
前嗅ForeSpider教程:采集網頁鏈接/源碼/時間/重定向地址等
阿新 • • 發佈:2019-01-27
文本 title 進行 resp bae spi -o 默認 新建 第一步:新建任務
①點擊左上角“加號”新建任務,如圖1:

【圖1】
②彈窗裏填寫采集地址,任務名稱,如圖2:
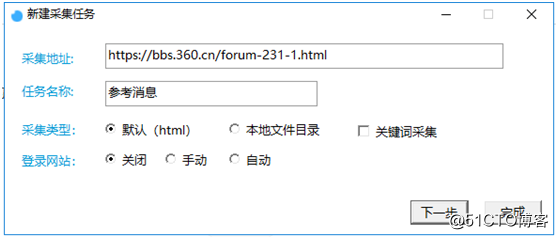
【圖2】
③ 點擊下一步,勾選抽取鏈接,選擇網頁內所有鏈接,如圖3:
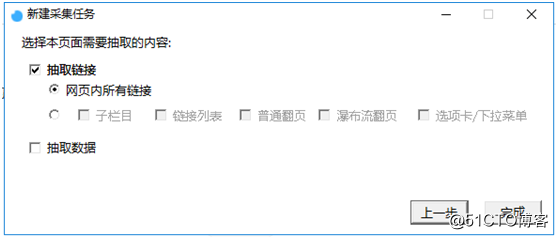
【圖3】
④完成後模板抽取配置列表有一個模板,默認模板。默認模板下自動生成一個鏈接抽取,名稱為網頁全部鏈接,如4:
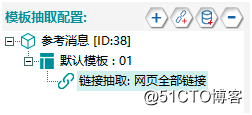
【圖4】
第二步:創建新的模板,並新建數據抽取
①模板配置,點擊“新建模板”按鈕,得到新建模板,如圖5。

【圖5】
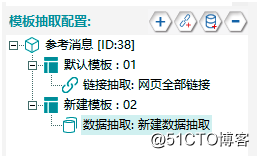
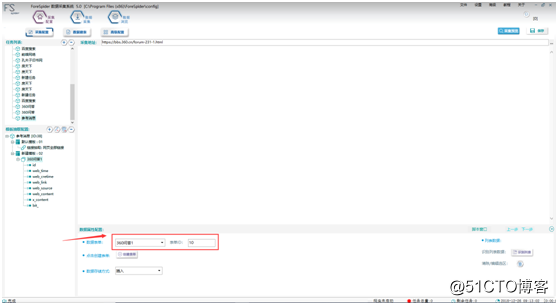
②新建數據抽取。直接點擊模板二,點擊上面“新建數據抽取”按鈕,得到數據抽取,如圖6。
網頁創建時間:文檔創建或網頁發布的時間。
網頁獲取時間:ForeSpider采集該網頁的時間。
網頁地址:自動采集網頁的URL地址。
選區內網頁源碼(包含當前標簽):采集選區內全部源代碼,包含當前節點標簽等,即整個選區的源代碼。
選區內全部文本:最常用的類型。點擊Ctrl選擇綠框後,采集選區裏的全部內容
選區內網頁源碼:采集選區內全部源代碼,不包含當前節點標簽等。
網頁標題:采集網頁的標題。即網頁<title>中的內容。
③ 數據抽取鏈接處關聯表單,如圖10。
【圖10】
第四步:采集預覽
①點擊擊右上角采集預覽,如圖11。
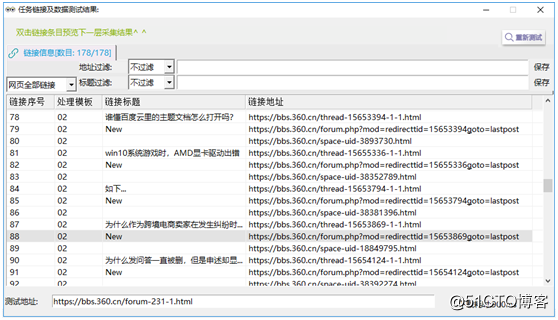
【圖11】
②雙擊任意一條鏈接,看看是否可以得到和網頁對應的規整的數據,如圖12、圖13。
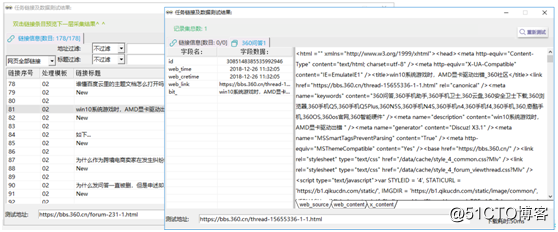
【圖12】
①點擊左上角“加號”新建任務,如圖1:
【圖1】
②彈窗裏填寫采集地址,任務名稱,如圖2:
【圖2】
③ 點擊下一步,勾選抽取鏈接,選擇網頁內所有鏈接,如圖3:
【圖3】
④完成後模板抽取配置列表有一個模板,默認模板。默認模板下自動生成一個鏈接抽取,名稱為網頁全部鏈接,如4:
【圖4】
第二步:創建新的模板,並新建數據抽取
①模板配置,點擊“新建模板”按鈕,得到新建模板,如圖5。
【圖5】
②新建數據抽取。直接點擊模板二,點擊上面“新建數據抽取”按鈕,得到數據抽取,如圖6。
【圖6】
③關聯模板
在軟件中模板的關聯關系,與網頁中鏈接跳轉的關系相同。
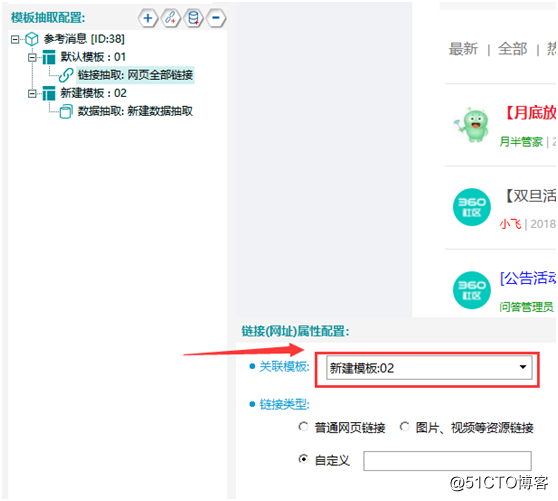
根據網頁跳轉規律,將“網頁全部鏈接”關聯模板“新建模板02”,如圖7:
【圖7】
第三步:創建/選擇表單
①在ForeSpider爬蟲中,表單是可以復用的,所以可以在數據表單出直接選擇之前建過的表單,也可以通過表單ID來進行查找並關聯數據表單。此處使用的方法三,如圖8。
方法一:通過下拉菜單或表單ID選擇已有表單
方法二:點擊創建表單進入快速建表頁面,新建表單
方法三:點擊“采集配置”-“數據建表”,點擊采“采集表單”後面的如圖8。
【圖8】
②配置表單
根據所需內容,配置表單字段(即表頭),此處配置了包括網頁主鍵、網頁創建時間、網頁獲取時間、網頁地址、全區內網頁源碼(包含當前標簽)、選取內全部文本、選取內網頁源碼以及網頁標題八個字段,表單如圖9。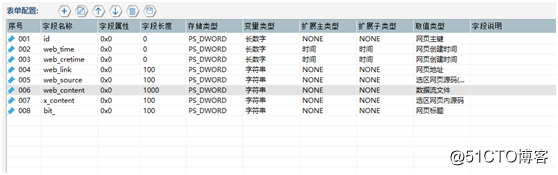
【圖9】
以下字段為軟件自帶字段類型,無需確定選取取值。
網頁創建時間:文檔創建或網頁發布的時間。
網頁獲取時間:ForeSpider采集該網頁的時間。
網頁地址:自動采集網頁的URL地址。
選區內網頁源碼(包含當前標簽):采集選區內全部源代碼,包含當前節點標簽等,即整個選區的源代碼。
選區內全部文本:最常用的類型。點擊Ctrl選擇綠框後,采集選區裏的全部內容
選區內網頁源碼:采集選區內全部源代碼,不包含當前節點標簽等。
網頁標題:采集網頁的標題。即網頁<title>中的內容。
③ 數據抽取鏈接處關聯表單,如圖10。
【圖10】
第四步:采集預覽
①點擊擊右上角采集預覽,如圖11。
【圖11】
②雙擊任意一條鏈接,看看是否可以得到和網頁對應的規整的數據,如圖12、圖13。
【圖12】
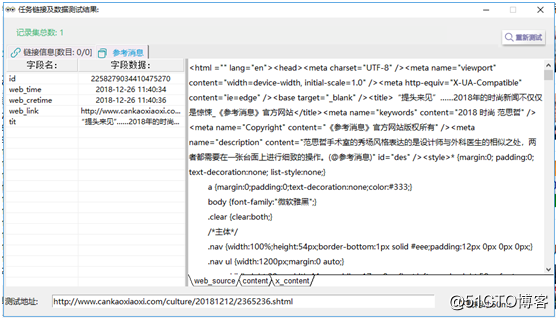
【圖13】
前嗅ForeSpider教程:采集網頁鏈接/源碼/時間/重定向地址等