
前嗅ForeSpider采集配置界面介紹
?
啟動ForeSpider采集軟件後,默認界面如圖所示。ROOT任務下有已經配置好的示例模板,點擊網站圖標即可進行采集預覽。可在任務列表選擇某一任務按照需求重新配置。
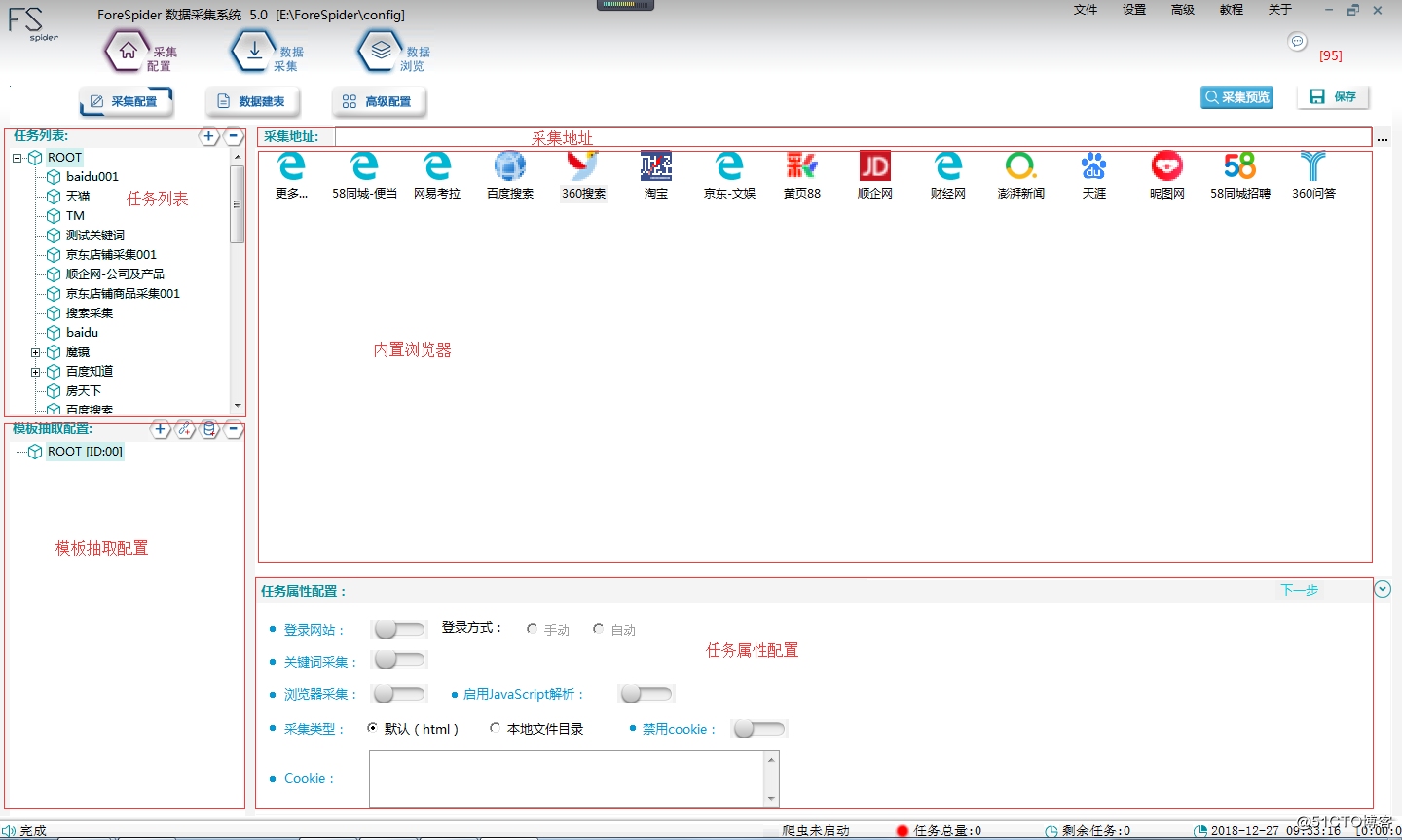
【采集配置界面】
?
1.任務列表
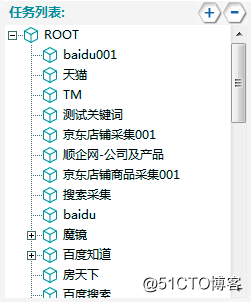
【任務列表】
任務對應著采集來源,通常一個采集來源對應著一個任務。如采集人民網時,人民網就是一個任務;通過百度采集全網信息時,百度就是一個任務;通過100個網址導航采集全球域名時,這100個網址導航就是一個任務。
?
2.任務屬性配置
用戶可根據采集需求與網站的設置選擇性的配置任務屬性。
任務屬性配置包括登錄網站、關鍵詞采集、瀏覽器采集、采集類型、禁用Cookie及Cookie設置6個部分。
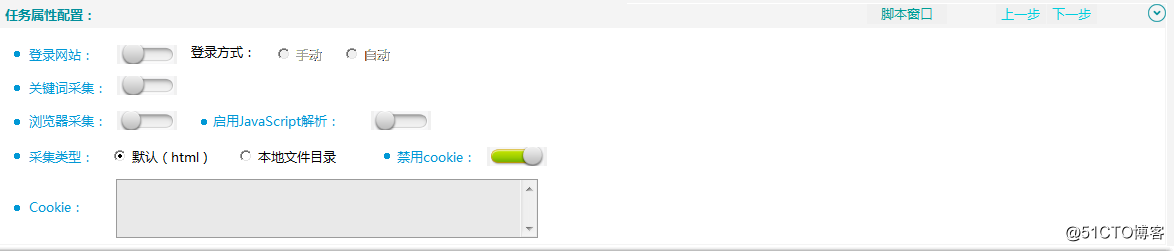
【任務屬性配置】
(1)登錄網站
如果采集源的數據需要登錄才可以采集到,則需要配置登錄信息。開啟登錄後,右側會出現操作向導。
(2)關鍵詞采集
當采集對象是搜索欄時,需要進行關鍵詞配置。開啟關鍵詞采集後,右側會出現操作向導。
當網站登錄與采集登錄同時開啟時,可在任務屬性配置欄右側切換操作向導。
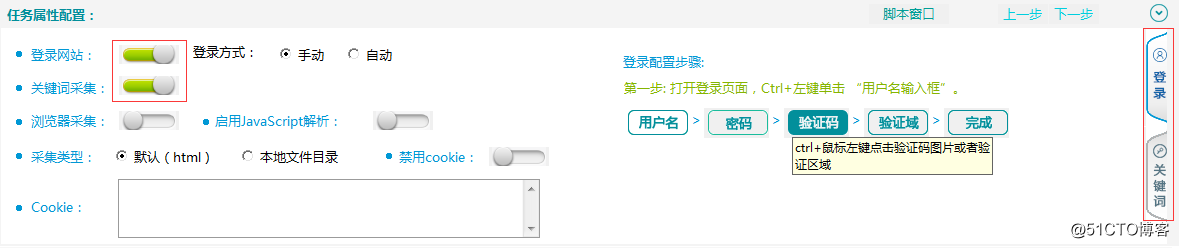
【登錄與關鍵詞采集】
(3)瀏覽器采集
通過瀏覽器插件的方式采集數據。適用於大量JS生成且采集難度大的網頁。對JS支持好,近乎於在瀏覽器上點擊,但采集效率低。
(4)采集類型
采集類型分為默認(html)和本地文件目錄兩種。
(5)禁用Cookie
禁止使用Cookie解析網頁。
(6)Cookie
當網站需要Cookie驗證才能采集時,需要配置Cookie信息。
?
3.模板抽取配置

【模板抽取配置】
(1)模板
模板通過一個示例地址,模板化同一層級的頁面,從而達到批量采集的效果。一個模板對應一個層級的頁面,因此同一層頁面只能配置一個模板,填寫一個示例地址,但是一個模板中可以創建多個鏈接、數據抽取,每個鏈接抽取都要關聯其他模板。
通過模板之間的關聯,模擬網站各頁面的跳轉關系。通過鏈接抽取,抽出網頁中的鏈接。通過數據抽取,抓取網頁中的數據。
(2)模板屬性配置
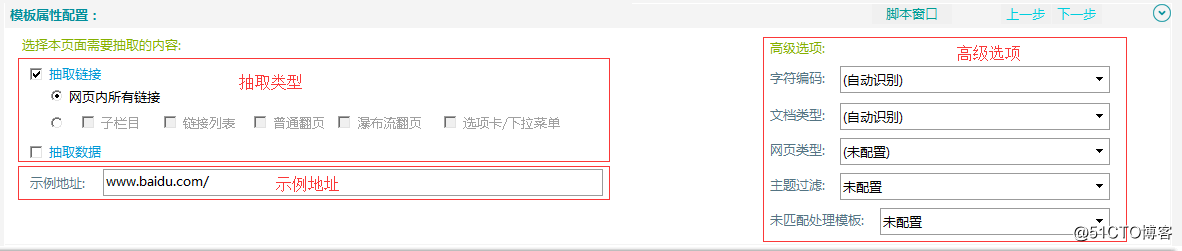
【模板屬性配置】
①抽取類型選擇
抽取類型包括鏈接抽取和數據抽取。

【抽取類型選擇】
②示例地址
示例地址作為樣例,成為模板,通過以該地址配置模板,可以抓取與該地址在同一層級、具有相似結構的頁面數據。
任務第一個模板的示例地址默認為創建任務時填寫的采集地址。

【示例地址】
③高級選項
高級選項包括字符編碼、文檔類型、網頁類型、主題過濾、未匹配處理模板5個部分。(不常用功能)

【高級選項】
(3)鏈接(網址)配置
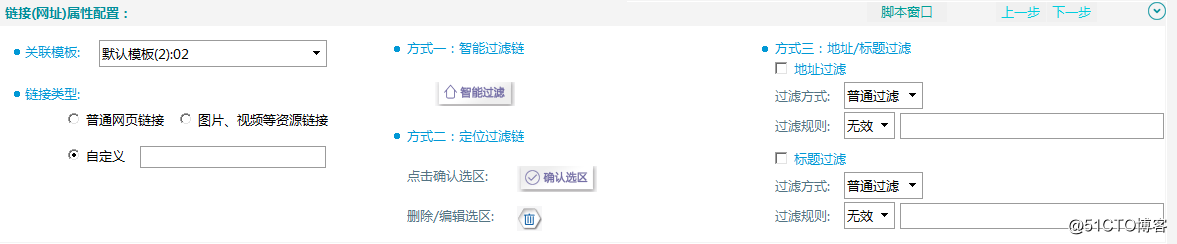
【鏈接(網址)配置】
①關聯模板
關聯模板是指該“鏈接抽取”抽取出的鏈接,其下一層級頁面對應的模板,也就是在瀏覽器中,點擊鏈接打開的下一層頁面。通過模板之間的關聯,可以將網站各層級頁面關聯起來,在軟件中形成與瀏覽器相同的跳轉結構,從而完整的采集數據。
②鏈接類型
鏈接類型可分為普通網頁鏈接、圖片視頻等資源鏈接和自定義類型三種。默認選擇普通網頁鏈接。
③智能過濾
智能過濾可以一鍵過濾出,鏈接地址規律相同的鏈接。適用於大多數情況,如過濾的不正確,可以使用地址/標題過濾。
④定位過濾
定位過濾是通過內置瀏覽器定位,適用於所需鏈接都集中在一小片區域的情況。
⑤地址/標題過濾
為了在抽取的鏈接中去除無關鏈接,有兩種過濾方式,配置方式相同。地址過濾是通過url地址的規律,過濾無關鏈接。標題過濾是通過鏈接標題的規律,過濾無關鏈接。
(4)數據屬性配置

【數據屬性配置】
①數據表單
在ForeSpider爬蟲中,表單是可以復用的,所以可以在數據表單出直接選擇之前建過的表單,也可以通過表單ID來進行查找並關聯數據表單。
②點擊創建表達
若在數據抽取鏈接下,沒有相應表單可供選擇,可點擊“創建表單”按鈕,快速創建表單。可添加表單名稱、字段名稱,選擇字段類型、表單模板。(>>快速建表/>>自由建表)
③數據存儲方式
指的是數據采集時,在數據庫裏的存儲方式。
④列表數據
識別列表用於存儲表格/列表的數據,將表格/列表的不同列對應存入不同字段,表格/列表的不同行分別存儲為數據表的多條記錄。(>>如何采集列表/表格數據)
?
4.采集地址
采集對象的入口地址(url地址)。比如采集整個淘寶網全部商品的信息,淘寶網首頁就是入口地址。比如只采集“女裝”類別的商品信息,“女裝”首頁就是入口地址。

【采集地址】
?
5.內置瀏覽器
模擬不同版本的瀏覽器。填入采集地址,可點擊內置瀏覽器顯示采集頁面。

【內置瀏覽器】
前嗅ForeSpider采集配置界面介紹