
TensorFlow入門(六) 雙端 LSTM 實現序列標註(分詞)
歡迎轉載,但請務必註明原文出處及作者資訊。
@author: huangyongye
@creat_date: 2017-04-19
前言
本例子主要介紹如何使用 TensorFlow 來一步一步構建雙端 LSTM 網路(聽名字就感覺好膩害的樣子),並完成序列標註的問題。先宣告一下,本文中採用的方法主要參考了【中文分詞系列】 4. 基於雙向LSTM的seq2seq字標註這篇文章。該文章用 keras 框架來實現的雙端 LSTM,在本例中,實現思路和該文章基本上一樣,但是用 TensorFlow 來實現的。這個例子中涉及到的知識點比較多,包括 word embedding, Viterbi 演算法等,但是就算你對這些不是非常瞭解,依然能夠很好地理解本文。
本例的主要目的是講清楚基於 TensorFlow 如何來實現雙端 LSTM。通過本例的學習,你可以知道 Bi-directional LSTM 是怎麼樣一步一步計算的。
由於這個例子的程式碼比較長,本文主要就網路結構部分進行分析。其餘的比如資料處理這些在這裡只是簡單介紹,想理解具體內容的歡迎移步 鄙人 GitHub,程式碼,資料 什麼的全都放上去了。
如果你還不知道什麼是 LSTM 的話,建議先看一下 (譯)理解 LSTM 網路 (Understanding LSTM Networks by colah) 這篇文章。在理解 LSTM 的基礎上,再去理解 雙端 LSTM (Bi-directional LSTM)還是非常容易的。關於雙端 LSTM 的原理,這裡不做詳細解釋,下面這張圖顯示了 雙端 RNN 的結構。
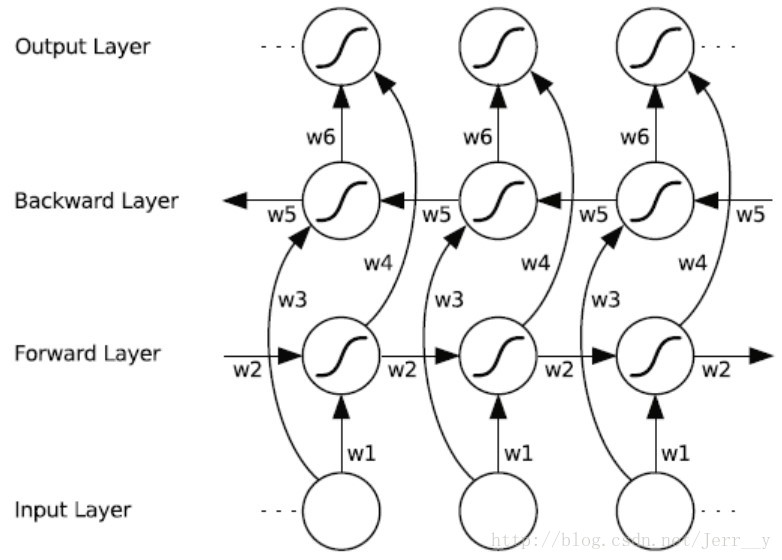
fig.1 Bi-RNN 按時間展開的結構
Bi-LSTM大致的思路是這樣的,看圖中最下方的輸入層,假設一個樣本(句子)有10個 timestep (字)的輸入
- 對於前向 fw_cell ,樣本按照
x1,x2,...,x10 的順序輸入 cell 中,得到第一組狀態輸出 {h1,h2,...,h10 } ; - 對於反向 bw_cell ,樣本按照
x10,x9,...,x1 的反序輸入 cell 中,得到第二組狀態輸出 {h10,h9,...,h1 }; - 得到的兩組狀態輸出的每個元素是一個長度為 hidden_size 的向量(一般情況下,
h1 和h1 長度相等)。現在按照下面的形式把兩組狀態變數拼起來{[h1 ,h1 ], [h2 ,h2 ], … , [h10 ,h10 ]}。 - 最後對於每個 timestep 的輸入
xt , 都得到一個長度為 2*hidden_size 的狀態輸出Ht = [ht ,ht ]。然後呢,後面處理方式和單向 LSTM 一樣。
1. 資料說明
下面大概說一下資料處理,但是這不影響對模型的理解,可以直接跳到
1.1 原始語料在txt檔案中,長的下面這個樣子
人/b 們/e 常/s 說/s 生/b 活/e 是/s 一/s 部/s 教/b 科/m 書/e ,/s 而/s 血/s 與/s 火/s 的/s 戰/b 爭/e 更/s 是/s 不/b 可/m 多/m 得/e 的/s 教/b 科/m 書/e ,/s 她/s 確/b 實/e 是/s 名/b 副/m 其/m 實/e 的/s ‘/s 我/s 的/s 大/b 學/e ’/s 。/s 心/s 靜/s 漸/s 知/s 春/s 似/s 海/s ,/s 花/s 深/s 每/s 覺/s 影/s
1.2 根據標點符號進行切分,下面是一個 sample
人/b 們/e 常/s 說/s 生/b 活/e 是/s 一/s 部/s 教/b 科/m 書/e
1.3 把每個字和對應的tag轉為一一對應的 id
在轉為 id 之前,跟下表這樣。這樣的東西我們沒辦法塞到模型裡去訓練呀,必須先轉為數值才行呀。
| words | tags | sentence_len |
|---|---|---|
| [人, 們, 常, 說, 生, 活, 是, 一, 部, 教, 科, 書] | [b, e, s, s, b, e, s, s, s, b, m, e] | 12 |
| [而, 血, 與, 火, 的, 戰, 爭, 更, 是, 不, 可, 多, 得, 的, 教, …] | [s, s, s, s, s, b, e, s, s, b, m, m, e, s, b, …] | 17 |
因為一般情況下,我們訓練網路的時候都喜歡把輸入 padding 到固定的長度,這樣子計算更快。可是切分之後的句子長短不一,因此我們取 32 作為句子長度,超過 32 個字的將把多餘的字去掉,少於 32 個字的將用特殊字元填充。處理之前,每個字 word <-> tag,處理完後變成 X <-> y。長度不足 32 的補0填充。(下面編碼問題顯示就這樣,湊合著看吧。)
words: [u'\u4eba' u'\u4eec' u'\u5e38' u'\u8bf4' u'\u751f' u'\u6d3b' u'\u662f' u'\u4e00' u'\u90e8' u'\u6559' u'\u79d1' u'\u4e66']
tags: [u'b' u'e' u's' u's' u'b' u'e' u's' u's' u's' u'b' u'm' u'e']
X: [ 8 43 320 88 36 198 7 2 41 163 124 245 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
y: [2 4 1 1 2 4 1 1 1 2 3 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
總之,上面這些都不重要,重要的是我們模型的輸入 shape 是下面這樣子的。第一維表示樣本個數,第二維是 timestep_size。其實還有個第三維大小是 1, 因為每個時刻就只輸入一個字,確切地說就是一個數字,因為我們已經把它轉為數值 id 的形式了。
X_train.shape=(205780, 32), y_train.shape=(205780, 32);
X_valid.shape=(51446, 32), y_valid.shape=(51446, 32);
X_test.shape=(64307, 32), y_test.shape=(64307, 32)
2. Bi-directional lstm 模型
2.1 模型分析
import tensorflow as tf
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
from tensorflow.contrib import rnn
import numpy as np
'''
For Chinese word segmentation.
'''
# ##################### config ######################
decay = 0.85
max_epoch = 5
max_max_epoch = 10
timestep_size = max_len = 32 # 句子長度
vocab_size = 5159 # 樣本中不同字的個數,根據處理資料的時候得到
input_size = embedding_size = 64 # 字向量長度
class_num = 5
hidden_size = 128 # 隱含層節點數
layer_num = 2 # bi-lstm 層數
max_grad_norm = 5.0 # 最大梯度(超過此值的梯度將被裁剪)
lr = tf.placeholder(tf.float32)
keep_prob = tf.placeholder(tf.float32)
batch_size = tf.placeholder(tf.int32) # 注意型別必須為 tf.int32
model_save_path = 'ckpt/bi-lstm.ckpt' # 模型儲存位置
def weight_variable(shape):
"""Create a weight variable with appropriate initialization."""
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
"""Create a bias variable with appropriate initialization."""
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
X_inputs = tf.placeholder(tf.int32, [None, timestep_size], name='X_input')
y_inputs = tf.placeholder(tf.int32, [None, timestep_size], name='y_input') 如果你看過我上一篇文章 TensorFlow入門(五)多層 LSTM 通俗易懂版 的話,應該已經知道 LSTM 是怎麼實現的了(如果不懂的話請先把上篇文章看懂再繼續往下看了)。
下面重點終於來啦!!!
在這裡,為了那些不懂 embedding 的朋友能夠看懂下面的程式碼,我必須囉嗦幾句說明一下什麼是 word embedding。這是自然語言處理的一個大殺器,我們平時口口聲聲說的詞向量就是這東西。在這個例子中我們指的是字向量,原理完全是一樣的。剛才我們已經說過,每個 timestep 輸入的是一個字對應的 id, 也就是一個整數。經過 embedding 操作之後,就變成了一個長度為 embedding_size(我們可以自己指定字向量的長度) 的實數向量。具體它是怎麼做的呢?如果你是做自然語言處理的應該已經知道了,如果你不是做自然語言處理的呢,那就不用管了。反正,真正輸入到 LSTMCell 中的資料 shape 長這樣 [ batchsize, timestep_size, input_size ]。 input_size 是每個 timestep 輸入樣本的特徵維度,如上個例子中就是MNIST字元每行的28個點,那麼就應該 input_size=28。把你要處理的資料整理成這樣的 shape 就可以了,管它什麼 embedding。
def bi_lstm(X_inputs):
"""build the bi-LSTMs network. Return the y_pred"""
# ** 0.char embedding,請自行理解 embedding 的原理!!做 NLP 的朋友必須理解這個
embedding = tf.get_variable("embedding", [vocab_size, embedding_size], dtype=tf.float32)
# X_inputs.shape = [batchsize, timestep_size] -> inputs.shape = [batchsize, timestep_size, embedding_size]
inputs = tf.nn.embedding_lookup(embedding, X_inputs)
# ** 1.LSTM 層
lstm_fw_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0, state_is_tuple=True)
lstm_bw_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0, state_is_tuple=True)
# ** 2.dropout
lstm_fw_cell = rnn.DropoutWrapper(cell=lstm_fw_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)
lstm_bw_cell = rnn.DropoutWrapper(cell=lstm_bw_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)
# ** 3.多層 LSTM
cell_fw = rnn.MultiRNNCell([lstm_fw_cell]*layer_num, state_is_tuple=True)
cell_bw = rnn.MultiRNNCell([lstm_bw_cell]*layer_num, state_is_tuple=True)
# ** 4.初始狀態
initial_state_fw = cell_fw.zero_state(batch_size, tf.float32)
initial_state_bw = cell_bw.zero_state(batch_size, tf.float32)
# 下面兩部分是等價的
# **************************************************************
# ** 把 inputs 處理成 rnn.static_bidirectional_rnn 的要求形式
# ** 文件說明
# inputs: A length T list of inputs, each a tensor of shape
# [batch_size, input_size], or a nested tuple of such elements.
# *************************************************************
# Unstack to get a list of 'n_steps' tensors of shape (batch_size, n_input)
# inputs.shape = [batchsize, timestep_size, embedding_size] -> timestep_size tensor, each_tensor.shape = [batchsize, embedding_size]
# inputs = tf.unstack(inputs, timestep_size, 1)
# ** 5.bi-lstm 計算(tf封裝) 一般採用下面 static_bidirectional_rnn 函式呼叫。
# 但是為了理解計算的細節,所以把後面的這段程式碼進行展開自己實現了一遍。
# try:
# outputs, _, _ = rnn.static_bidirectional_rnn(cell_fw, cell_bw, inputs,
# initial_state_fw = initial_state_fw, initial_state_bw = initial_state_bw, dtype=tf.float32)
# except Exception: # Old TensorFlow version only returns outputs not states
# outputs = rnn.static_bidirectional_rnn(cell_fw, cell_bw, inputs,
# initial_state_fw = initial_state_fw, initial_state_bw = initial_state_bw, dtype=tf.float32)
# output = tf.reshape(tf.concat(outputs, 1), [-1, hidden_size * 2])
# ***********************************************************
# ***********************************************************
# ** 5. bi-lstm 計算(展開)
with tf.variable_scope('bidirectional_rnn'):
# *** 下面,兩個網路是分別計算 output 和 state
# Forward direction
outputs_fw = list()
state_fw = initial_state_fw
with tf.variable_scope('fw'):
for timestep in range(timestep_size):
if timestep > 0:
tf.get_variable_scope().reuse_variables()
(output_fw, state_fw) = cell_fw(inputs[:, timestep, :], state_fw)
outputs_fw.append(output_fw)
# backward direction
outputs_bw = list()
state_bw = initial_state_bw
with tf.variable_scope('bw') as bw_scope:
inputs = tf.reverse(inputs, [1])
for timestep in range(timestep_size):
if timestep > 0:
tf.get_variable_scope().reuse_variables()
(output_bw, state_bw) = cell_bw(inputs[:, timestep, :], state_bw)
outputs_bw.append(output_bw)
# *** 然後把 output_bw 在 timestep 維度進行翻轉
# outputs_bw.shape = [timestep_size, batch_size, hidden_size]
outputs_bw = tf.reverse(outputs_bw, [0])
# 把兩個oupputs 拼成 [timestep_size, batch_size, hidden_size*2]
output = tf.concat([outputs_fw, outputs_bw], 2)
# output.shape 必須和 y_input.shape=[batch_size,timestep_size] 對齊
output = tf.transpose(output, perm=[1,0,2])
output = tf.reshape(output, [-1, hidden_size*2])
# ***********************************************************
softmax_w = weight_variable([hidden_size * 2, class_num])
softmax_b = bias_variable([class_num])
logits = tf.matmul(output, softmax_w) + softmax_b
return logits
y_pred = bi_lstm(X_inputs)
# adding extra statistics to monitor
# y_inputs.shape = [batch_size, timestep_size]
correct_prediction = tf.equal(tf.cast(tf.argmax(y_pred, 1), tf.int32), tf.reshape(y_inputs, [-1]))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels = tf.reshape(y_inputs, [-1]), logits = y_pred))
# ***** 優化求解 *******
# 獲取模型的所有引數
tvars = tf.trainable_variables()
# 獲取損失函式對於每個引數的梯度
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), max_grad_norm)
# 優化器
optimizer = tf.train.AdamOptimizer(learning_rate=lr)
# 梯度下降計算
train_op = optimizer.apply_gradients( zip(grads, tvars),
global_step=tf.contrib.framework.get_or_create_global_step())
print 'Finished creating the bi-lstm model.'過多的解釋也沒有了,都在上面的程式碼中!但還是得說一聲,在這個雙端 LSTM 模型中,重點要理解兩點:
1. 兩個 LSTM (cell_fw, cell_bw)的計算是各自獨立的,只是最後輸出的時候把二者的狀態向量結合起來。
2. 本例中每個 timestep 都有結果輸出,而上篇的分類問題中我們只拿最後一個 h_state 來計算最後的輸出(注意這不是 Bi-LSTM 和 單向 LSTM 的區別, 單向的也可以每個 timestep 都輸出)。注意本例中的 y_input 也對應的每個 timestep 對應一個 tag(id)。
2.2 實驗結果
看一下結果吧,不放結果都是耍流氓 :
(1) 先是分類準確率
**Test 64307, acc=0.948665, cost=0.139884
(2)實際分詞
人們 / 思考 / 問題 / 往往 / 不是 / 從 / 零開始 / 的 / 。 / 就 / 好 / 像 / 你 / 現在 / 閱讀 / 這 / 篇 / 文章 / 一樣 / , / 你 / 對 / 每個 / 詞 / 的 / 理解 / 都會 / 依賴 / 於 / 你 / 前面 / 看到 / 的 / 一些 / 詞 / , / / 而 / 不是 / 把 / 你 / 前面 / 看 / 的 / 內容 / 全部 / 拋棄 / 了 / , / 忘記 / 了 / , / 再去 / 理解 / 這個 / 單詞 / 。 / 也 / 就 / 是 / 說 / , / 人們 / 的 / 思維 / 總是 / 會 / 有 / 延續 / 性 / 的 / 。 /
結論:本例子使用 Bi-directional LSTM 來完成了序列標註的問題。本例中展示的是一個分詞任務,但是還有其他的序列標註問題都是可以通過這樣一個架構來實現的,比如 POS(詞性標註)、NER(命名實體識別)等。在本例中,單從分類準確率來看的話差不多到 95% 了,還是可以的。可是最後的分詞效果還不是非常好,但也勉強能達到實用的水平,而且模型也只是粗略地跑了一遍,還沒有進行任何的引數優化。最後的維特比譯碼中轉移概率只是簡單的用了等概分佈,如果能根據訓練語料以統計結果作為概率分佈的話相信結果能夠進一步提高。