
物體檢測中常用的幾個概念遷移學習、IOU、NMS理解
1、遷移學習
遷移學習也即所謂的有監督預訓練(Supervised pre-training),我們通常把它稱之為遷移學習。比如你已經有一大堆標註好的人臉年齡分類的圖片資料,訓練了一個CNN,用於人臉的年齡識別。然後當你遇到新的專案任務是:人臉性別識別,那麼這個時候你可以利用已經訓練好的年齡識別CNN模型,去掉最後一層,然後其它的網路層引數就直接複製過來,繼續進行訓練。這就是所謂的遷移學習,說的簡單一點就是把一個任務訓練好的引數,拿到另外一個任務,作為神經網路的初始引數值,這樣相比於你直接採用隨機初始化的方法,精度可以有很大的提高。
圖片分類標註好的訓練資料非常多,但是物體檢測的標註資料卻很少,如何用少量的標註資料,訓練高質量的模型,比如我們先對imagenet圖片資料集先進行網路的圖片分類訓練。這個資料庫有大量的標註資料。
2、IOU(交併比)

物體檢測需要定位出物體的bounding box,就像上面的圖片一樣,我們不僅要定位出車輛的bounding box 我們還要識別出bounding box 裡面的物體就是車輛。對於bounding box的定位精度,有一個很重要的概念,因為我們演算法不可能百分百跟人工標註的資料完全匹配,因此就存在一個定位精度評價公式:IOU。
IOU表示了bounding box 與 ground truth 的重疊度,如下圖所示:
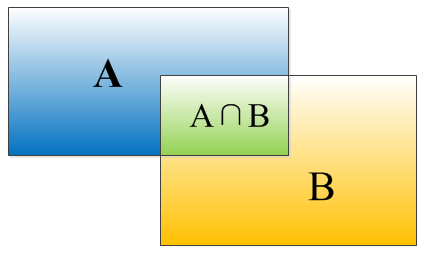
矩形框A、B的一個重合度IOU計算公式為:
IOU=(A∩B)/(A∪B)
就是矩形框A、B的重疊面積佔A、B並集的面積比例:
IOU=SI/(SA+SB-SI)
3、NMS
NMS也即非極大值抑制。在最近幾年常見的物體檢測演算法(包括rcnn、sppnet、fast-rcnn、faster-rcnn等)中,最終都會從一張圖片中找出很多個可能是物體的矩形框,然後為每個矩形框為做類別分類概率:

就像上面的圖片一樣,定位一個車輛,最後演算法就找出了一堆的方框,我們需要判別哪些矩形框是沒用的。
所謂非極大值抑制:先假設有6個矩形框,根據分類器類別分類概率做排序,從小到大分別屬於車輛的概率分別為A、B、C、D、E、F。
(1)從最大概率矩形框F開始,分別判斷A~E與F的重疊度IOU是否大於某個設定的閾值;
(2)假設B、D與F的重疊度超過閾值,那麼就扔掉B、D;並標記第一個矩形框F,是我們保留下來的。
(3)從剩下的矩形框A、C、E中,選擇概率最大的E,然後判斷E與A、C的重疊度,重疊度大於一定的閾值,那麼就扔掉;並標記E是我們保留下來的第二個矩形框。
就這樣一直重複,找到所有被保留下來的矩形框。