
基於雙端堆實現的優先順序佇列(1):原理
阿新 • • 發佈:2018-12-27
前言
眾所周知,stl中的優先順序佇列是基於最大堆實現的,能夠在對數時間內插入元素和獲取優先順序最高的元素,但如果要求在對數時間內還能獲取優先順序最低的元素,而不只是獲取優先順序最高的元素,該怎麼實現呢?可以用最大堆-最小堆或雙端堆資料結構來實現,最大堆-最小堆和雙端堆都是支援雙端優先佇列的插入、刪除最小元素和最大元素等操作的堆,在這些操作上,時間複雜度都是對數時間,但是雙端堆的操作比最大堆-最小堆的相應操作還要快一個常數因子,而且演算法更加簡單,因此本文講述選擇使用雙端堆實現優先順序佇列的原理。
定義與性質 雙端堆是一顆完全二叉樹,該完全二叉樹要麼為空,要麼滿足以下性質:
(1)根結點不包含元素
(2)左子樹是一個最小堆
(3)右子樹是一個最大堆
(4)如果右子樹不為空,則令i是其中任一結點,j是i在右子樹中的對應結點,如果i在右子樹中的對應結點不存在,則j為i的父結點在右子樹中的對應結點, 對於結點i和j,i的關鍵字值小於等於j的關鍵字值。
從以上性質可以推出:對於左子結中的任一結點i,設j為i的對稱結點,則由最小元素到i,i到j,j到最大元素的路徑上元素是非遞減有序的。在雙端堆上的操作演算法核心就是為了保證這樣的單向路徑上元素必須是非遞減有序的。
例如下圖所示,就是一個雙端堆
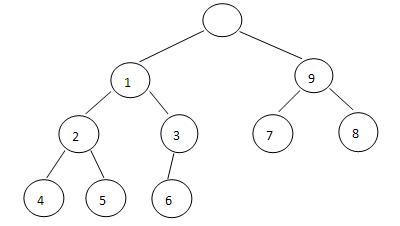
(2)刪除最小元素:首先在最小堆中執行一個向下回溯過程,這個過程執行的堆大小要比原來的堆小1,從最小元素結點開始,每次選取關鍵字值較小的孩子結點,並用其值更新父結點值,直到底部沒有孩子結點,執行的結果是在底部某葉子結點i處形成一個空洞(形象說法,這個空洞需要後續操作來調整填補,下同),i的對稱結點j在最大堆中,設最末元素結點為e,如果KeyValue(e)>KeyValue(j),則設定KeyValue(i)=KeyValue(j),並執行在最大堆中位置j處插入值KeyValue(e)的操作;否則執行在最小堆中位置i處插入值KeyValue(e)的操作。
(3)刪除最大元素:這個操作比刪除最小元素要麻煩一點,和刪除最小元素類似,先執行一個向下回溯過程得到空洞結點i,其對稱結點為j,為了保證能滿足雙端堆的性質,需要考慮以下幾種情況:a)j只存在一個孩子,如下圖第1個所示。 b)j存在兩個孩子,如下圖第2個所示。 c)j不存在孩子,但存在左兄弟(可能存在孩子),如下圖第3個所示。 d)j不存在孩子,但存在右兄弟,如下圖最後一個所示。

(4)構造堆:給定一個元素大小為N的序列S,在這個序列空間上構造堆,一般有兩種實現方法,一是迴圈N-1次,每次插入元素S[i],也就是自頂向下構建堆,時間複雜度為O(NlgN)。另一種是從最後一個內部結點N/2左右開始,執行調整堆操作,直到第一個元素,也就是自底向上構建堆,時間複雜度為O(N)。
(5)最大堆(最小堆)插入:這是一個向上回溯過程,和單個最大堆(最小堆)操作是一樣的,從底部某處開始,比較待插元素和結點關鍵字值大小,直到前者不大於(不小於)後者時或碰到最大堆(最小堆)頂部為止,這時就找到了插入位置,將待插元素放到這個位置即可。
設雙端堆元素個數為N,由於完全二叉樹高度為O(lgN),則插入元素操作時間複雜度為O(lgN),刪除最小元素和最大元素為不超過2O(lgN),實現這些操作最重要的一點就是要保證性質4,只有當性質4滿足時,雙端堆才有意義,才能保證獲取最大元素和最小元素操作的對數時間,具體的實現詳見下文。 posted on 2011-10-03 17:53
眾所周知,stl中的優先順序佇列是基於最大堆實現的,能夠在對數時間內插入元素和獲取優先順序最高的元素,但如果要求在對數時間內還能獲取優先順序最低的元素,而不只是獲取優先順序最高的元素,該怎麼實現呢?可以用最大堆-最小堆或雙端堆資料結構來實現,最大堆-最小堆和雙端堆都是支援雙端優先佇列的插入、刪除最小元素和最大元素等操作的堆,在這些操作上,時間複雜度都是對數時間,但是雙端堆的操作比最大堆-最小堆的相應操作還要快一個常數因子,而且演算法更加簡單,因此本文講述選擇使用雙端堆實現優先順序佇列的原理。
定義與性質 雙端堆是一顆完全二叉樹,該完全二叉樹要麼為空,要麼滿足以下性質:
(1)根結點不包含元素
(2)左子樹是一個最小堆
(3)右子樹是一個最大堆
(4)如果右子樹不為空,則令i是其中任一結點,j是i在右子樹中的對應結點,如果i在右子樹中的對應結點不存在,則j為i的父結點在右子樹中的對應結點, 對於結點i和j,i的關鍵字值小於等於j的關鍵字值。
從以上性質可以推出:對於左子結中的任一結點i,設j為i的對稱結點,則由最小元素到i,i到j,j到最大元素的路徑上元素是非遞減有序的。在雙端堆上的操作演算法核心就是為了保證這樣的單向路徑上元素必須是非遞減有序的。
例如下圖所示,就是一個雙端堆
(2)刪除最小元素:首先在最小堆中執行一個向下回溯過程,這個過程執行的堆大小要比原來的堆小1,從最小元素結點開始,每次選取關鍵字值較小的孩子結點,並用其值更新父結點值,直到底部沒有孩子結點,執行的結果是在底部某葉子結點i處形成一個空洞(形象說法,這個空洞需要後續操作來調整填補,下同),i的對稱結點j在最大堆中,設最末元素結點為e,如果KeyValue(e)>KeyValue(j),則設定KeyValue(i)=KeyValue(j),並執行在最大堆中位置j處插入值KeyValue(e)的操作;否則執行在最小堆中位置i處插入值KeyValue(e)的操作。
(3)刪除最大元素:這個操作比刪除最小元素要麻煩一點,和刪除最小元素類似,先執行一個向下回溯過程得到空洞結點i,其對稱結點為j,為了保證能滿足雙端堆的性質,需要考慮以下幾種情況:a)j只存在一個孩子,如下圖第1個所示。 b)j存在兩個孩子,如下圖第2個所示。 c)j不存在孩子,但存在左兄弟(可能存在孩子),如下圖第3個所示。 d)j不存在孩子,但存在右兄弟,如下圖最後一個所示。
(4)構造堆:給定一個元素大小為N的序列S,在這個序列空間上構造堆,一般有兩種實現方法,一是迴圈N-1次,每次插入元素S[i],也就是自頂向下構建堆,時間複雜度為O(NlgN)。另一種是從最後一個內部結點N/2左右開始,執行調整堆操作,直到第一個元素,也就是自底向上構建堆,時間複雜度為O(N)。
(5)最大堆(最小堆)插入:這是一個向上回溯過程,和單個最大堆(最小堆)操作是一樣的,從底部某處開始,比較待插元素和結點關鍵字值大小,直到前者不大於(不小於)後者時或碰到最大堆(最小堆)頂部為止,這時就找到了插入位置,將待插元素放到這個位置即可。
設雙端堆元素個數為N,由於完全二叉樹高度為O(lgN),則插入元素操作時間複雜度為O(lgN),刪除最小元素和最大元素為不超過2O(lgN),實現這些操作最重要的一點就是要保證性質4,只有當性質4滿足時,雙端堆才有意義,才能保證獲取最大元素和最小元素操作的對數時間,具體的實現詳見下文。 posted on 2011-10-03 17:53