
CERT Secure Coding Standard — C語言安全程式設計規範
原文:http://www.huangwei.me/blog/2011/02/03/cert-secure-coding-standard-1/
譯序
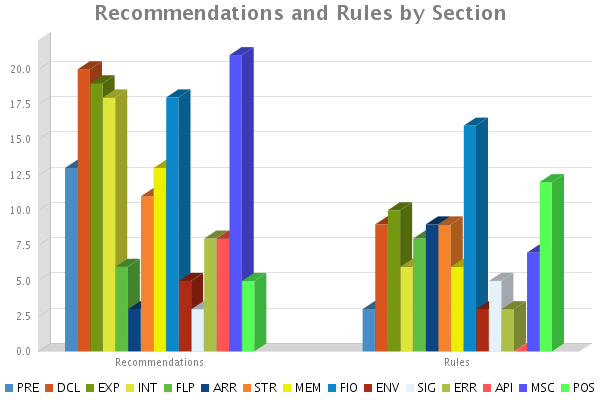
看完cert的C安全程式設計規範已經有2個多月了,我在閱讀的過程中順手把官方文件的主要目錄翻譯了一 下,其中包含了171條“建議”和106條“規則”,個人認為把這些作為一個C語言安全程式設計規範的cheatsheet是相當不錯的。
說明:
1.關於“ 建議(Recommendation)”:可以理解為“可選”的規範,一般是和最終軟體產品的安全需求有關。遵循“建議”有助於改進系統安全性。
2.關於“規則(Rules)”:可以理解為“強制”的規範。違反“規則”的編碼實踐有可能導致產生“可被利用的漏洞”。程式設計實踐與該規則的一致性 可以通過自動化分析、形式化方法或者手工檢測技術驗證。“規則”是確保使用C語言所開發的軟體系統安全性的必要條件
3. 規則編號規則:
- 前3個字母標示規範所屬的章節。
- 2位數字取值範圍:00-99。其中00-29保留用於“建議”,30-99保留用於“規則”。
- -後面的字母表示程式語言,如C。
4. 部分規則/建議是有”例外“的,需要特別注意。
| Section | Recommendations | Rules |
|---|---|---|
| PRE | 13 | 3 |
| DCL | 20 | 9 |
| EXP | 19 | 10 |
| INT | 18 | 6 |
| FLP | 6 | 8 |
| ARR | 3 | 9 |
| STR | 11 | 9 |
| MEM | 13 | 6 |
| FIO | 18 | 16 |
| ENV | 5 | 3 |
| SIG | 3 | 5 |
| ERR | 8 | 3 |
| API | 8 | 0 |
| MSC | 21 | 7 |
| POS | 5 | 12 |
| Recommendations | Rules | |
| TOTAL | 171 | 106 |
總目錄
| 規則/建議條目全稱 | 例外 | 筆記 /備註/點評 | ||||||||||||||||
|
PRE00-EX1: 可以用巨集實現區域性函式(重複出現的程式碼片斷可以訪問所包圍作用域範圍內的自動變數),但無法用行內函數實現 PRE00-EX2: 巨集可以用於進行識別符號連線或字串拼接操作 PRE00-EX3: 巨集可以用於產生編譯時常量,使用行內函數則不能保證一定產生的是編譯時常量 PRE00-EX4: 巨集可以“模擬”實現”泛型”函式,類似的機制在C++中是通過模板來實現的。典型的swap函式就可以通過巨集機制來實現泛型的效果。 PRE00-EX5: 巨集引數表現出的是“通過名稱”呼叫機制,函式則是“通過值”呼叫。在必須實現“傳名稱”機制時,就得使用巨集來實現 |
行內函數機制是在C99標準中引入的,C90標準可以使用靜態函式。 內聯替換既不是簡單的文字替換也不會建立一個新函式,行內函數的優化過程是由編譯器完成的,與程式設計師輸入無關。 使用行內函數前需要考慮: (1) 目標編譯器支援情況; (2) 使用後對系統性能的可能影響; (3) 移植性需求 |
|||||||||||||||||
|
PRE01-EX1: 巨集引數被替換列表中包含逗號時不需要遵循本建議。例項如下:
PRE01-EX2: 使用巨集的##和#機制使用符號拼接、字串轉換時不需要遵循本建議。例項如下:
|
||||||||||||||||||
PRE02-EX1: 巨集被展開為單個識別符號或函式呼叫時可以不遵循此建議。例項如下:
PRE02-EX2: 巨集被展開為一個包含陣列下表訪問符[]、結構體或共用體成員訪問符. 或 ->時可以不遵循此建議。例項如下:
|
||||||||||||||||||
例項如下:
|
||||||||||||||||||
| 如果使用和標準標頭檔案名相同的檔名,並且該自定義的標頭檔案也在“標頭檔案搜尋路徑”中,則其行為是“未定義”的。 | ||||||||||||||||||
例項如下:
|
||||||||||||||||||
|
根據C99標準定義,以下三個符號連在一起會被自動轉換為特定的單個符號,如下:
|
||||||||||||||||||
| PRE08-EX1: 一方面C99標準僅僅要求檔名的前8個字元是非常重要的; 另一方面,現代的作業系統和編譯器都是支援長檔名的。 | 我個人認為最需要注意的是檔名大小寫的問題,Windows系統上預設是不區分檔名大小寫的,而*nix系統上則是區分檔名的大小寫。因此,對於需要跨平臺工作的程式碼,務必注意不要通過檔名大小寫來區別不同檔案。 | |||||||||||||||||
| 這種情況通常發生在程式碼移植時,某個目標平臺上缺少相應的安全版本函式時程式設計師為了省事,直接用巨集定義用已有的不安全版本函式來“冒充”安全版本函式。 | ||||||||||||||||||
正確例項如下:
|
||||||||||||||||||
在巨集定義中使用表示式和操作符時需要小心,要避免“未定義”行為(巨集中的操作符執行順序、次數等都是“未定義”的)。危險例項程式碼如下:
|
||||||||||||||||||
| 形如\unnnnnnnn或\unnnn的通用字元名(universal character name),根據C99標準中的定義:通過符號拼接方式(##)建立的通用字元名的行為是“未定義”的。本規則主要是提醒不要在程式碼中使用通用字元名作為變數名或識別符號。 | ||||||||||||||||||
| 諸如#ifdef、#define、#include之類的預處理指令如果包含在巨集引數列表中,其行為根據C語法標準是“未定義”的。 |
| 規則/建議條目全稱 | 例外 | 筆記 /備註/點評 | |||||||||||||||||||||||
| DCL00-EX1: 可以定義無值的巨集來防止標頭檔案的重複包含問題。 | 除了使用const修飾符來“強制”定義一個物件為“不變”之外,也可以使用列舉常量或巨集定義。 | ||||||||||||||||||||||||
| DCL01-EX1: 函式宣告和定義分開的宣告時的引數名,只要定義時的引數名不和作用域範圍內的變數名衝突即可。 | 避免變數名作用域範圍的“二義性”,降低程式碼的可讀性和可維護性 | ||||||||||||||||||||||||
| 類似0和o,l和1等等。特別注意那些在某些字型顯示下幾乎無差別的兩個不同字元。 | |||||||||||||||||||||||||
|
C1X標準草稿C++ 0X標準草稿中新引入了一個靜態斷言函式
|
|||||||||||||||||||||||||
| DCL04-EX1: for的多重迴圈語句中的多個控制變數宣告是個例外。 |
提高程式碼的可讀性和可維護性 | ||||||||||||||||||||||||
| DCL06-EX1: 儘管使用有意義的符號來代替“無意義”的數字是有價值的,但在實際執行時要注意不能“過猶不及”。 |
|
||||||||||||||||||||||||
|
|||||||||||||||||||||||||
| 提高程式碼的可讀性。實際使用注意errno_t型別是否有庫檔案的定義支援(一般定義在errno.h,雖然errno_t一般就是定義為int)。 | |||||||||||||||||||||||||
| 可變引數的引數型別是不會被編譯器檢查型別的,因此需要函式作者自己檢查引數型別,並處理型別轉換 | |||||||||||||||||||||||||
| C語言中實現抽象資料型別並實現“私有化”的一般方法是通過資料型別的宣告和定義分開在兩個不同的標頭檔案中實現,在“公開”標頭檔案中只引用資料並重新typedef,提供資料的訪問方法,不提供資料定義語句。在“私有”標頭檔案中定義資料型別。 | |||||||||||||||||||||||||
| 這裡的指標引數常量值泛指函式的引數是一個指標,且該指標所指向的值不會在函式執行過程中被改變 | |||||||||||||||||||||||||
| 按照C語言規範標準,宣告為volatile的變數禁止編譯器快取優化,但在實際的編譯器實現中,部分編譯器的支援有bug,所以要小心使用這個修飾符。 | |||||||||||||||||||||||||
| 如果不指定void引數,而是使用空白引數列表,則編譯器不會在編譯時檢查函式呼叫的引數列表。因此,呼叫該函式時使用任意引數都不會導致編譯器產生錯誤,甚至不會產生任何編譯警告。 | |||||||||||||||||||||||||
| C99標準中新定義了一種複合文字型別(compound literal): 用成對的小括號包圍一個數據型別名,然後緊跟一個大括號對包圍的初始化值列表。複合文字型別的值是大括號對包圍的初始化值列表初始化的一個匿名物件。該匿名物件值的儲存型別有可能是static(如果該複合文字變數是檔案作用域範圍),或者automatic(如果該複合文字變數是程式碼塊作用域範圍) | |||||||||||||||||||||||||
| 物件的生儲存週期有三種:static、automatic和allocated,如果訪問了超過生存週期的物件會導致“未定義”行為並且產生一個可被利用的漏洞。 | |||||||||||||||||||||||||
| C90標準允許隱式宣告變數和函式,C99標準已經禁用了隱式宣告。隱式宣告可能會產生一些很難發現的bug | |||||||||||||||||||||||||
| 最典型的錯誤就是兩個變數名的前31個字元是相同的,只有第32個字元不同,這在某些編譯器看來就是兩個相同的變數名。 | |||||||||||||||||||||||||
| 這個規則的目的是禁止編譯器級別的“過度”優化。例如非同步訊號處理過程中的變數修改可能是編譯器不可見的,如果編譯器“自作聰明”的快取資料可能會導致“未期”的資料同步失敗 | |||||||||||||||||||||||||
|
預留實現的識別符號型別包括:
點評:C語言的變數、函式命名就是一個杯具,這時候就體現出C++名字空間的巨大意義了 |
|||||||||||||||||||||||||
|
宣告包含變長陣列成員的結構體時有三點需要注意:
|
|||||||||||||||||||||||||
| 不同編譯器有自己的結構體對齊或禁止對齊指令或擴充套件函式,也可以在結構體初始化使用memset人為的將可能的填充位置先初始化為0,避免可能的資訊洩漏問題 |
| 規則/建議條目全稱 | 例外 | 筆記 /備註/點評 | |
| 注意位元組對齊時的填充位元組問題,很多編譯器都提供一些標誌位或控制指令來管理結構體的記憶體對齊和填充行為 | |||
| 所謂副作用主要指的是sizeof的運算物件最好不要包含可能會引起自身值改變的運算子,sizeof運算物件中包含的表示式是否執行是“未確定”的。 | |||
| 常量的值也有可能會隨著具體環境變化而變化,但我們只要堅持在表示式中使用的是常量名,而不是想當然的直接使用其值,就可以真正發揮常量的作用,享受常量定義帶給我們的好處 | |||
| 指標加法運算需要注意加數會被自動“縮放”乘以指標所指向的目標資料型別的單位長度 | |||
| EXP09-EX1: C99標準明確宣告sizeof(char)==1。因此任何基於字元或字元陣列的資料型別大小計算可以不使用sizeof, 但這不適用於char *和任何其他資料型別。 |
|||
|
EXP10-EX1: &&和||可以保證表示式的執行順序是 自左向右,第一個運算元執行後會產生一個順序執行點。 EXP10-EX2: 條件表示式( ? : )的第一個運算元執行後會產生一個順序執行點。第二個運算元當且僅當第一個運算元的執行結果不等於0; 第三個運算元當且僅當第一個運算元的執行結果等於0; EXP10-EX3: 函式呼叫前存在一個順序執行點,即函式名、實參、實參中的子表示式都會確定在函式呼叫前被執行。 EXP10-EX4:逗號運算子的左運算元總是先於右運算元執行,在左運算元執行完後會產生一個順序執行點。 需要特別注意的是:函式引數列表中的逗號不是逗號運算子,只是用來分隔引數的。函式的多個引數的執行順序可以是任意的,沒有確定順序! |
這是C99標準裡的一個經典“未確定”行為,執行結果是具體環境相關的 | ||
|
C語言的資料型別轉換是完全基於記憶體的,由於不同系統的記憶體組織和排列差異性等問題,可能會導致相同的型別轉換語句在不同的系統上執行結果完全不相同。 bit結構儲存的差異性是主要的罪魁禍首,不同的系統的bit儲存順序、是否允許跨儲存單元邊界有可能不相同。 |
|||
|
EXP12-EX1: 如果函式的返回值無足輕重或者即使有錯誤也可以安全的被忽略的話。 EXP12-EX2: 如果一個函式永遠不會執行失敗或者返回值不存在錯誤值,返回值就可以忽略。例如strcpy函式。 |
|||
|
C語言中的關係運算符具有”左結合性”,即諸如a<b<c的語句,等效於(a<b)<c。如果a<b成立,則實際語句執行效果等效於1<c。 有時候可以利用這種結合性寫一些比較geek的程式碼,但實際上這不利於程式碼的維護,也會降低程式碼的可讀性。 |
|||
| 對小於int的整數型別執行運算時會被自動“型別提升”。如果原始資料都可以用int表示,則原始的較低型別資料會被自動轉換為int;否則,會被自動提升為unsigned int。如果是轉換為更大的資料型別,則原始的無符號整數會被填0擴充,原始的有符號整數會被帶符號擴充。因此,對小於int的整數型別執行按bit運算可能會產生意外的結果。 | |||
| 通常都是“筆誤”的象徵,一般我們在條件語句中都是使用邏輯與和或操作,而不是按位與、或操作 | |||
| 通常斷言是否生效依賴於程式碼在編譯時是否定義了NDEBUG巨集 | |||
| 否則是一個“未定義”行為,C語言的函式也許不會直接返回一個數組,但可能返回一個包含陣列的共用體或者結構體。即不要在同一條語句中試圖同時先呼叫函式再訪問或修改這個函式的陣列返回值 | |||
|
offsetof()巨集提供了一種可移植的計算結構體成員在結構體中的相對記憶體偏移量的方法,該巨集的執行結果是一個常量表達式,值的型別為size_t,表示目標結構體成員在目標結構體中的相對記憶體偏移量是多少bytes。 如果使用offsetof()計算結構體中的bit域成員或者是非法成員名,其行為是“未定義”的。 bit域成員例項如下:
上面的例子中,只需要將
改為:
即可。 |
|||
| 指標的算術運算僅在指標指向一個數組型別才有意義,並且當執行指標的算術運算時,加數和減數都會自動“乘以”一個係數(指標所指向的陣列物件的單個元素的大小) |