
記一次DataNode慢啟動問題
前言
最近一段時間,由於機房需要搬遷調整,我們hadoop叢集所受到的影響機器無疑是數量最多的,如何能最優的使機器在從1個機房搬到另1個機房之後,對叢集的資料和上面跑的業務造成儘可能小的影響或者說幾乎沒有影響.這就是我們想到達到的目標.但是在實施這整個搬遷的過程中,還是發現了一些比較有意思的現象的,於是就有了如文章標題所描繪的現象,為什麼說是"記一次"呢,因為這個現象並不是每次都發生,所以這件事看上去可能就不會那麼直接明瞭了.相信你在看完了文章之後,或多或少會有所收穫.
DataNode慢啟動現象"場景回放"
首先看到這個子標題,估計有人會有疑問,DataNode還會出現慢啟動現象?DataNode執行了sbin/hadoop-daemon.sh start datanode命令後不是幾秒鐘的事情嗎?沒有錯,在絕大多數的場景下,DataNode的啟動就是簡單的這麼幾個步驟.但是不知道大家有沒有嘗試過如下的情況:
1.停止機器上的DataNode服務.
2.將此節點進行機房搬遷,搬遷後此節點將會擁有新的主機名和IP.
3.在第二步驟的搬遷過程中耗費了20,30分鐘甚至長達數小時.
4.重啟被更換掉主機名,IP的DataNode.
我在最近一段時間的DataNode遷移中就遇到了上述的場景,(感興趣的同學可以檢視這篇文章)然後在我start新的DataNode之後,就發生了慢啟動的現象,在我執行完了指令碼之後,我發現NameNode的頁面上遲遲沒有這個新節點彙報上來的block塊記總數資訊.我用jps觀察這個程序也的確還是在的,直到最後過了4,5分鐘之後,頁面上終於出現了新DN的記錄資訊了.然後datanode的log中也出現了block的receive,delete記錄了.所以很顯然,DataNode在啟動的這4,5分鐘一定卡在了什麼操作上,否則不會出現這麼大延時.千萬不要小看了這4,5分鐘,當你需要在短時間內恢復dn服務的時候,哪怕你多耽擱了1秒鐘,影響了別人的使用,人家還是會認為這就是你的問題.既然目標已經鎖定在dn啟動的頭4,5分鐘,那麼1個好的辦法就是先看datanode的log日誌,看看他在幹嘛.經過多次嘗試,我發現dn在每次打完下面這些資訊的時候,就會停留相當長的時間.
2016-01-06 16:05:08,118 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Added new volume: DS-70097061-42f8-4c33-ac27-2a6ca21e60d4 2016-01-06 16:05:08,118 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Added volume - /home/data/data/hadoop/dfs/data/data12/current, StorageType: DISK 2016-01-06 16:05:08,176 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Registered FSDatasetState MBean 2016-01-06 16:05:08,177 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Adding block pool BP-1942012336-xx.xx.xx.xx-1406726500544 2016-01-06 16:05:08,178 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data2/current... 2016-01-06 16:05:08,179 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data3/current... 2016-01-06 16:05:08,179 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data4/current... 2016-01-06 16:05:08,179 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data5/current... 2016-01-06 16:05:08,180 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data6/current... 2016-01-06 16:05:08,180 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data7/current... 2016-01-06 16:05:08,180 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data8/current... 2016-01-06 16:05:08,180 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data9/current... 2016-01-06 16:05:08,181 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data10/current... 2016-01-06 16:05:08,181 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data11/current... 2016-01-06 16:05:08,181 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Scanning block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on volume /home/data/data/hadoop/dfs/data/data12/current... 2016-01-06 16:09:49,646 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Time taken to scan block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on /home/data/data/hadoop/dfs/data/data7/current: 281466ms 2016-01-06 16:09:54,235 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Time taken to scan block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on /home/data/data/hadoop/dfs/data/data9/current: 286054ms 2016-01-06 16:09:57,859 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Time taken to scan block pool BP-1942012336-xx.xx.xx.xx-1406726500544 on /home/data/data/hadoop/dfs/data/data2/current: 289680ms
我們可以從日誌中看到,在dn新增完磁碟塊後,程序scaning掃描操作的時候,在16:05分之後,就直接調到16:09的記錄,就是在最後1次Scanning block的那行.顯然就是這段時間導致的dn慢啟動.所以後面我們可以以此作為關鍵線索,進行分析,通過打出的日誌,1個有效的辦法就是通過日誌進行程式碼跟蹤發現.
程式碼追蹤分析
通過上個部分的日誌記錄資訊,顯示,這條資訊是FsDatasetImpl中的Log物件打出的,但是這個LOG物件其實是在另外1個叫FsVolumeList的類中被呼叫的,程式碼如下:
void addBlockPool(final String bpid, final Configuration conf) throws IOException {
long totalStartTime = Time.monotonicNow();
final List<IOException> exceptions = Collections.synchronizedList(
new ArrayList<IOException>());
List<Thread> blockPoolAddingThreads = new ArrayList<Thread>();
for (final FsVolumeImpl v : volumes.get()) {
Thread t = new Thread() {
public void run() {
try (FsVolumeReference ref = v.obtainReference()) {
FsDatasetImpl.LOG.info("Scanning block pool " + bpid +
" on volume " + v + "...");
long startTime = Time.monotonicNow();
v.addBlockPool(bpid, conf);
long timeTaken = Time.monotonicNow() - startTime;
FsDatasetImpl.LOG.info("Time taken to scan block pool " + bpid +
" on " + v + ": " + timeTaken + "ms");
} catch (ClosedChannelException e) {
// ignore.
} catch (IOException ioe) {
FsDatasetImpl.LOG.info("Caught exception while scanning " + v +
". Will throw later.", ioe);
exceptions.add(ioe);
}
}
};
blockPoolAddingThreads.add(t);
t.start();
}
for (Thread t : blockPoolAddingThreads) {
try {
t.join();
} catch (InterruptedException ie) {
throw new IOException(ie);
}
}
if (!exceptions.isEmpty()) {
throw exceptions.get(0);
}
long totalTimeTaken = Time.monotonicNow() - totalStartTime;
FsDatasetImpl.LOG.info("Total time to scan all replicas for block pool " +
bpid + ": " + totalTimeTaken + "ms");
}void addBlockPool(String bpid, Configuration conf) throws IOException {
File bpdir = new File(currentDir, bpid);
BlockPoolSlice bp = new BlockPoolSlice(bpid, this, bpdir, conf);
bpSlices.put(bpid, bp);
}/**
* A block pool slice represents a portion of a block pool stored on a volume.
* Taken together, all BlockPoolSlices sharing a block pool ID across a
* cluster represent a single block pool.
*
* This class is synchronized by {@link FsVolumeImpl}.
*/
class BlockPoolSlice {
...portion的意思為"一部分",所以大意就是1個block pool儲存在每塊盤上的一部分.比如你有3個塊盤,A,B,C,每個盤下都有對應目錄是存放此block pool id對應的資料.block pool id又是哪裡確定的呢,OK,這裡要單獨為大家理一理這方面的知識.
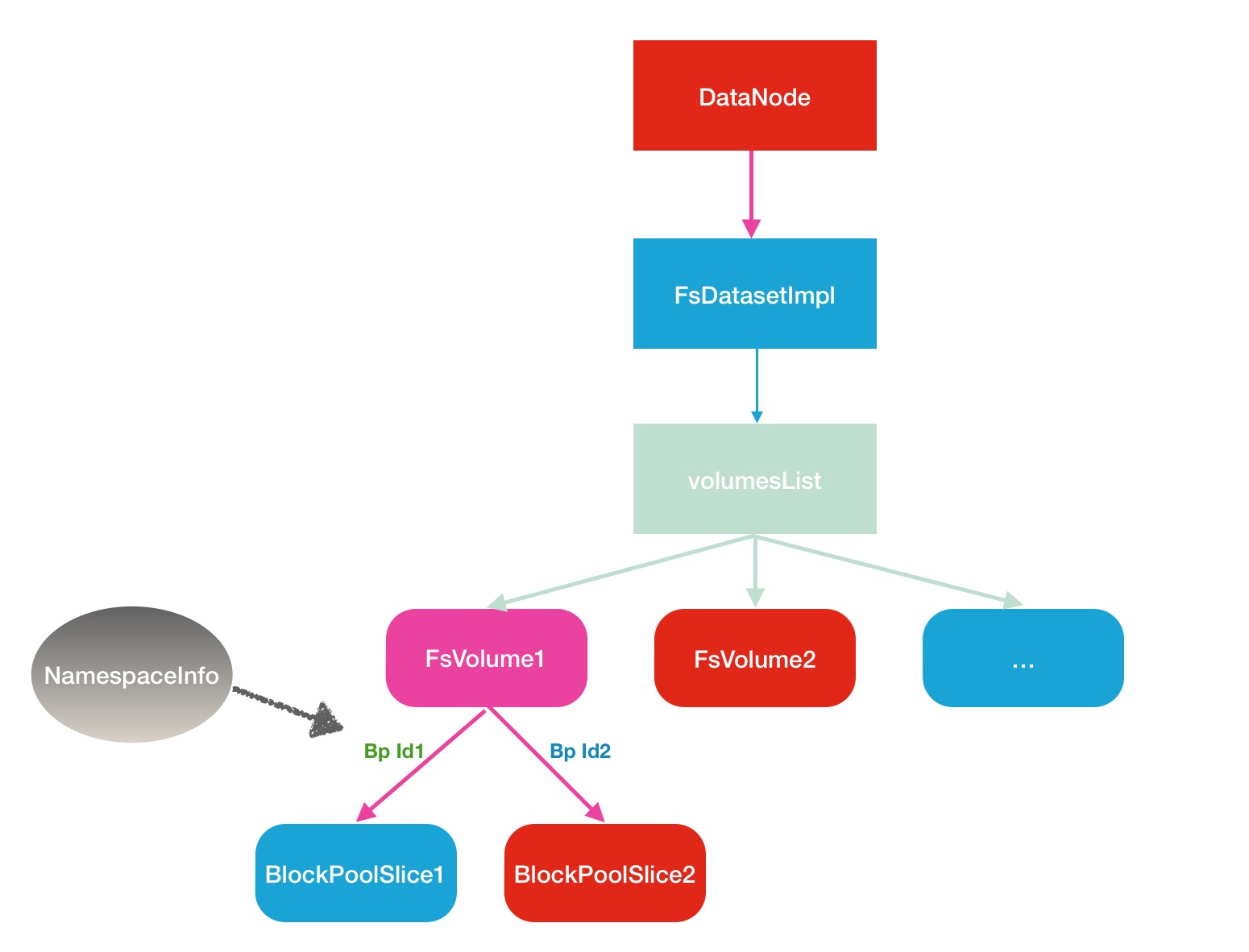
DataNode FsVolume磁碟相關邏輯關係
首先是Block Pool Id, 這個Id是在叢集第一次開始建立的時候確定的,就是在namenode做format操作的時候,不管在後續的叢集升級或者搬遷的時候,這個bp id都不會發生改變,儲存在了NamespaceInfo這個類中,下面是這個類的介紹說明:
/**
* NamespaceInfo is returned by the name-node in reply
* to a data-node handshake.
*
*/
@InterfaceAudience.Private
@InterfaceStability.Evolving
public class NamespaceInfo extends StorageInfo {
final String buildVersion;
String blockPoolID = ""; // id of the block pool
String softwareVersion;
long capabilities;
...
回到最初的問題,這些操作看起來一點都耗時啊,那我們就繼續看裡看,進入BlockPoolSlice的構造方法中:
/**
* Create a blook pool slice
* @param bpid Block pool Id
* @param volume {@link FsVolumeImpl} to which this BlockPool belongs to
* @param bpDir directory corresponding to the BlockPool
* @param conf configuration
* @throws IOException
*/
BlockPoolSlice(String bpid, FsVolumeImpl volume, File bpDir,
Configuration conf) throws IOException {
...
// Use cached value initially if available. Or the following call will
// block until the initial du command completes.
this.dfsUsage = new DU(bpDir, conf, loadDfsUsed());
this.dfsUsage.start();
// Make the dfs usage to be saved during shutdown.
ShutdownHookManager.get().addShutdownHook(
new Runnable() {
@Override
public void run() {
if (!dfsUsedSaved) {
saveDfsUsed();
}
}
}, SHUTDOWN_HOOK_PRIORITY);
}/**
* Read in the cached DU value and return it if it is less than 600 seconds
* old (DU update interval). Slight imprecision of dfsUsed is not critical and
* skipping DU can significantly shorten the startup time. If the cached value
* is not available or too old, -1 is returned.
*/
long loadDfsUsed() {
long cachedDfsUsed;
long mtime;
Scanner sc;
try {
sc = new Scanner(new File(currentDir, DU_CACHE_FILE), "UTF-8");
} catch (FileNotFoundException fnfe) {
return -1;
}
try {
// Get the recorded dfsUsed from the file.
if (sc.hasNextLong()) {
cachedDfsUsed = sc.nextLong();
} else {
return -1;
}
// Get the recorded mtime from the file.
if (sc.hasNextLong()) {
mtime = sc.nextLong();
} else {
return -1;
}
// Return the cached value if mtime is okay.
if (mtime > 0 && (Time.now() - mtime < 600000L)) {
FsDatasetImpl.LOG.info("Cached dfsUsed found for " + currentDir + ": " +
cachedDfsUsed);
return cachedDfsUsed;
}
return -1;
} finally {
sc.close();
}
}引數可配置化改造
目標已經非常明確了,就是將hard code變成可配置化,作為hdfs-site.xml的1個新配置項.下面簡要說明幾個步驟,首先在DfsConfigKeys裡新增key名稱和預設值:
public static final String DFS_DATANODE_CACHED_DFSUSED_CHECK_INTERVAL_MS =
"dfs.datanode.cached-dfsused.check.interval.ms";
public static final long DFS_DATANODE_CACHED_DFSUSED_CHECK_INTERVAL_DEFAULT_MS =
600000;/**
* A block pool slice represents a portion of a block pool stored on a volume.
* Taken together, all BlockPoolSlices sharing a block pool ID across a
* cluster represent a single block pool.
*
* This class is synchronized by {@link FsVolumeImpl}.
*/
class BlockPoolSlice {
...
private final long cachedDfsUsedCheckTime;
// TODO:FEDERATION scalability issue - a thread per DU is needed
private final DU dfsUsage;
/**
* Create a blook pool slice
* @param bpid Block pool Id
* @param volume {@link FsVolumeImpl} to which this BlockPool belongs to
* @param bpDir directory corresponding to the BlockPool
* @param conf configuration
* @throws IOException
*/
BlockPoolSlice(String bpid, FsVolumeImpl volume, File bpDir,
Configuration conf) throws IOException {
...
this.cachedDfsUsedCheckTime =
conf.getLong(
DFSConfigKeys.DFS_DATANODE_CACHED_DFSUSED_CHECK_INTERVAL_MS,
DFSConfigKeys.DFS_DATANODE_CACHED_DFSUSED_CHECK_INTERVAL_DEFAULT_MS);/**
* Read in the cached DU value and return it if it is less than
* cachedDfsUsedCheckTime which is set by
* dfs.datanode.cached-dfsused.check.interval.ms parameter. Slight imprecision
* of dfsUsed is not critical and skipping DU can significantly shorten the
* startup time. If the cached value is not available or too old, -1 is
* returned.
*/
long loadDfsUsed() {
...
// Return the cached value if mtime is okay.
if (mtime > 0 && (Time.now() - mtime < cachedDfsUsedCheckTime)) {
FsDatasetImpl.LOG.info("Cached dfsUsed found for " + currentDir + ": " +
cachedDfsUsed);
return cachedDfsUsed;
}
return -1;
} finally {
sc.close();
}
}<property>
<name>dfs.datanode.cached-dfsused.check.interval.ms</name>
<value>600000</value>
<description>The internal check time of loading cache-dfsused
value.
</description>
</property>然後自己編寫幾個testcase進行測試,單元測試在後面的patch連結中會給出.在DataNode重新部署上新的jar包,重啟DataNode.出現下面這個記錄,說明是使用了dfsUsed快取值,啟動過程非常快.
2016-01-13 09:13:20,639 INFO [Thread-68] (FsVolumeList.java:402) - Scanning block pool BP-1543590671-xx.xx.xx.xx-1449897014835 on volume /home/data/data/hadoop/dfs/data/data9/current...
2016-01-13 09:13:20,639 INFO [Thread-69] (FsVolumeList.java:402) - Scanning block pool BP-1543590671-xx.xx.xx.xx-1449897014835 on volume /home/data/data/hadoop/dfs/data/data10/current...
2016-01-13 09:13:20,639 INFO [Thread-71] (FsVolumeList.java:402) - Scanning block pool BP-1543590671-xx.xx.xx.xx-1449897014835 on volume /home/data/data/hadoop/dfs/data/data12/current...
2016-01-13 09:13:20,639 INFO [Thread-70] (FsVolumeList.java:402) - Scanning block pool BP-1543590671-xx.xx.xx.xx-1449897014835 on volume /home/data/data/hadoop/dfs/data/data11/current...
2016-01-13 09:13:20,822 INFO [Thread-62] (BlockPoolSlice.java:221) - Cached dfsUsed found for /home/data/data/hadoop/dfs/data/data3/current/BP-1543590671-xx.xx.xx.xx-1449897014835/current: 40487047190
2016-01-13 09:13:20,825 INFO [Thread-63] (BlockPoolSlice.java:221) - Cached dfsUsed found for /home/data/data/hadoop/dfs/data/data4/current/BP-1543590671-xx.xx.xx.xx-1449897014835/current: 39336478590
2016-01-13 09:13:20,825 INFO [Thread-62] (FsVolumeList.java:407) - Time taken to scan block pool BP-1543590671-xx.xx.xx.xx-1449897014835 on /home/data/data/hadoop/dfs/data/data3/current: 187ms
2016-01-13 09:13:20,826 INFO [Thread-63] (FsVolumeList.java:407) - Time taken to scan block pool BP-1543590671-xx.xx.xx.xx-1449897014835 on /home/data/data/hadoop/dfs/data/data4/current: 189ms此新增功能我已提交開源社群,編號HDFS-9624.