
從compositional到distributed,從無監督到有監督再到多工學習 —— 漫談句向量 Sentence Embedding
關於詞向量,word embedding,研究相對較早,存在多種表徵方式,目前 distributed 方式相對成熟,得到了廣泛應用。但從 word 向 sentence、paragraph、document擴充套件,卻仍處於探索階段,本文嘗試對目前主要的研究方向和代表工作進行概述,不會詳細介紹模型細節,後續會不斷更新。
感興趣可以先看下Marco Baroni 2015在 CAS 做的報告。
目前,sentence representation 從構造原理可以分成兩大類,基於 word embedding 的 compositional 類,類似於 word2vec 的 distributed 思想的基於上下文的 distributed 類。
此外,從學習方式上還可以分成幾大類,早期基於無監督學習的型別,後來基於監督學習的,以及近期基於多工學習的型別。很長一段時間,普遍認為基於無監督學習得到的句子表徵質量要比基於監督學習的質量好,但現在也開始發生了變化,基於監督學習甚至多工學習的句向量表徵越來越突出。
1、Compositional 類
compositional 類,即單從 sentence 的組成單元 word 上入手,以 word embedding 作為輸入,在提取組合高階特徵方面做文章,構成 sentence embedding。
此時,根據提取組合高階特徵方式的不同,又可以分為基於無監督的和有監督兩類。
1.1 Simple BOW 方法
作為無監督方式,雖然簡單,但通常是一個不錯的 baseline。基本就是對詞向量做各種簡單的數值運算。
Average BOW
近期 [Alexis Conneau, 2018, What you can cram into a single vector: Probing sentence embeddings for linguistic properties] 工作表明,這種構造實際是一個很強大的 baseline。
Weighted BOW
[Matt J. Kusner, 2015, From Word Embeddings To Document Distances],以及 [Georgios-Ioannis Brokos, 2016, Using Centroids of Word Embeddings and Word Mover’s Distance for Biomedical Document Retrieval in Question Answering],結合詞向量與 TF-IDF,通過編輯距離等簡單數值運算,得到句子的質心表徵。
[Sanjeev Arora, 2017, A Simple but Tough-to-beat Baseline for Sentence Embeddings],提出利用加權的詞向量,並對該句向量減去一個基於主成分構成的向量即可。
PV-DM 和 PV-DBOW
[Quoc V. Le, T. Mikolov, 2014, Distributed Representations of Sentences and Documents],把 word embedding 的訓練方式應用到 sentence embedding,得到了 doc2vec。
仿照 CBOW 和 Skip-gram 有了下述 PV-DM 和 PV-DBOW 模型:
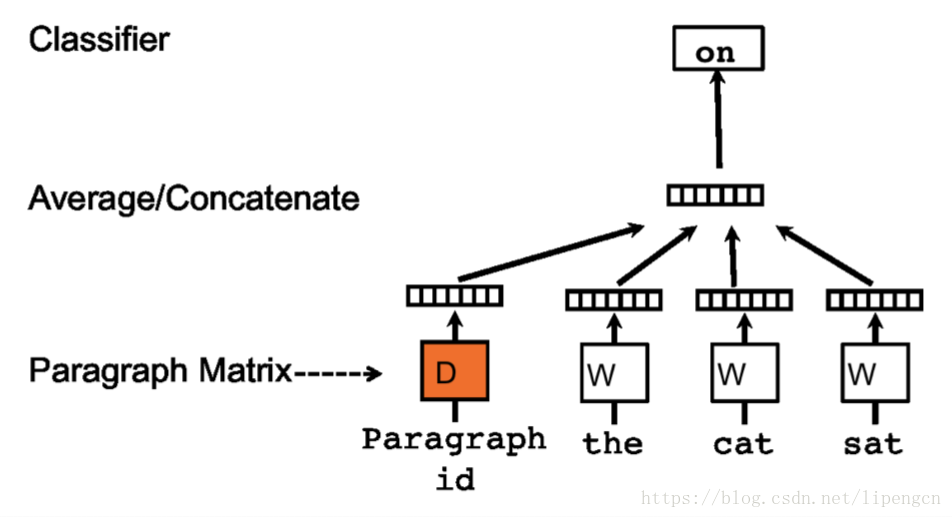
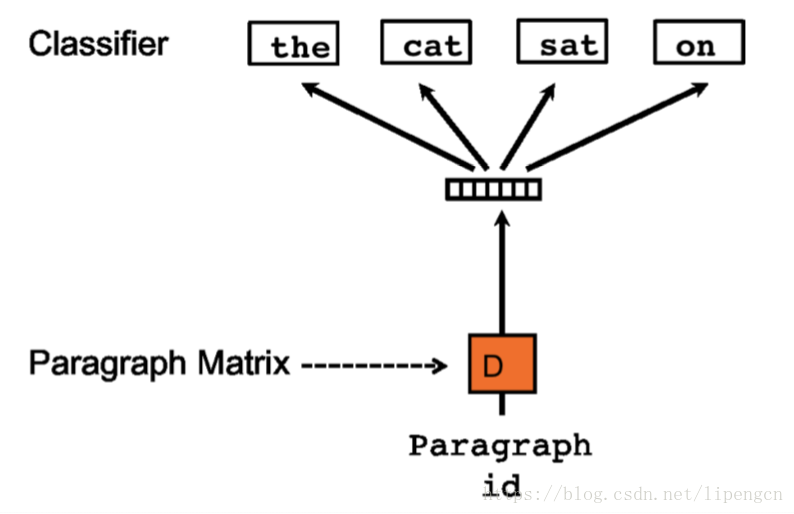
1.2 NN 進行特徵表達
基本全是監督學習方法了,即構建 NN 來對句子的詞向量中進行特徵表達,從而作為通用的句向量表徵使用。各類方法的區別也是集中於網路結構,以及採用哪種學習任務學習到的句子表徵才能更好地泛化到下游任務中去。
DAN 模型
[Mohit Iyyer, Varun Manjunatha, 2015, Deep Unordered Composition Rivals Syntactic Methods for Text Classification],提出 RNN 雖然可以組合輸入的語義資訊,但複雜度過高,deep average network 也可以實現差不多的效能,但複雜度降低了很多,網路結構如下,即通過兩層隱層來進一步對 average BOW 進行非線性表達:
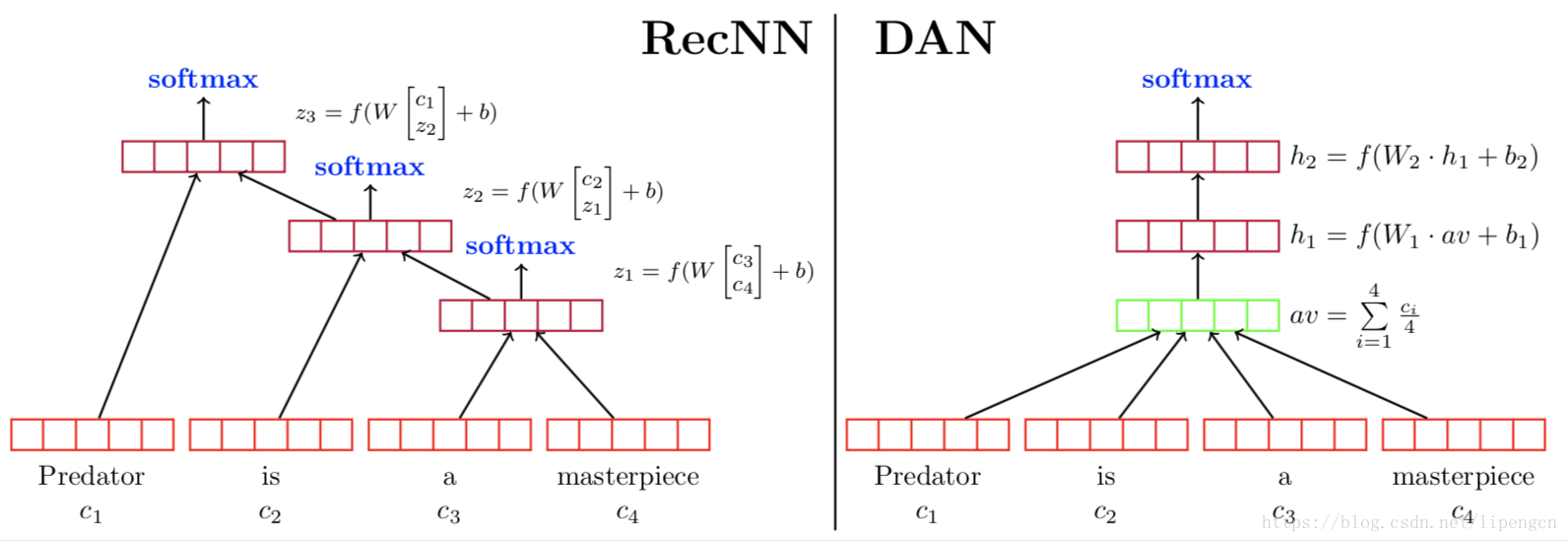
基於 CNN 的模型
[Nal Kalchbrenner, 2014, A Convolutional Neural Network for Modelling Sentences],算是把 CNN 應用到 NLP 的先驅,解決了 CNN 處理變長輸入序列問題,嘗試解決 sentence modeling 問題,所用模型如下:
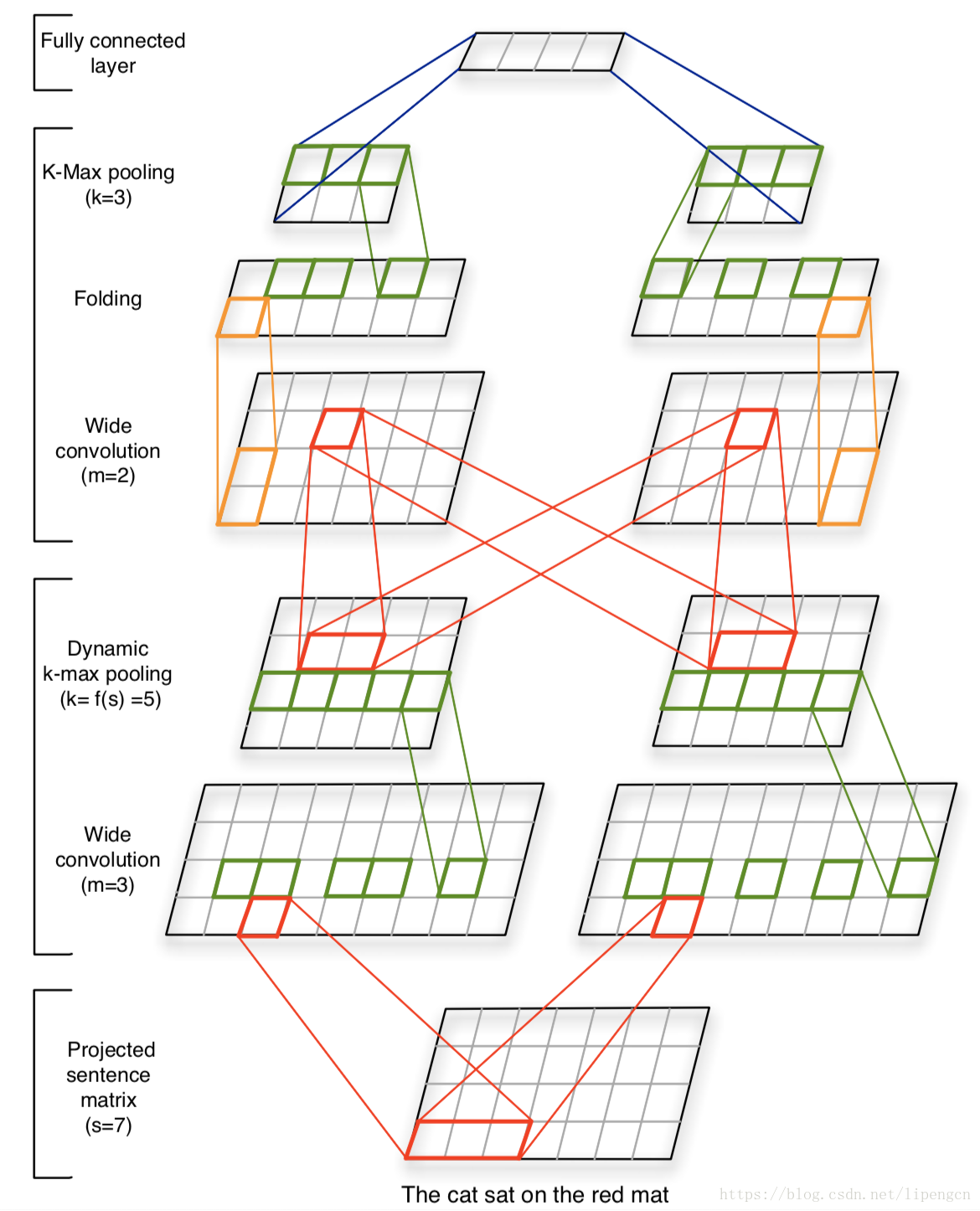
[Aliaksei Severyn, 2015, Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks],在 CNN 基礎上引入了 IR 中的相似度矩陣,並且提出了和傳統特徵拼接的思路。
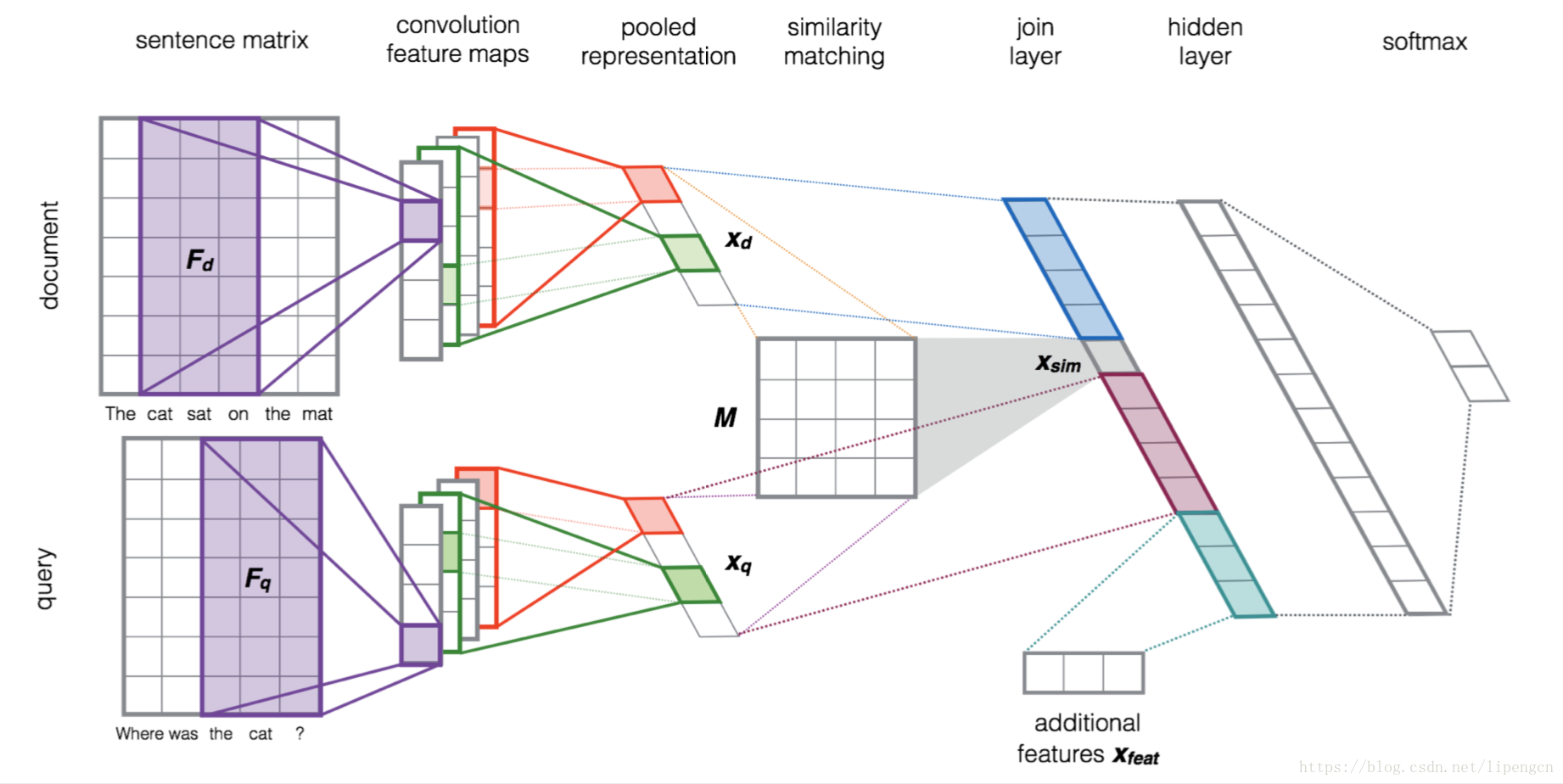
基於 RNN 的模型
這邊算是早期應用,通常取最後時序輸出算作句子表徵,即 RNN 做 acceptor 使用。提出的工作也很多,就不一一介紹了。
InferSent
[Alexis Conneau, 2017, Supervised Learning of Universal Sentence Representations from Natural Language Inference Data],是在 SNLI 語料上訓練的位於句子編碼器頂層的分類器,兩個句子共用同一個編碼器,這裡的編碼器採用 max-pooling 操作實現的 biLSTM。
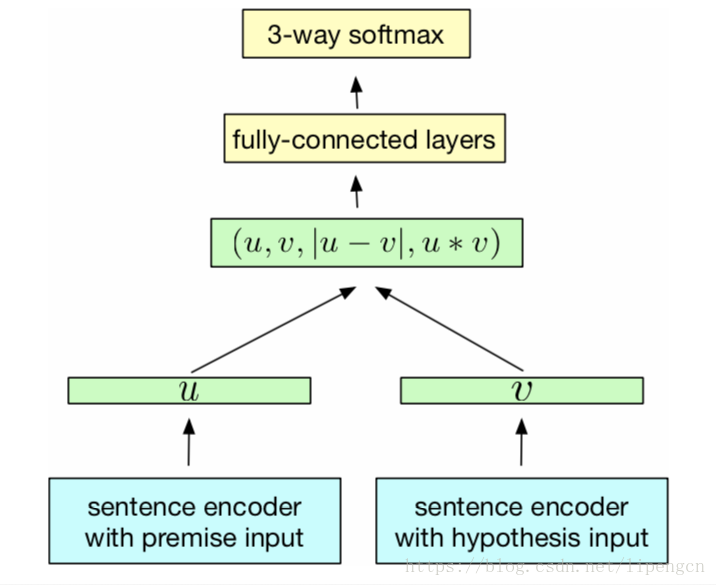
2、Distributed 類
distributed 仿照 word embedding 的 distributed 思想,從 sentence 的 context 去挖掘 sentence 的 representation,即 sentence 成為基本 unit,其他 sentence 成為其 context。
Skip-Thought Vectors 模型
[Ryan Kiros, 2015, Skip-Thought Vectors],提出編解碼方式,先對本句使用一個 RNN 作為 encoder,然後對應前一句和後一句各採用一個 RNN 作為 decoder,進行預測,其中的 encoder 可以作為特徵提取器用於後續任務。當然,這還是算是無監督學習。基本模型如下:

此外,本文還提出了一種未登入詞的詞向量擴充套件方法,值得學習。
不過,這種方法很大的侷限在於需要基於大量的平衡的語料進行訓練,類似於 Word2Vec 訓練的語料量很大,本文是採用電子書的文字進行的訓練。
Quick-Thought Vectors 模型
[Lajanugen Logeswaran, 2018, An efficient framework for learning sentence representations],對 skip-thought 模型進行了改進,將預測下一個句子解碼任務重新定義為一個分類任務,提升了執行速度。
discourse-based sentence 模型
[Tamara Polajnar, 2015, An Exploration of Discourse-Based Sentence Spaces for Compositional Distributional Semantics],提出 discourse-base 方式作為 distributed 模型,主要研究了 distributed 方式和 compositional 方式在效能上的優劣,最後認為兩者幾乎一致。這裡的模型如下:

3、多工學習類
這一塊單獨拎出來講,因為多工學習可以視為對 skip-throughts、InferSent 以及其他相關的無監督/監督學習方法的一種泛化,它將多個訓練目標融合到一個訓練方案中,來學習泛化更好的句表徵。
GPDS
[Sandeep Subramanian, 2018, LEARNING GENERAL PURPOSE DISTRIBUTED SENTENCE REPRESENTATIONS VIA LARGE SCALE MULTI-TASK LEARNING],MILA 和 MS 聯合提出的,發現為了能夠泛化各類任務中的句子表徵,就有必要將一個句子的多個層面的資訊進行編碼。文章提出了一種一對多的多工學習框架,通過在不同的任務間進行切換去學習一個通用的句子表徵。
這六個任務包括:對於上一個/下一個句子的 skip-throughts 預測、NMT、組別解析、神經語言推理,它們共享同一個由 GRU 得到的句向量。
USE
[Daniel Cer, 2018, Universal Sentence Encoder],MS 提出的,也是在多種資料集上切換各種任務上訓練,以期獲得適應各種NLP 的句子表徵。
4、應用
從目前 sentence embedding 的應用看來,其表達非常依賴特定任務,即不同的任務需要的 sentence 的關鍵抽象特徵是不同層面的。後面會持續更新。