
Spark效能調優之廣播大變數
本篇blog講述在實際spark專案中可能需要注意的一個性能調優的一個點,就是broadcast大變數。
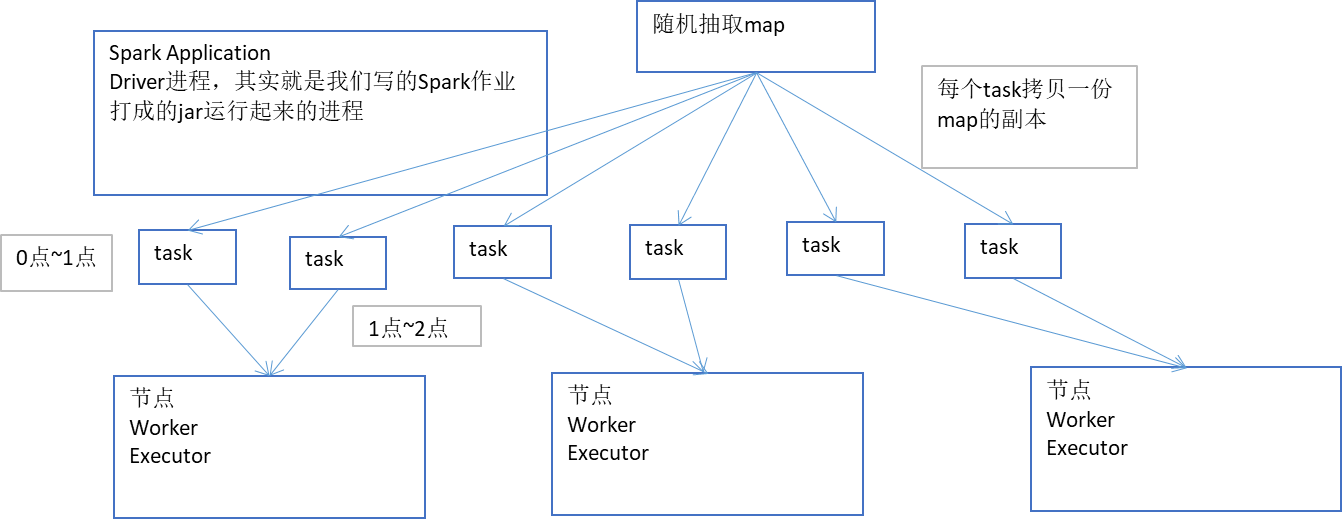
預設的在spark作業中,task執行的運算元中,使用了外部的變數,每個task都會獲取一份變數的副本,有什麼缺點呢?<br>map,本身是不小,存放資料的一個單位是Entry,還有可能會用連結串列的格式的來存放Entry鏈條。所以map是比較消耗記憶體的資料格式。比如,map是1M。總共,你前面調優都調的特好,資源給的到位,配合著資源,並行度調節的絕對到位,1000個task。大量task的確都在並行執行。
這些task裡面都用到了佔用1M記憶體的map,那麼首先,map會拷貝1000份副本,通過網路傳輸到各個task中去,給task使用。總計有1G的資料,會通過網路傳輸。網路傳輸的開銷,也許就會消耗掉你的spark作業執行的總時間的一小部分。map副本,傳輸到了各個task上之後,是要佔用記憶體的。1個map的確不大,1M;1000個map分佈在你的叢集中,一下子就耗費掉1G的記憶體。
在什麼情況下,會出現效能上的惡劣的影響呢?
不必要的記憶體的消耗和佔用,就導致了,你在進行RDD持久化到記憶體,也許就沒法完全在記憶體中放下;就只能寫入磁碟,最後導致後續的操作在磁碟IO上消耗效能;
你的task在建立物件的時候,也許會發現堆記憶體放不下所有物件,也許就會導致頻繁的垃圾回收器的回收,GC。GC的時候,一定是會導致工作執行緒停止,也就是導致Spark暫停工作那麼一點時間。頻繁GC的話,對Spark作業的執行的速度會有相當可觀的影響。
調優方案:廣播大變數
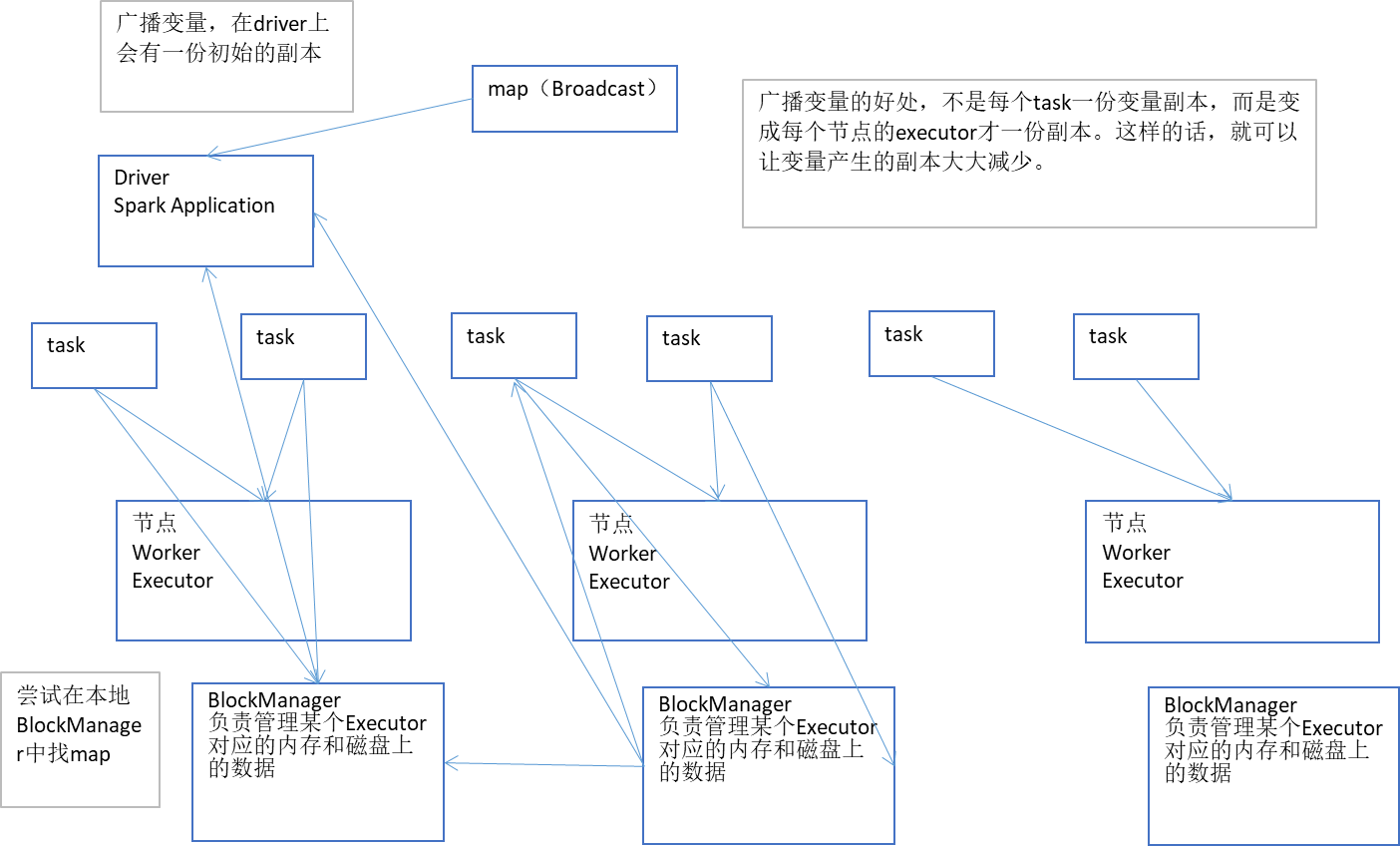
廣播變數,初始的時候,就在Drvier上有一份副本。
task在執行的時候,想要使用廣播變數中的資料,此時首先會在自己本地的Executor對應的BlockManager中,嘗試獲取變數副本;如果本地沒有,那麼就從Driver遠端拉取變數副本,並儲存在本地的BlockManager中;此後這個executor上的task,都會直接使用本地的BlockManager中的副本。
executor的BlockManager除了從driver上拉取,也可能從其他節點的BlockManager上拉取變數副本,舉例越近越好。