計算機視覺與深度學習(5)
1. 引言
其實一開始要講這部分內容,我是拒絕的,原因是我覺得有一種寫高數課總結的感覺。而一般直觀上理解反向傳播演算法就是求導的一個鏈式法則而已。但是偏偏理解這部分和其中的細節對於神經網路的設計和調整優化又是有用的,所以硬著頭皮寫寫吧。
問題描述與動機:
大家都知道的,其實我們就是在給定的影象畫素向量x和對應的函式f(x))
我們之所以想解決這個問題,是因為在神經網路中,f上的梯度有時候也是有用的,比如如果我們想做視覺化以及瞭解神經網路在『做什麼』的時候。
2.高數梯度/偏導基礎
好了,現在開始複習高數課了,從最簡單的例子開始,假如f(x,y)=xy的偏導,如下:
2.1 解釋
我們知道偏導數實際表示的含義:一個函式在給定變數所在維度,當前點附近的一個變化率。也就是:
以上公式中的ddx,我們將y的值增加一個很小的量h,則整個表示式變化4h。
每個維度/變數上的偏導,表示整個函式表示式,在這個值上的『敏感度』
哦,對,我們說的梯度∇f。即使嚴格意義上來說梯度是一個向量,但是大多數情況下,我們還是習慣直呼『x上的梯度』,而不是『x上的偏導』
大家都知道加法操作上的偏導數是這樣的:
而對於一些別的操作,比如max函式,偏導數是這樣的(後面的括號表示在這個條件下):
3. 複雜函式偏導的鏈式法則
考慮一個麻煩一點的函式,比如f(x,y,z)=(x+y)z,當然q是我們自己設定的一個變數,我們對他的偏導完全不感興趣。
那『鏈式法則』告訴我們一個對上述偏導公式『串聯』的方式,得到我們感興趣的偏導數:∂f∂x=∂f∂q∂q∂x
看個例子:
x = -2; y = 5; z = -4
# 前向計算
q = x + y # q becomes 3
f = q * z # f becomes -12
# 類反向傳播:
# 先算到了 f = q * z
dfdz = q # df/dz = q - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
鏈式法則的結果是,只剩下我們感興趣的[dfdx,dfdy,dfdz],也就是原函式在x,y,z上的偏導。這是一個簡單的例子,之後的程式裡面我們為了簡潔,不會完整寫出dfdq,而是用dq代替。
以下是這個計算的示意圖:

4. 反向傳播的直觀理解
一句話概括:反向傳播的過程,實際上是一個由區域性到全部的精妙過程。比如上面的電路圖中,其實每一個『門』在拿到輸入之後,都能計算2個東西:
- 輸出值
- 對應輸入和輸出的區域性梯度
而且很明顯,每個門在進行這個計算的時候是完全獨立的,不需要對電路圖中其他的結構有了解。然而,在整個前向傳輸過程結束之後,在反向傳播過程中,每個門卻能逐步累積計算出它在整個電路輸出上的梯度。『鏈式法則』告訴我們每一個門接收到後向傳來的梯度,同時用它乘以自己算出的對每個輸入的區域性梯度,接著往後傳。
以上面的圖為例,來解釋一下這個過程。加法門接收到輸入[-2, 5]同時輸出結果3。因為加法操作對兩個輸入的偏導都應該是1。電路後續的乘法部分算出最終結果-12。在反向傳播過程中,鏈式法則是這樣做的:加法操作的輸出3,在最後的乘法操作中,獲得的梯度為-4,如果把整個網路擬人化,我們可以認為這代表著網路『想要』加法操作的結果小一點,而且是以4*的強度來減小。加法操作的門獲得這個梯度-4以後,把它分別乘以本地的兩個梯度(加法的偏導都是1),1*-4=-4。如果輸入x減小,那加法門的輸出也會減小,這樣乘法輸出會相應的增加。
反向傳播,可以看做網路中門與門之間的『關聯對話』,它們『想要』自己的輸出更大還是更小(以多大的幅度),從而讓最後的輸出結果更大。
5. Sigmoid例子
上面舉的例子其實在實際應用中很少見,我們很多時候見到的網路和門函式更復雜,但是不論它是什麼樣的,反向傳播都是可以使用的,唯一的區別就是可能網路拆解出來的門函式佈局更復雜一些。我們以之前的邏輯迴歸為例:
這個看似複雜的函式,其實可以看做一些基礎函式的組合,這些基礎函式及他們的偏導如下:
上述每一個基礎函式都可以看做一個門,如此簡單的初等函式組合在一塊兒卻能夠完成邏輯迴歸中對映函式的複雜功能。下面我們畫出神經網路,並給出具體輸入輸出和引數的數值:

這個圖中,[x0, x1]是輸入,[w0, w1,w2]為可調引數,所以它做的事情是對輸入做了一個線性計算(x和w的內積),同時把結果放入sigmoid函式中,從而對映到(0,1)之間的數。
上面的例子中,w與x之間的內積分解為一長串的小函式連線完成,而後接的是sigmoid函式σ(x),有趣的是sigmoid函式看似複雜,求解倒是的時候卻是有技巧的,如下:
σ(x)=11+e−x→dσ(x)dx=e−x(1+e−x)2=(1+e−x−11+e−x)(11+e−x)=(1−σ(x))σ(x)\sigma(x) = \frac{1}{1+e^{-x}} \\ \rightarrow \hspace{0.3in} \frac{d\sigma(x)}{dx} = \frac{e^{-x}}{(1+e^{-x})^2} = \left( \frac{1 + e^{-x} - 1}{1 + e^{-x}} \right) \left( \frac{1}{1+e^{-x}} \right)你看,它的導數可以用自己很簡單的重新表示出來。所以在計算導數的時候非常方便,比如sigmoid函式接收到的輸入是1.0,輸出結果是-0.73。那麼我們可以非常方便地計算得到它的偏導為(1-0.73)*0.73~=0.2。我們看看在這個sigmoid函式部分反向傳播的計算程式碼:
w = [2,-3,-3] # 我們隨機給定一組權重
x = [-1, -2]
# 前向傳播
dot = w[0]*x[0] + w[1]*x[1] + w[2]
f = 1.0 / (1 + math.exp(-dot)) # sigmoid函式
# 反向傳播經過該sigmoid神經元
ddot = (1 - f) * f # sigmoid函式偏導
dx = [w[0] * ddot, w[1] * ddot] # 在x這條路徑上的反向傳播
dw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot] # 在w這條路徑上的反向傳播
# yes!就醬紫算完了!是不是很簡單?- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5.1 工程實現小提示
回過頭看看上頭的程式碼,你會發現,實際寫程式碼實現的時候,有一個技巧能幫助我們很容易地實現反向傳播,我們會把前向傳播的過程分解成反向傳播很容易追溯回來的部分。
6. 反向傳播實戰:複雜函式
我們看一個稍複雜一些的函式:
插一句,這個函式沒有任何實際的意義。我們提到它,僅僅是想舉個例子來說明覆雜函式的反向傳播怎麼使用。如果直接對這個函式求x或者y的偏導的話,你會得到一個很複雜的形式。但是如果你用反向傳播去求解具體的梯度值的話,卻完全沒有這個煩惱。我們把這個函式分解成小部分,進行前向和反向傳播計算,即可得到結果,前向傳播計算的程式碼如下:
x = 3 # 例子
y = -4
# 前向傳播
sigy = 1.0 / (1 + math.exp(-y)) # 單值上的sigmoid函式
num = x + sigy
sigx = 1.0 / (1 + math.exp(-x))
xpy = x + y
xpysqr = xpy**2
den = sigx + xpysqr
invden = 1.0 / den
f = num * invden # 完成! - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意到我們並沒有一次性把前向傳播最後結果算出來,而是刻意留出了很多中間變數,它們都是我們可以直接求解區域性梯度的簡單表示式。因此,計算反向傳播就變得簡單了:我們從最後結果往前看,前向運算中的每一箇中間變數sigy, num, sigx, xpy, xpysqr, den, invden我們都會用到,只不過後向傳回的偏導值乘以它們,得到反向傳播的偏導值。反向傳播計算的程式碼如下:
# 區域性函式表示式為 f = num * invden
dnum = invden
dinvden = num
# 區域性函式表示式為 invden = 1.0 / den
dden = (-1.0 / (den**2)) * dinvden
# 區域性函式表示式為 den = sigx + xpysqr
dsigx = (1) * dden
dxpysqr = (1) * dden
# 區域性函式表示式為 xpysqr = xpy**2
dxpy = (2 * xpy) * dxpysqr #(5)
# 區域性函式表示式為 xpy = x + y
dx = (1) * dxpy
dy = (1) * dxpy
# 區域性函式表示式為 sigx = 1.0 / (1 + math.exp(-x))
dx += ((1 - sigx) * sigx) * dsigx # 注意到這裡用的是 += !!
# 區域性函式表示式為 num = x + sigy
dx += (1) * dnum
dsigy = (1) * dnum
# 區域性函式表示式為 sigy = 1.0 / (1 + math.exp(-y))
dy += ((1 - sigy) * sigy) * dsigy
# 完事!- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
實際程式設計實現的時候,需要注意一下:
- 前向傳播計算的時候注意保留部分中間變數:在反向傳播計算的時候,會再次用到前向傳播計算中的部分結果。這在反向傳播計算的回溯時可大大加速。
6.1 反向傳播計算中的常見模式
即使因為搭建的神經網路結構形式和使用的神經元都不同,但是大多數情況下,後向計算中的梯度計算可以歸到幾種常見的模式上。比如,最常見的三種簡單運算門(加、乘、最大),他們在反向傳播運算中的作用是非常簡單和直接的。我們一起看看下面這個簡單的神經網:

上圖裡有我們提到的三種門add,max和multiply。
- 加運算門在反向傳播運算中,不管輸入值是多少,取得它output傳回的梯度(gradient)然後均勻地分給兩條輸入路徑。因為加法運算的偏導都是+1.0。
- max(取最大)門不像加法門,在反向傳播計算中,它只會把傳回的梯度回傳給一條輸入路徑。因為max(x,y)只對x和y中較大的那個數,偏導為+1.0,而另一個數上的偏導是0。
- 乘法門就更好理解了,因為x*y對x的偏導為y,而對y的偏導為x,因此在上圖中x的梯度是-8.0,即-4.0*2.0
因為梯度回傳的原因,神經網路對輸入非常敏感。我們拿乘法門來舉例,如果輸入的xi全都變成原來1000倍,而權重w不變,那麼在反向傳播計算的時候,x路徑上獲得的回傳梯度不變,而w上的梯度則會變大1000倍,這使得你不得不降低學習速率(learning rate)成原來的1/1000以維持平衡。因此在很多神經網路的問題中,輸入資料的預處理也是非常重要的。
6.2 向量化的梯度運算
上面所有的部分都是在單變數的函式上做的處理和運算,實際我們在處理很多資料(比如影象資料)的時候,維度都比較高,這時候我們就需要把單變數的函式反向傳播擴充套件到向量化的梯度運算上,需要特別注意的是矩陣運算的每個矩陣維度,以及轉置操作。
我們通過簡單的矩陣運算來拓展前向和反向傳播運算,示例程式碼如下:
# 前向傳播運算
W = np.random.randn(5, 10)
X = np.random.randn(10, 3)
D = W.dot(X)
# 假如我們現在已經拿到了回傳到D上的梯度dD
dD = np.random.randn(*D.shape) # 和D同維度
dW = dD.dot(X.T) #.T 操作計算轉置, dW為W路徑上的梯度
dX = W.T.dot(dD) #dX為X路徑上的梯度- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7. 總結
直觀地理解,反向傳播可以看做圖解求導的鏈式法則。
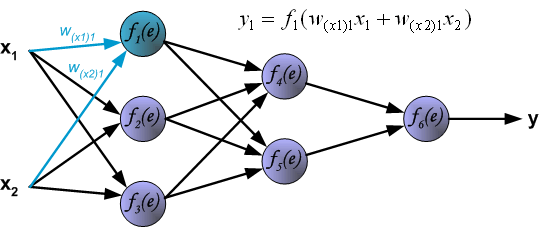
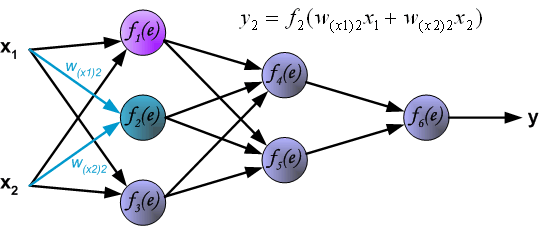
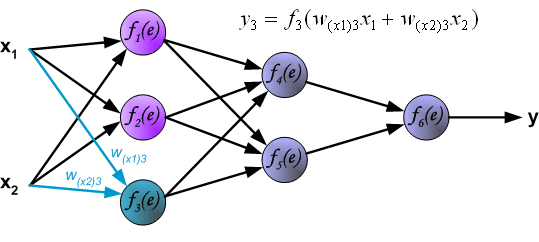
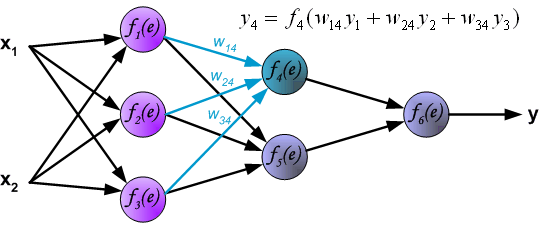
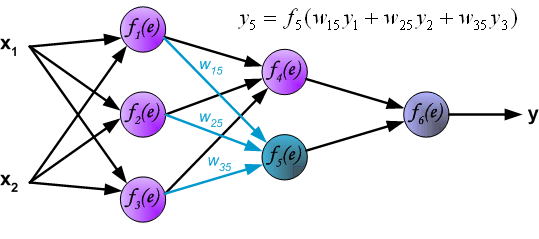
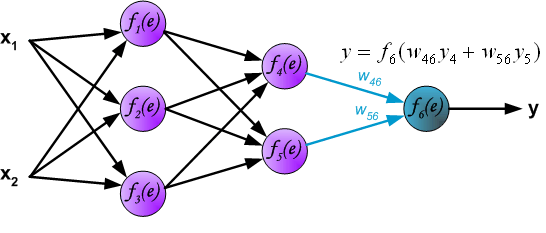
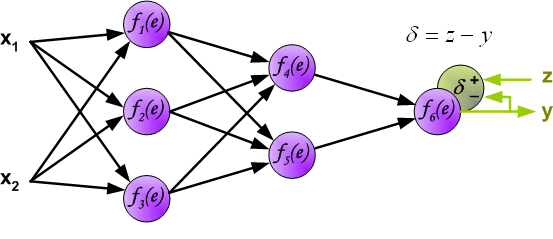
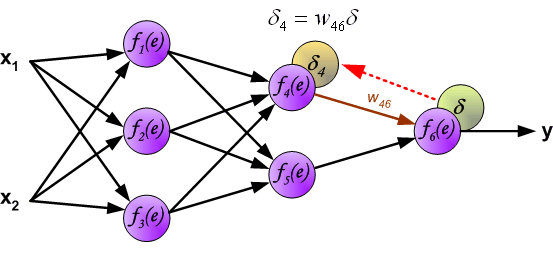
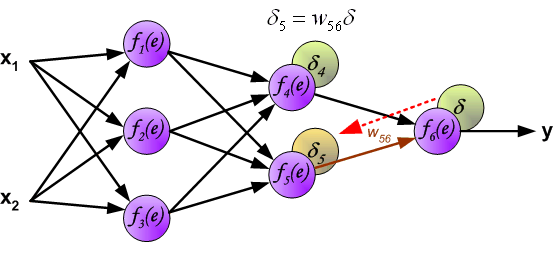
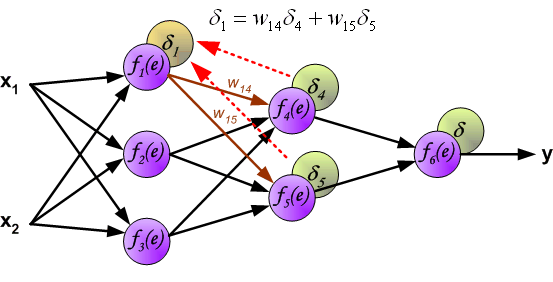
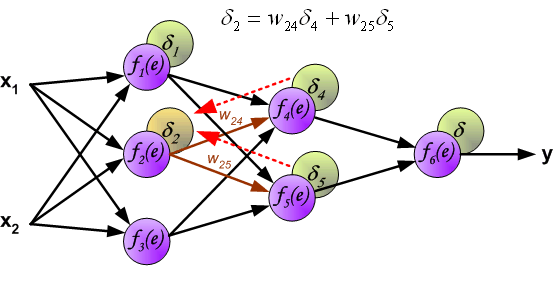
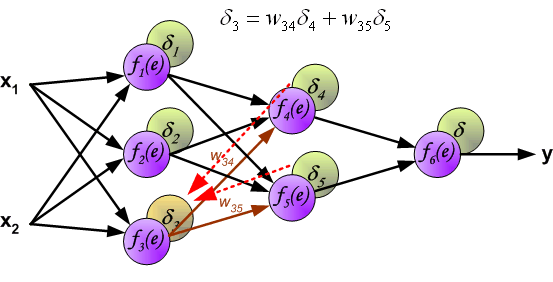
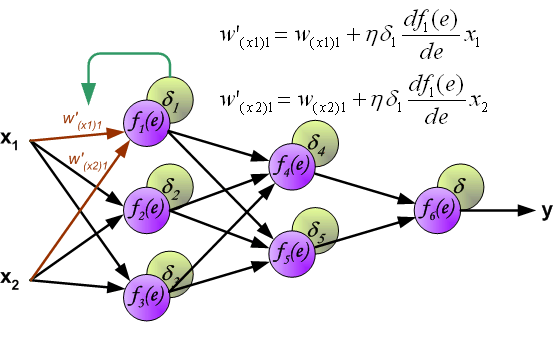
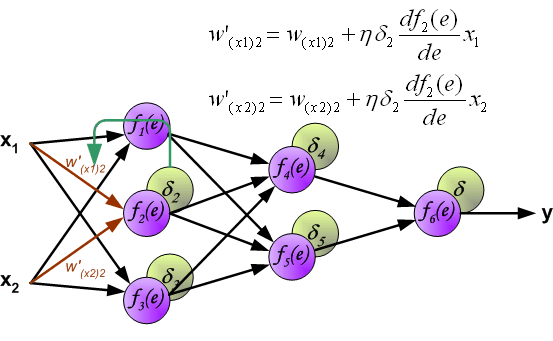
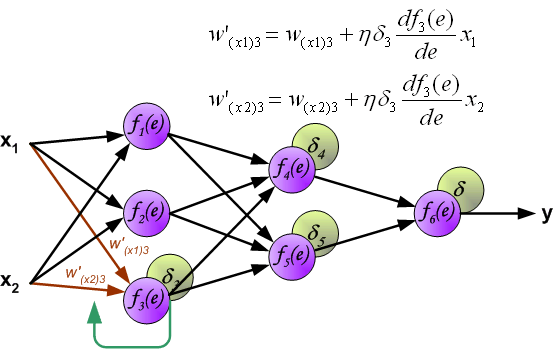
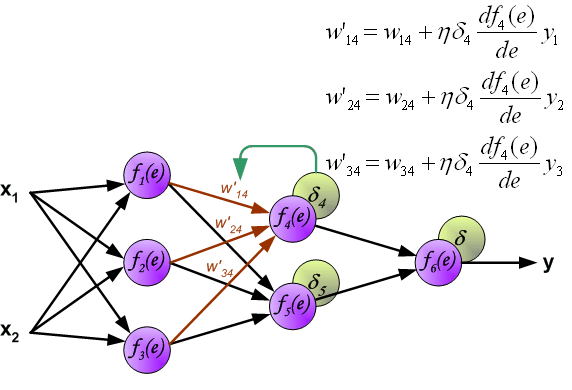
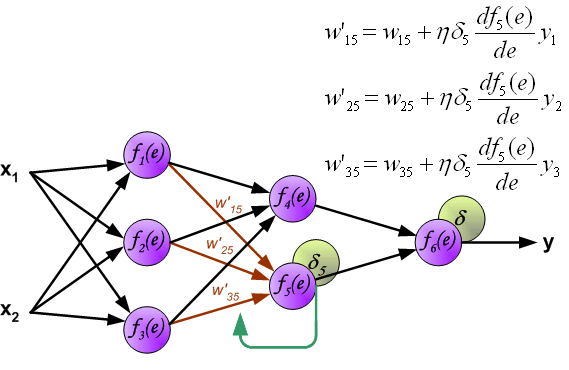
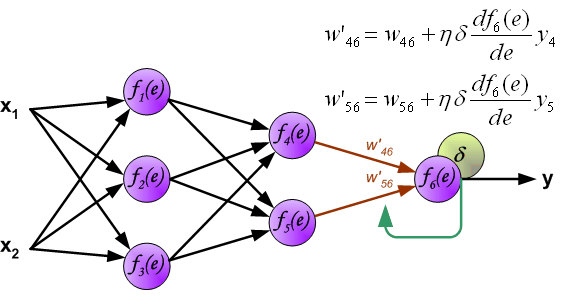
最後我們用一組圖來說明實際優化過程中的正向傳播與反向殘差傳播: