
Spark學習——spark中的幾個概念的理解及引數配置
首先是一張spark的部署圖:
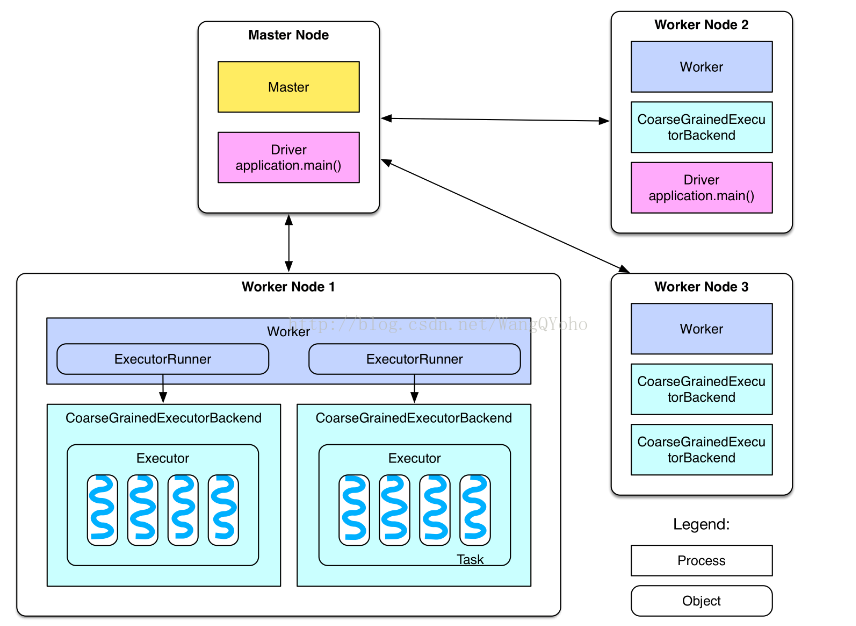
節點型別有:
1. master 節點: 常駐master程序,負責管理全部worker節點。
2. worker 節點: 常駐worker程序,負責管理executor 並與master節點通訊。
dirvier:官方解釋為: The process running the main() function of the application and creating the SparkContext。即理解為使用者自己編寫的應用程式
一、Application
application(應用)其實就是用spark-submit提交的程式。比方說spark examples中的計算pi的SparkPi。一個application通常包含三
部分:從資料來源(比方說HDFS)取資料形成RDD,通過RDD的transformation和action進行計算,將結果輸出到console或者外部存
儲(比方說collect收集輸出到console)。
二、Driver
主要完成任務的排程以及和executor和cluster manager進行協調。有client和cluster聯眾模式。client模式driver在任務提交的機器上
執行,而cluster模式會隨機選擇機器中的一臺機器啟動driver。從spark官網截圖的一張圖可以大致瞭解driver的功能。

三、Executor
在每個WorkerNode上為某應用啟動的一個程序,該程序負責執行任務,並且負責將資料存在記憶體或者磁碟上,每個任務都有各自獨
立的Executor。
Executor是一個執行Task的容器。它的主要職責是:
1、初始化程式要執行的上下文SparkEnv,解決應用程式需要執行時的jar包的依賴,載入類。
2、同時還有一個ExecutorBackend向cluster manager彙報當前的任務狀態,這一方面有點類似hadoop的tasktracker和task。
總結:Executor是一個應用程式執行的監控和執行容器。Executor的數目可以在submit時,由 --num-executors (on yarn)指定.
四、Job
包含很多task的平行計算,可以認為是Spark RDD 裡面的action
使用者提交的Job會提交給DAGScheduler,Job會被分解成Stage和Task。
五、Task
即 stage 下的一個任務執行單元,一般來說,一個 rdd 有多少個 partition,就會有多少個 task,因為每一個 task 只是處理一個
partition 上的資料。
每個executor執行的task的數目, 可以由submit時,--num-executors(on yarn) 來指定。
六、Stage
一個Job會被拆分為多組Task,每組任務被稱為一個Stage就像Map Stage, Reduce Stage。
Stage的劃分在RDD的論文中有詳細的介紹,簡單的說是以shuffle和result這兩種型別來劃分。在Spark中有兩類task,一類是
shuffleMapTask,一類是resultTask,第一類task的輸出是shuffle所需資料,第二類task的輸出是result,stage的劃分也以此為依
據,shuffle之前的所有變換是一個stage,shuffle之後的操作是另一個stage。比如 rdd.parallize(1 to 10).foreach(println) 這個操作沒
有shuffle,直接就輸出了,那麼只有它的task是resultTask,stage也只有一個;如果是rdd.map(x => (x, 1)).reduceByKey(_ +
_).foreach(println), 這個job因為有reduce,所以有一個shuffle過程,那麼reduceByKey之前的是一個stage,執行shuffleMapTask,
輸出shuffle所需的資料,reduceByKey到最後是一個stage,直接就輸出結果了。如果job中有多次shuffle,那麼每個shuffle之前都是
一個stage。
換句話來講,就要提到spark裡面的寬依賴和窄依賴:
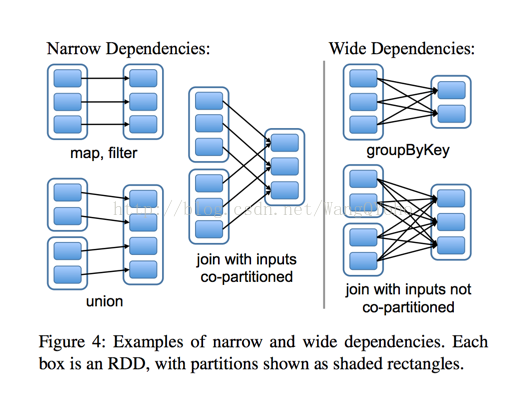
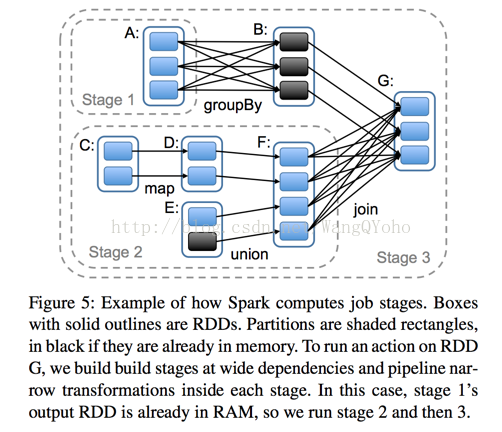
看一下父RDD中的資料是否進入不同的子RDD,如果只進入到一個子RDD則是窄依賴,否則就是寬依賴。寬依賴和窄依賴的邊界就
是stage的劃分點。從spark的論文中的兩張截圖,可以清楚的理解寬窄依賴以及stage的劃分。
上面大圖大字看得有點暈,下面這幅圖是找到的資料中比較清晰的:
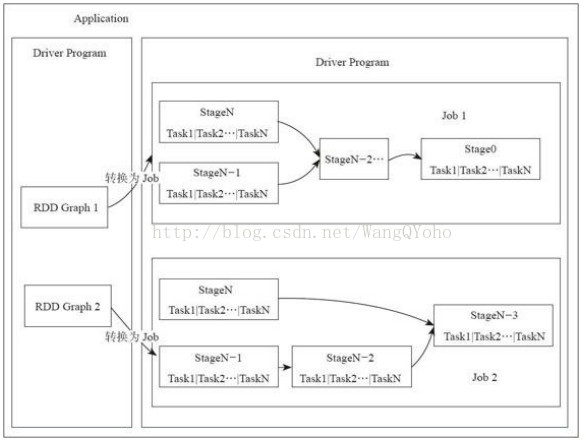
Application:Spark 的應用程式,使用者提交後,Spark為App分配資源,將程式轉換並執行,其中Application包含一個Driver program和若干Executor
SparkContext:Spark 應用程式的入口,負責排程各個運算資源,協調各個 Worker Node 上的 Executor
Driver Program:執行Application的main()函式並且建立SparkContext
RDD Graph:RDD是Spark的核心結構, 可以通過一系列運算元進行操作(主要有Transformation和Action操作)。當RDD遇到Action運算元時,將之前的所有運算元形成一個有向無環圖(DAG)。再在Spark中轉化為Job,提交到叢集執行。一個App中可以包含多個Job
Executor:是為Application執行在Worker node上的一個程序,該程序負責執行Task,並且負責將資料存在記憶體或者磁碟上。每個Application都會申請各自的Executor來處理任務
Worker Node:叢集中任何可以執行Application程式碼的節點,執行一個或多個Executor程序
Job:一個RDD Graph觸發的作業,往往由Spark Action運算元觸發,在SparkContext中通過runJob方法向Spark提交Job
Stage:每個Job會根據RDD的寬依賴關係被切分很多Stage, 每個Stage中包含一組相同的Task, 這一組Task也叫TaskSet
Task:一個分割槽對應一個Task,Task執行RDD中對應Stage中包含的運算元。Task被封裝好後放入Executor的執行緒池中執行
DAGScheduler:根據Job構建基於Stage的DAG,並提交Stage給TaskScheduler
TaskScheduler:將Taskset提交給Worker node叢集執行並返回結果
從經驗角度來看,關於spark作業配置初始化引數應該參照:
在叢集中,建議為每一個 CPU 核( core )分配 3-4 個任務。
由於spark streaming是基於simple consumer api消費kafka topic,所以一個topic有多少個partition,就有多少個task。假設我們消費
的這個topic總共有40個partition,所以起初spark streaming的task數量為40。根據上面的建議 一個CPU核分3到4個任務(這個值具體看topic訊息量,
如果有很多訊息的話可以適當降低一個cpu的任務量),則初始化
時我們需要10個core。一個executor可以分配2到5個core,executor的memory根據處理的資料量自行設定,一般推薦2G
如果使用了spark sql或者很多資料處理是在Driver端,可以適當的調大Driver的memory,也推薦2G,Cpu預設使用一個core
所以上面的例子最後的配置為:driver-memory=2G,driver-cores=1,num-executors=2或者5,executor-cores=5或者2,executor-
memory=2G
PS:關於Spark調優的好文章