
斯坦福大學-自然語言處理與深度學習(CS224n) 筆記 第三課 詞向量(2)
一、word2vec
1、回顧:skip-grams
word2vec的主要步驟是遍歷整個語料庫,利用每個視窗的中心詞來預測上下文的單詞,然後對每個這樣的視窗利用SGD來進行引數的更新。
對於每一個視窗而言,我們只有2m+1個單詞(其中m表示視窗的半徑),因此我們計算出來的梯度向量是十分稀疏的。對於2dv的引數而言,我們只能更新一小部分。因此一個解決方法是提供一個單詞到詞向量的雜湊對映。

2、負取樣(negative sampling)
在word2vec的計算中有一個問題是條件概率的分母計算代價很高。

我們可以使用負取樣來解決這個問題。負取樣的中心思想是:訓練一個二元邏輯迴歸,其中包含一對真正的中心詞和上下文詞,以及一些噪音對(包含中心詞和一個隨機的單詞)。這種方法來源於這篇文獻:“Distributed Representations of Words and Phrases and their Compositionality” (Mikolov et al. 2013)。具體的目標函式如下,其中k表示的是負樣本的個數,σ表示sigmoid函式。第二行第一項是正樣本,第二項是負樣本。換而言之,目標函式表示我們希望真正的上下文單詞出現的概率儘量大,而在中心詞周圍的隨機單詞出現的概率儘量小。

我們假設隨機選取的噪音單詞是遵循下面的公式,其中U(W)表示一元模型的分佈,之所以加上一個3/4的冪是因為,我們希望減少那些常用的單詞被選中的概率。
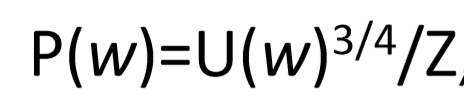
word2vec的另外一種演算法是CBOW,主要的觀點是:從上下文向量的和來預測中心詞,正好與skip-grams相反。
word2vec通過對目標函式的優化,把相似的單詞在空間中投射到鄰近的位置。

二、直接計數方法&混合方法
通過word2vec的原理的觀察,我們可以發現實際上word2vec抓住的是兩個單詞同時出現(cooccurrence)的情況進行的建模。而我們也可以直接進行單詞同時出現(cooccurrence)的統計。
方法是利用同時出現(cooccurrence)矩陣,我們可以統計整篇文章的同時出現(cooccurrence)情況,也可以像word2vec一樣利用一個視窗來進行同時出現(cooccurrence)情況的統計,來抓住語義和句法上面的資訊。
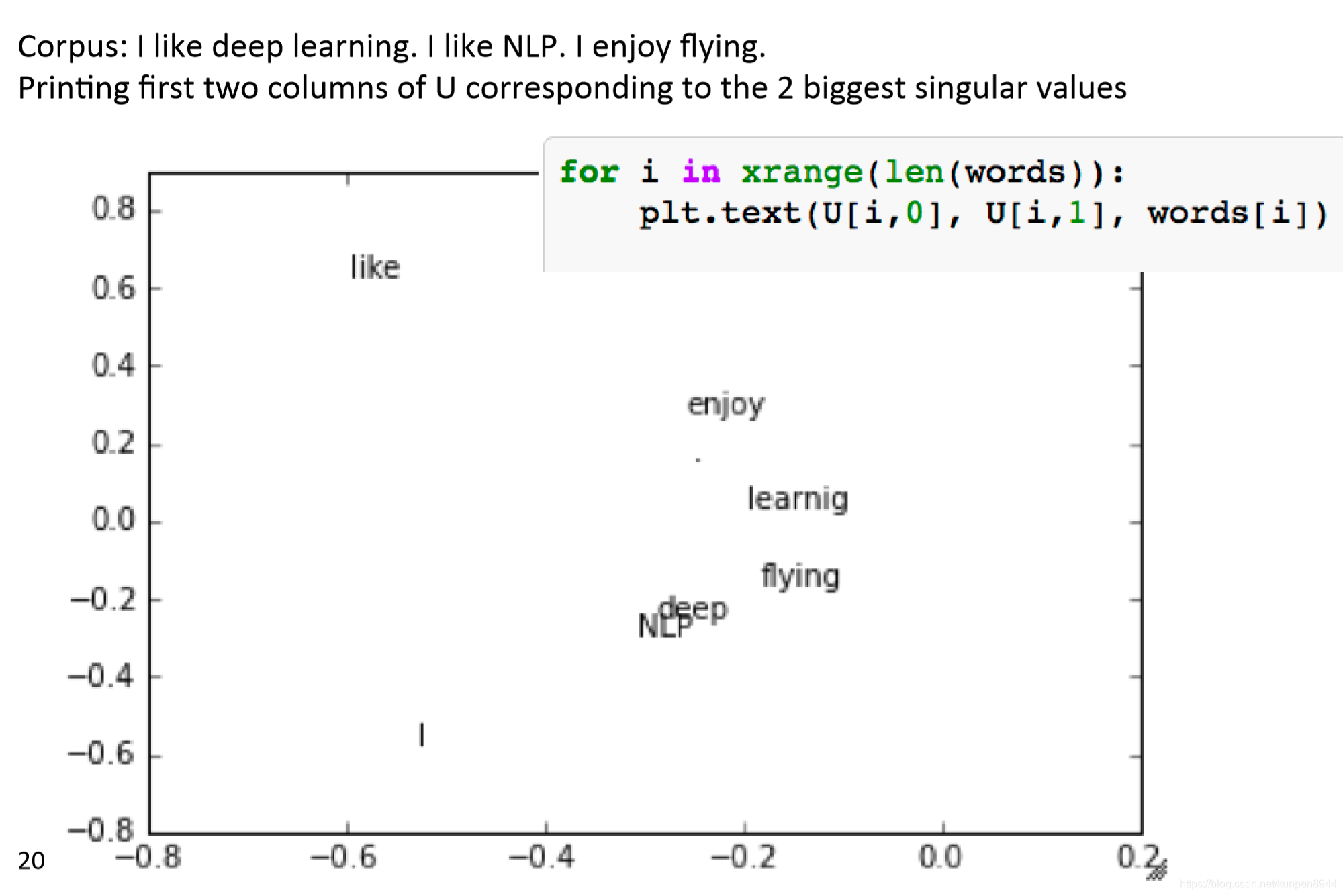
一個例子:視窗長度是1,一般視窗長度是5-10;左右兩邊的視窗長度是對稱的,語料庫示例:
- I like deep learning.
- I like NLP.
- I enjoy flying.
統計出來的矩陣如下:

這個矩陣存在的問題是:隨著詞彙的增長,儲存矩陣需要的空間將會變得很大;這個矩陣十分稀疏,不利於模型的穩健構建。所以,我們需要尋找一個方法把這個矩陣降低維度。
方法一:對矩陣X進行降維
對矩陣進行奇異值分解(SVD)

python程式碼:

單詞繪圖
一些關於矩陣X的改進
- the、he、has等這些單詞出現的頻率太高了,但他們幾乎出現在每個單詞的上下文中的時候,它本身也就無法給出一些更有用的資訊了。解決方法是有兩個,一是對單詞同時出現的次數設定一個上限,min(X,t),t~100;或者乾脆無視這些單詞。
- 給那些距離中心詞更近的單詞更多的權重
- 利用皮爾森相關係數來替代計數,用0來替代負數
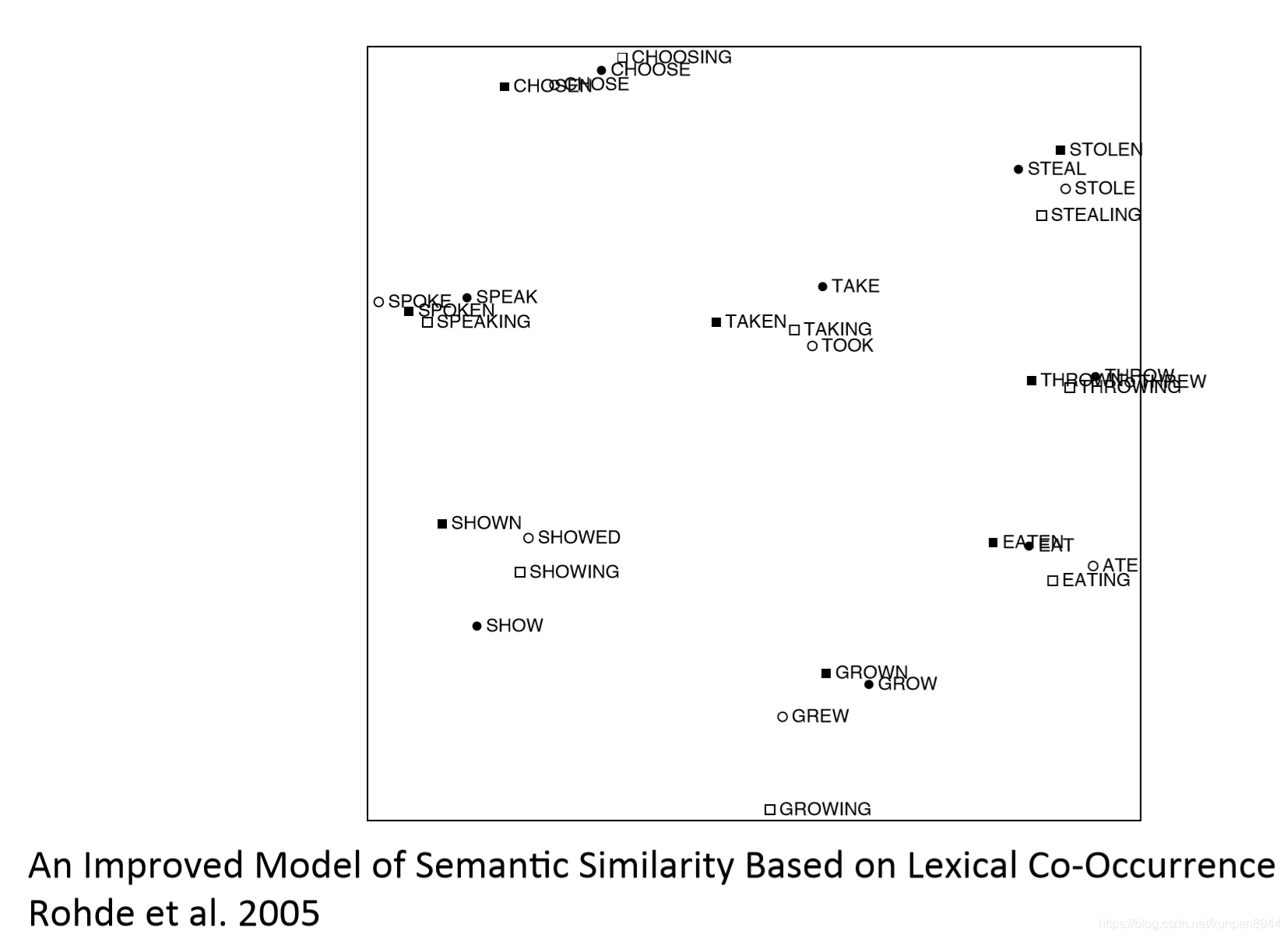
同時出現(cooccurrence)矩陣在句法和語義上的體現


SVD存在的問題:
- 計算代價是O(mn²),對於大量的文字和單詞而言,計算代價就會變得很大
- 很難把新的單詞和矩陣整合進矩陣中,往往會需要重新計算
基於計數的方法VS基於預測的方法
- 計數方法:訓練起來更快;可以充分利用統計資訊;主要用來計算單詞的相似度;對那些出現頻率很高的單詞而言,給出的重要性是不成正比的
- 預測方法(右邊):隨著語料庫的大小而規模大小變換;沒有充分使用到統計資訊;在其他的任務上有很好的表現;除了單詞相似性以外還可以獲得更復雜的模式

方法二:計數與直接預測的結合Glove
這個方法的目標函式如下:

其中f如下圖,目的是控制出現次數比較多的單詞對的權重。

方法的特點:
- 訓練起來很快
- 可以擴充套件成更大的語料庫
- 在小的語料庫和小的向量的情況下,表現也很好
這個方法的訓練結果是u和v兩個矩陣,都代表了相似的同時出現(cooccurrence)的資訊。最終,最好的X是U+V。
從Glove的訓練結果來看,這個模型對比較稀有的單詞也有比較好的效果。

三、詞向量的評估
NLP的評估分為兩種,Intrinsic 和extrinsic
- 內部的(Intrinsic)
- 基於一個特定的中間的子任務
- 計算起來很快
- 幫助我們理解系統
- 但是我們無法確定評估出來比較好的詞向量是否真的可以在實際任務中發揮作用
- 外部的(extrinsic)
- 基於一個實際任務進行評估
- 可能需要花費很長的時間來計算正確率
- 無法判斷是這個子系統的作用,還是互動作用,還是其他子系統的作用
- 如果只是替換了一個子系統,而正確率提升了的話,就說明這個子系統是有效的
1、內部(Intrinsic)方式
利用詞向量類比詞類進行評估,如下圖,比如b代表woman,a代表man,c表示king,那麼在剩下的單詞中,正確的類比單詞應該是cosine相似度最高的。在實際中應該是queen,通過判斷d是不是queen可以用來評估這個詞向量的構造情況。


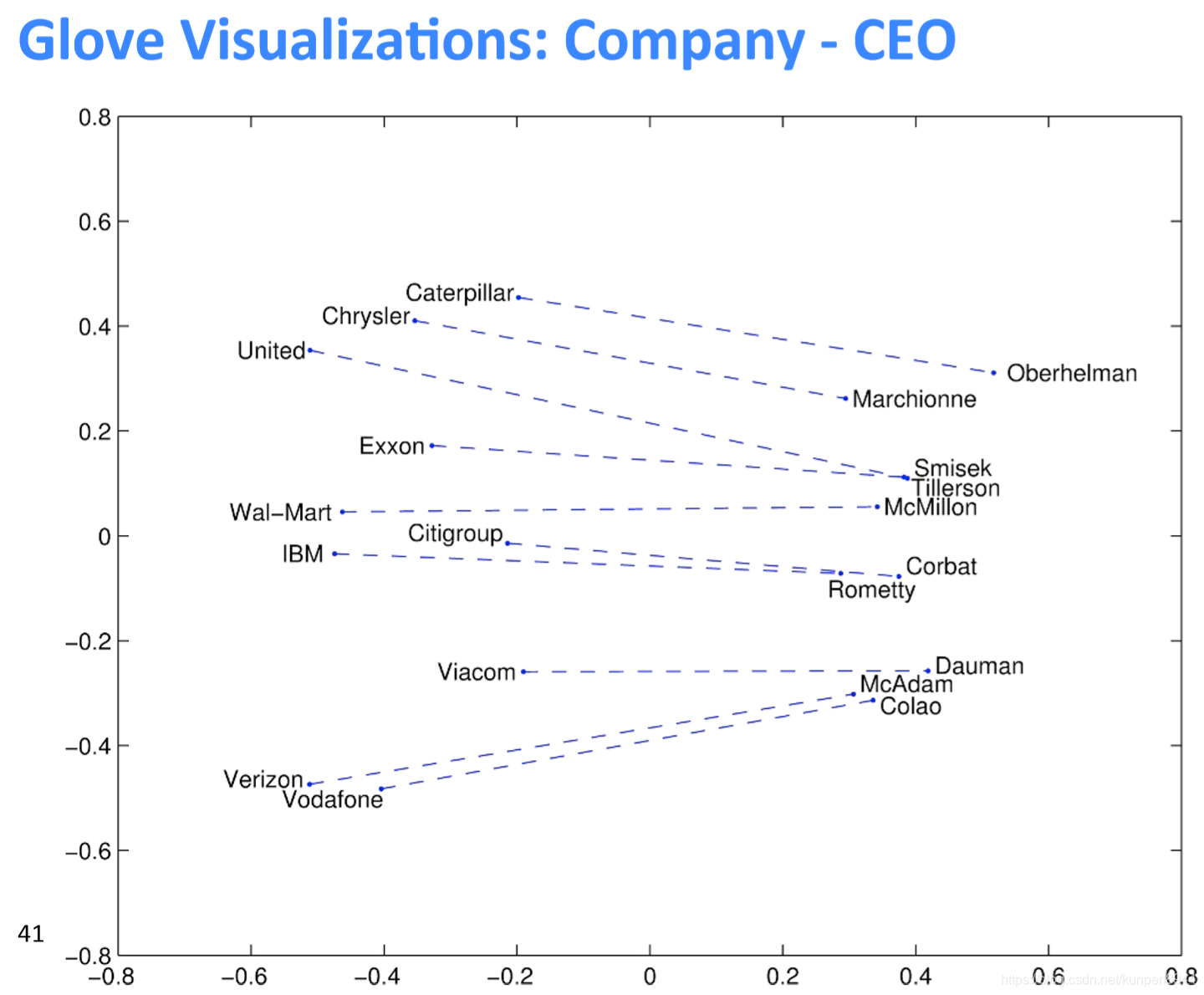
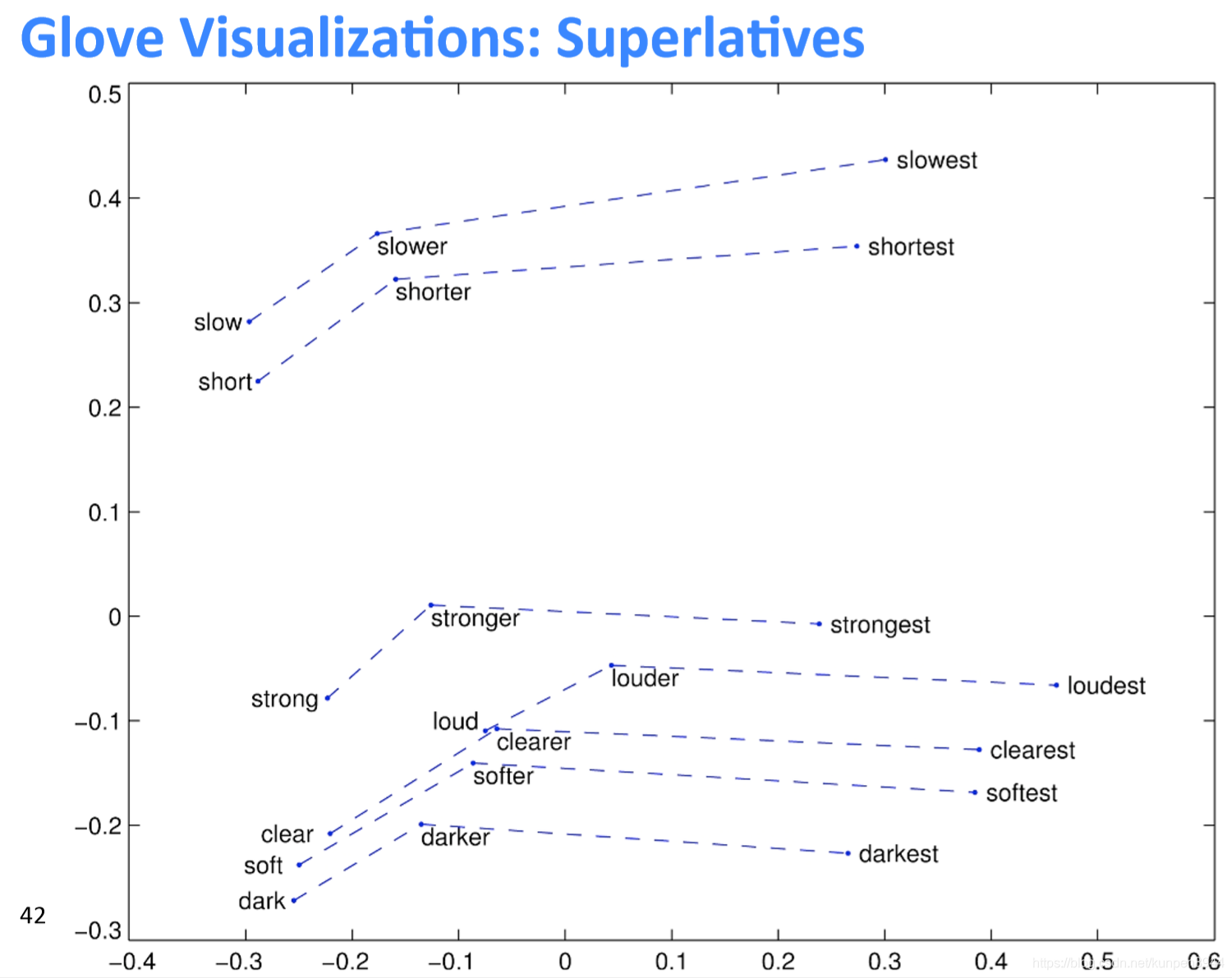
詞向量類比詞的一些例子:Word Vector Analogies: Syntactic and Semantic examples from http://code.google.com/p/word2vec/source/browse/trunk/quesRonswords.txt
利用詞向量類比詞進行評估和超參的選擇

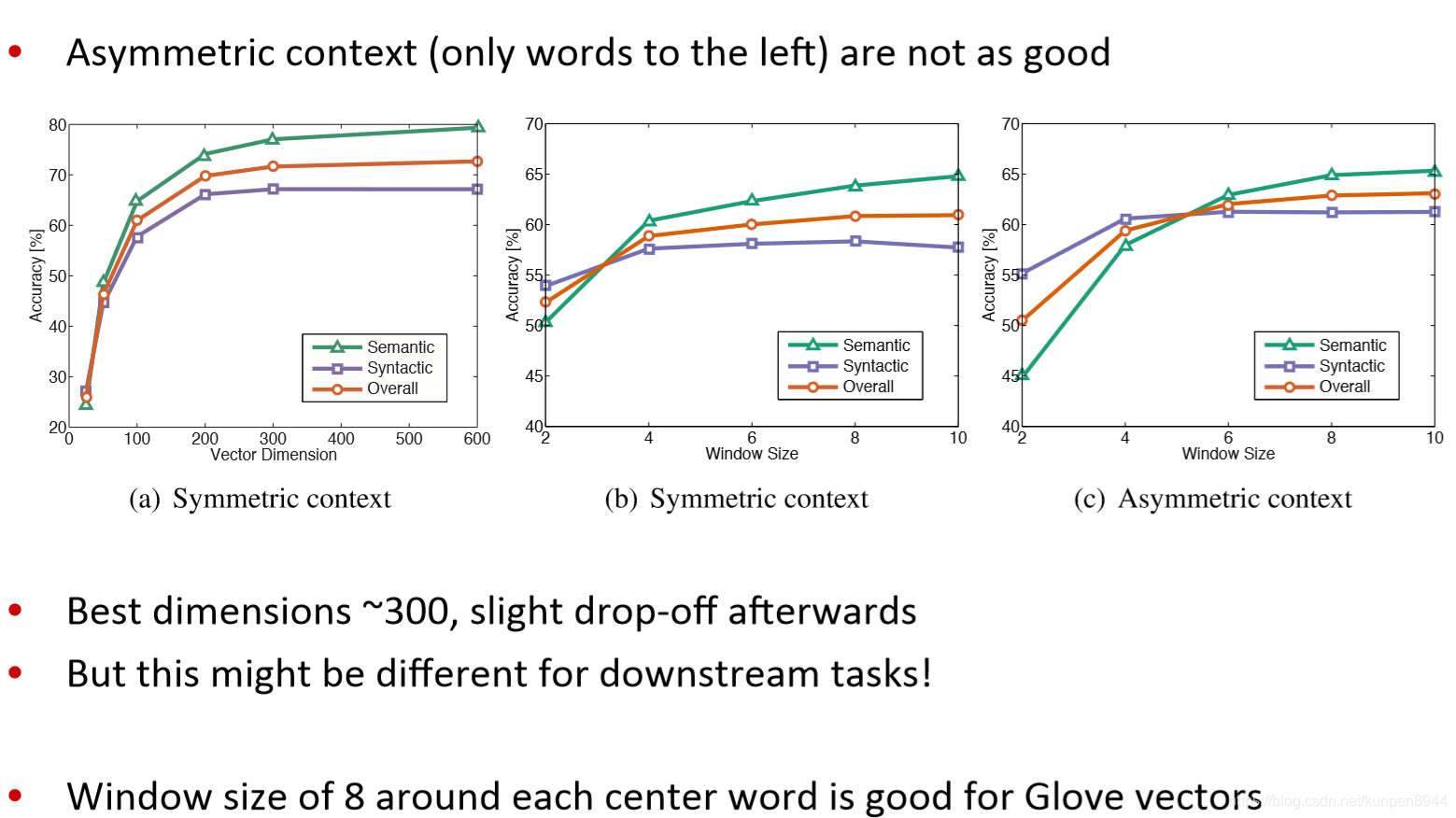
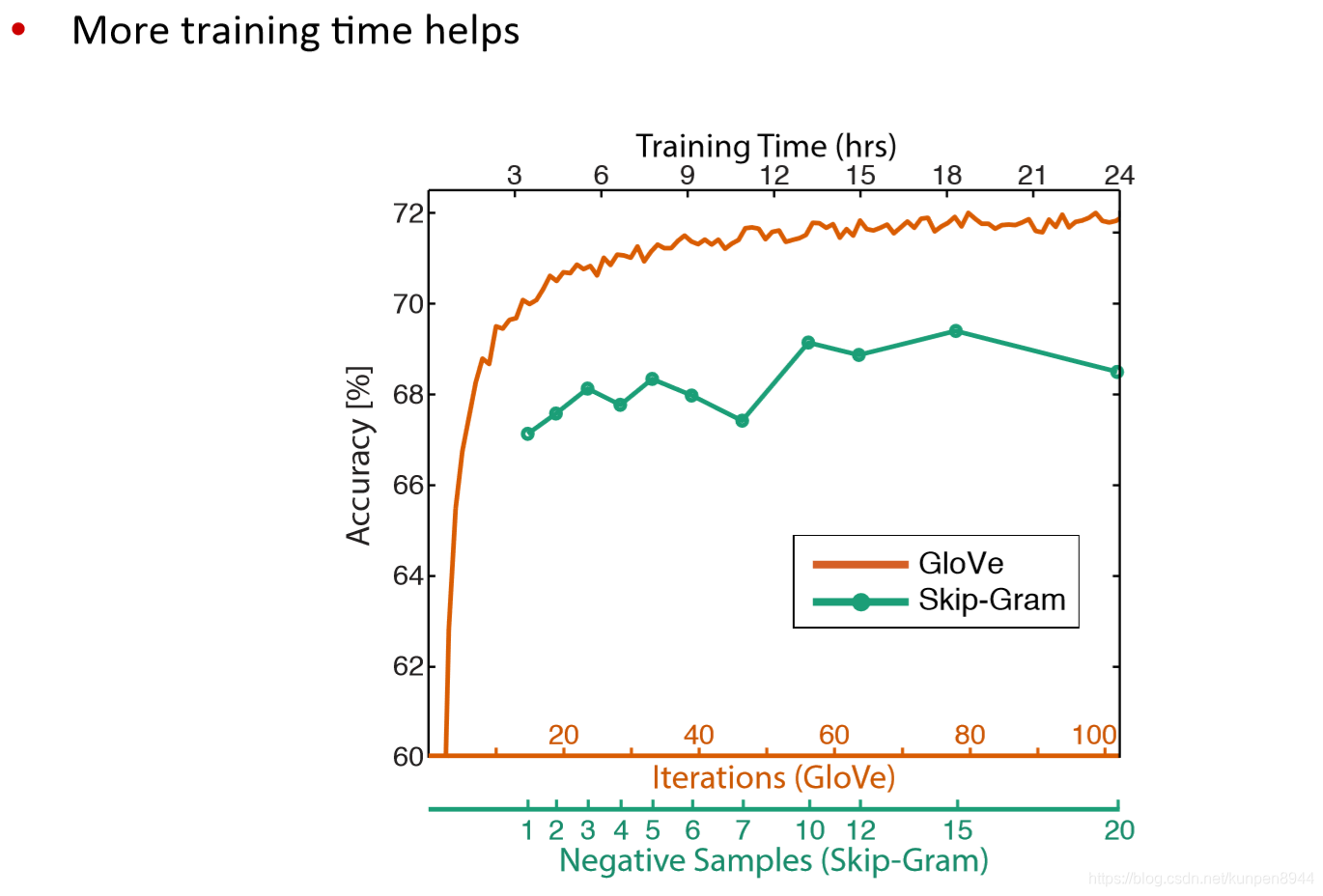
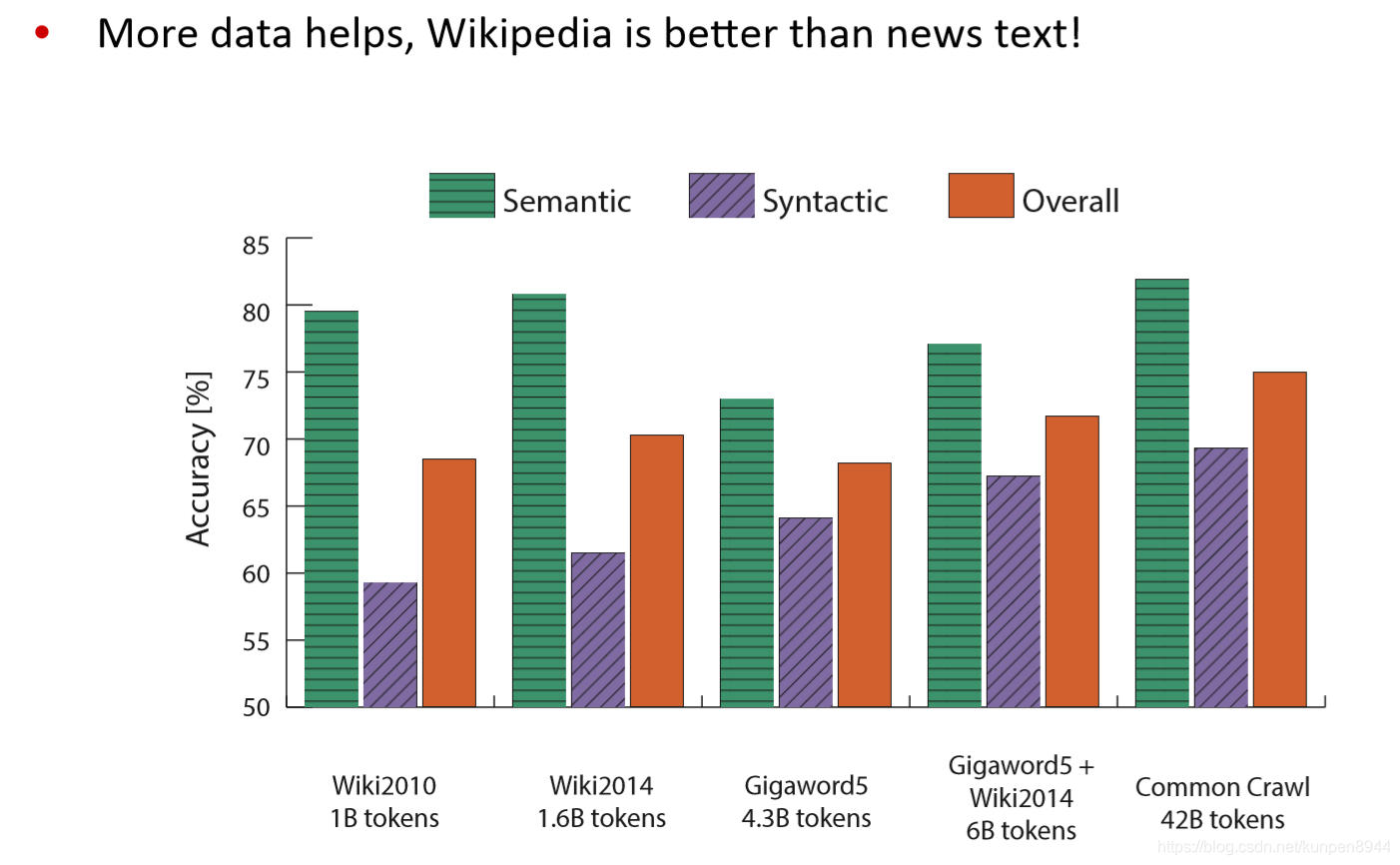 其他內部的詞向量評估方法:計算詞向量的距離以及人工判斷之間的相關性(correlation)
其他內部的詞向量評估方法:計算詞向量的距離以及人工判斷之間的相關性(correlation)



2、外部(extrinsic)方式
一個比較直接的例子是使用詞向量進行命名實體識別(named entity recognition)(相關定義和方法可以參考斯坦福大學-自然語言處理入門 筆記 第九課 資訊抽取)
從下面的比較中可以看到,即使是在外部評估方法下,GloVe的表現也是很好的。
