-Zero-Shot-- Super-Resolution using Deep Internal Learning
阿新 • • 發佈:2019-01-28
“Zero-Shot”: Super-Resolution using Deep Internal Learning
簡介
以往的深度學習超分辨方法是基於大量的LR-HR資料來訓練一個網路的引數,其中生成LR的方法是用諸如MATLAB的imresize函式,這種LR影象被稱為 ideal 的。然而實際情況中要超分辨的LR影象往往有是 non-ideal 的:摻雜噪聲、未知的降取樣核、有aliasing現象等等,如此很難用傳統超分辨跑出很好的HR。另外,有一些影象內有的特殊結構不是通過大量資料就能學到的。
作者提出的“Zero-Shot” SR (ZSSR)致力於尋找單張影象內在的資訊(exploit the internal recurrence of information within a single image
)。在超分辨一張圖LR時,對該圖再度降取樣,學習二者之間的超分辨引數,再用於LR的超分辨。作者把傳統的那些深度學習超分辨方法叫做 SotA supervised CNNs。雖然ZSSR是在test的同時訓練的,但是因為網路結構小,因此和SotA supervised CNNs相比test的時間相差不多。
ZSSR的理論基礎是:自然影象有很強的的internal data repetition。單張圖片內的patch的internal entropy要比自然影象集合的patch的external entropy小很多(尚不明白entropy代表什麼)。
網路
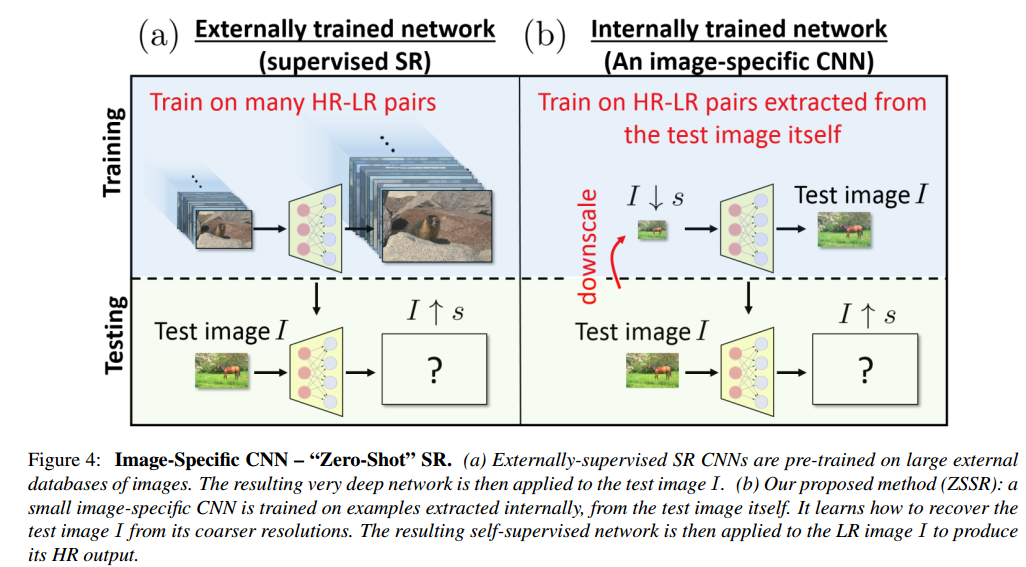
- 如上圖。LR影象先再度降取樣s倍,成為。網路學習到的對映,然後把網路用於的升取樣,得到HR影象。
- 為了擴充訓練集,我們把降取樣,得到很多小版本的(),他們都叫做“HR fathers”,再次降取樣後得到“LR sons”。另外,還有對LR-HR進行旋轉(0◦; 90◦; 180◦; 270◦),及其水平和垂直的映象對映。
- 為了魯棒性,這段沒看懂。

網路結構
- 作者的網路結構很簡單:8個64通道的隱藏層,用ReLU啟用,輸入首先被插值到輸出的大小,輸入和輸出用skip connection連線,損失用損失,ADAM優化器,0.001學習率,會逐漸衰減。其他優化方法不提了。最後還是用了geometric self-ensemble方法,不過有所改動,沒看太明白。
Adapting to the Test Image
- 生成LR時,如果知道降取樣核,就可以用上,如果不知道,就用“Nonparametric Blind Super-Resolution”中的方法估計核。另外,訓練時最好在LR中新增高斯噪聲(0均值,小標準差)
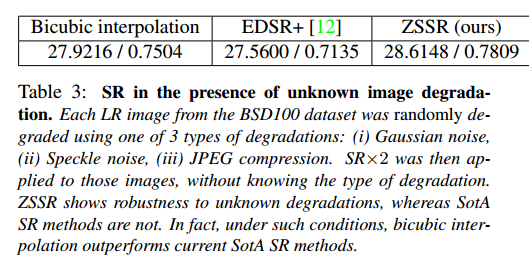
實驗
- 最後,實驗表明,ideal情況時,ZSSR與SotA supervised CNNs尚可匹敵。non-ideal時,直接完爆。