F "py:" {‘print $2‘}|so
[python] 連接MySQL,以及多線程、多進程連接MySQL續
python mysqldb dbutils pooleddb之前參照他人的做法,使用DBUtils.PooledDB來建立多個可復用的MySQL連接,部分文章有誤,方法不當,導致我走了很多彎路,專研幾天後,終於找到了正確的使用方法。網上有很多使用DBUtils.PooledDB模塊建立連接池,再加threa
【轉載】Python操作Excel的讀取以及寫入
body .sh open 列數 讀取 efault jin rap ring 轉載來源:https://jingyan.baidu.com/article/e2284b2b754ac3e2e7118d41.html #導入包 import xlrd #設置路徑 path
python 強制類型轉換 以及 try expect
一個 去掉 esc spa 指定 強制 urn try rto 強制類型轉換: 字符串 --> 整型: 字符串 第一個 是 + 或者 - ,會直接去掉 符號 ,返回 數字 如: 1 a = ‘+123456‘ 2 s = int(a) 3
python---redis在windows安裝以及測試
pri 實現 oca imp AR 兩個 python 安裝 cal pan 手冊以及下載地址http://www.runoob.com/redis/redis-install.html,以及啟動和測試 python 安裝redis模塊 pip3 install redi
Python之變量用法以及字符串
擴展 color 行修改 體會 分隔 person 命名 語法 python代碼 運行hello_world.py時發生的情況 創建一個hello_world.py文件寫入一句代碼如下: #!/usr/bin/env python # -*- coding:utf8
Python數據功能轉義以及運算符總結-ten day
mage inf pen 切片 known 意思 rep 邏輯運算 是否 一、賦值運算符 賦值運算把a的值,經過運算,把運算結果賦值給b。 二、比較運算符 比較運算的結果返回的值是bool值,為True和False,一般用來控制程序執行的流程,比如說下面的代碼: 1
以非root身份安裝Python的Module或者Package以及pip安裝指定路徑
指定 packages string 沒有 ID lib pip安裝 ges roo 因為要遠程訪問公司的服務器,沒有sudo的權限,所以在安裝python的一些包的時候就不能安去默認路徑了(比如以/usr/local/lib/為prefix的路徑)。
R python在無圖形用戶界面時保存圖片
less 其他 art 導入 AI tails lib .net 作圖 在用python的matplotlib,和R中自帶的作圖,如果想保存圖片時,當你有圖形用戶界面時是沒有問題的,但是當沒有圖形用戶界面時,會報錯: 在R中,解決辦法: https://blog.csd
python項目結構規範以及文件之間的調用
pat width wid 維護 open ef7 welcom ID docs 規範的結構用途: 1.可讀性高 2.可維護性高 簡要介紹文件: 1.bin/:存放項目的一些可執行文件,當然你可以起名acript/之類的 2.foo/:存放項目的源代碼:
Python字符串相加以及字符串格式化
字符串 內存地址 nbsp 占位符 aos 3.1 小數 code format 1、在Python中字符串a占用一塊內存地址,字符串b也占用一塊內存地址,當字符串a+b時,又會在內存空間中開辟一塊新的地址用來存放a+b。 a 地址一 b 地址二 a+b 地址三
python深淺拷貝,集合以及數據類型的補充
指向 最好 大小 epc app 列表 keys hang 變化 1.基礎數據類型的補充 1.元組 如果元組中只有一個數據,且沒有逗號,則該‘元組’與裏面的數據的類型相同。如: 1 tu = (1) 2 tu1 = (1,) 3 tu2 = (‘alex‘) 4 tu3
機器學習(七) PCA與梯度上升法 (下)
實例 此外 tps 新的 get nsf self. -s 冗余 五、高維數據映射為低維數據 換一個坐標軸。在新的坐標軸裏面表示原來高維的數據。 低維 反向 映射為高維數據 PCA.py import numpy as np class
python構造二維列表以及排序字典
collect ons ted append 現在 pytho lam nbsp pan 1. 構造二維列表: 比如我現在需要一個100*100的二維列表: a = [] for i in range(100): a.append([]) for j in