
《Pelee: A Real-Time Object Detection System on Mobile Devices》解讀
已有的在移動裝置上執行的深度學習模型例如 MobileNet、 ShuffleNet 等都嚴重依賴於在深度上可分離的卷積運算,而缺乏有效的實現。在本文中,來自加拿大西安大略大學的研究者提出了稱為 PeleeNet 的有效架構,它沒有使用傳統的卷積來實現。PeleeNet 實現了比目前最先進的 MobileNet 更高的影象分類準確率,並降低了計算成本。研究者進一步開發了實時目標檢測系統 Pelee,以更低的成本超越了 YOLOv2 的目標檢測效能,並能流暢地在 iPhone6s、iPhone8 上執行。
在具有嚴格的記憶體和計算預算的條件下執行高質量的 CNN 模型變得越來越吸引人。近年來人們已經提出了很多創新的網路,例如 MobileNets (Howard et al.(2017))、ShuffleNet (Zhang et al.(2017)),以及 ShuffleNet (Zhang et al.(2017))。然而,這些架構嚴重依賴於在深度上可分離的卷積運算 (Szegedy 等 (2015)),而這些卷積運算缺乏高效的實現。同時,將高效模型和快速目標檢測結合起來的研究也很少 (Huang 等 (2016b))。本研究嘗試探索可以用於影象分類和目標檢測任務的高效 CNN 結構。本文的主要貢獻如下:
研究者提出了 DenseNet (Huang et al. (2016a)) 的一個變體,它被稱作 PeleeNet,專門用於移動裝置。PeleeNet 遵循 DenseNet 的創新連線模式和一些關鍵設計原則。它也被設計來滿足嚴格的記憶體和計算預算。在 Stanford Dogs (Khosla et al. (2011)) 資料集上的實驗結果表明:PeleeNet 的準確率要比 DenseNet 的原始結構高 5.05%,比 MobileNet (Howard et al. (2017)) 高 6.53%。PeleeNet 在 ImageNet ILSVRC 2012 (Deng et al. (2009)) 上也有極具競爭力的結果。PeleeNet 的 top-1 準確率要比 MobileNet 高 0.6%。需要指出的是,PeleeNet 的模型大小是 MobileNet 的 66%。PeleeNet 的一些關鍵特點如下:
兩路稠密層:受 GoogLeNet (Szegedy et al. (2015)) 的兩路稠密層的激發,研究者使用了一個兩路密集層來得到不同尺度的感受野。其中一路使用一個 3×3 的較小卷積核,它能夠較好地捕捉小尺度的目標。另一路使用兩個 3×3 的卷積核來學習大尺度目標的視覺特徵。該結構如圖 1.a 所示:

圖 1: 兩路密集層和 stem 塊的結構
瓶頸層通道的動態數量:另一個亮點就是瓶頸層通道數目會隨著輸入維度的變化而變化,以保證輸出通道的數目不會超過輸出通道。與原始的 DenseNet 結構相比,實驗表明這種方法在節省 28.5% 的計算資源的同時僅僅會對準確率有很小的影響。
沒有壓縮的轉換層:實驗表明,DenseNet 提出的壓縮因子會損壞特徵表達,PeleeNet 在轉換層中也維持了與輸入通道相同的輸出通道數目。
複合函式:為了提升實際的速度,採用後啟用的傳統智慧(Convolution - Batch Normalization (Ioffe & Szegedy (2015)) - Relu))作為我們的複合函式,而不是 DenseNet 中所用的預啟用。對於後啟用而言,所有的批正則化層可以在推理階段與卷積層相結合,這可以很好地加快速度。為了補償這種變化給準確率帶來的不良影響,研究者使用一個淺層的、較寬的網路結構。在最後一個密集塊之後還增加了一個 1×1 的卷積層,以得到更強的表徵能力。
研究者優化了單樣本多邊框檢測器(Single Shot MultiBox Detector,SSD)的網路結構,以加速並將其與 PeleeNet 相結合。該系統,也就是 Pelee,在 PASCAL VOC (Everingham et al. (2010)) 2007 資料集上達到了 76.4% 的準確率,在 COCO 資料集上達到了 22.4% 的準確率。在準確率、速度和模型大小方面,Pelee 系統都優於 YOLOv2 (Redmon & Farhadi (2016))。為了平衡速度和準確率所做的增強設定如下:
特徵圖選擇:以不同於原始 SSD 的方式構建目標檢測網路,原始 SSD 仔細地選擇了 5 個尺度的特徵圖 (19 x 19、10 x 10、5 x 5、3 x 3、1 x 1)。為了減少計算成本,沒有使用 38×38 的特徵圖。
殘差預測塊:遵循 Lee 等人提出的設計思想(2017),即:使特徵沿著特徵提取網路傳遞。對於每一個用於檢測的特徵圖,在實施預測之前構建了一個殘差 (He et al. (2016)) 塊(ResBlock)。ResBlock 的結構如圖 2 所示:
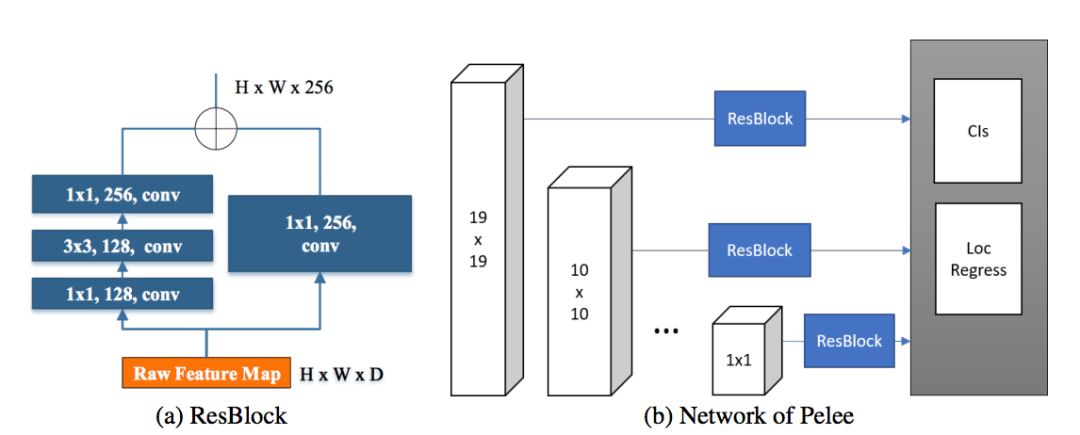
圖 2:殘差預測塊
用於預測的小型卷積核:殘差預測塊讓我們應用 1×1 的卷積核來預測類別分數和邊界框設定成為可能。實驗表明:使用 1×1 卷積核的模型的準確率和使用 3×3 的卷積核所達到的準確率幾乎相同。然而,1x1 的核將計算成本減少了 21.5%。
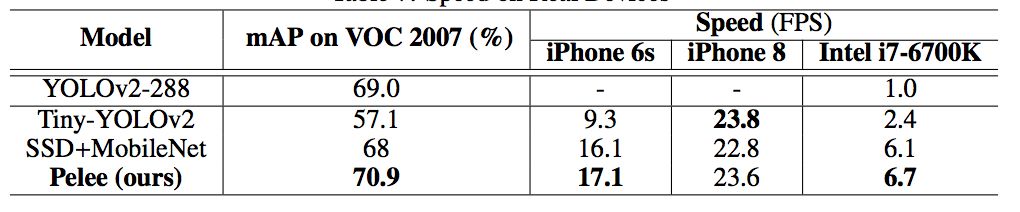
研究者在 iOS 上提供了 SSD 演算法的實現。他們已經成功地將 SSD 移植到了 iOS 上,並且提供了優化的程式碼實現。該系統在 iPhone 6s 上以 17.1 FPS 的速度執行,在 iPhone8 上以 23.6 FPS 的速度執行。在 iPhone 6s(2015 年釋出的手機)上的速度要比在 Intel [email protected] CPU 上的官方演算法實現還要快 2.6 倍。
相關推薦
《Pelee: A Real-Time Object Detection System on Mobile Devices》解讀
已有的在移動裝置上執行的深度學習模型例如 MobileNet、 ShuffleNet 等都嚴重依賴於在深度上可分離的卷積運算,而缺乏有效的實現。在本文中,來自加拿大西安大略大學的研究者提出了稱為 PeleeNet 的有效架構,它沒有使用傳統的卷積來實現。Pele
YOLO(You Only Look Once):Real-Time Object Detection
path nor bat pen 2-0 object network file with caffe-yolo:https://github.com/xingwangsfu/caffe-yolo YOLO in caffe Update 12-05-2016: Curre
論文閱讀筆記(六)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
采樣 分享 最終 產生 pre 運算 減少 att 我們 作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian SunSPPnet、Fast R-CNN等目標檢測算法已經大幅降低了目標檢測網絡的運行時間。可是盡管如此,仍然
【Faster RCNN】《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
NIPS-2015 NIPS,全稱神經資訊處理系統大會(Conference and Workshop on Neural Information Processing Systems),是一個關於機器學習和計算神經科學的國際會議。該會議固定在每年的12月舉行
《You Only Look Once: Unified, Real-Time Object Detection》論文筆記
1. 論文思想 YOLO(YOLO-v1)是最近幾年提出的目標檢測模型,它不同於傳統的目標檢測模型,將檢測問題轉換到一個迴歸問題,以空間分隔的邊界框和相關的類概率進行目標檢測。在一次前向運算中,一個單一的神經網路直接從完整的影象中預測邊界框和類概率。由於整個檢測管道是一個單一的網路,
論文閱讀筆記二十六:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
論文源址:https://arxiv.org/abs/1506.01497 tensorflow程式碼:https://github.com/endernewton/tf-faster-rcnn 摘要 目標檢測依賴於區域proposals演算法對目標的位置進
You Only Look Once: Unified, Real-Time Object Detection 論文閱讀
本文僅是對論文的解讀,供個人學習使用,如果有侵權的地方,還請聯絡我刪除博文 一、簡述 Yolo方法是一種目標檢測的方法。整個演算法的框架其實是一個迴歸的過程。現在簡單介紹一個下這個演算法的運轉流程。建立網路模型,輸入影象,然後其輸出結果記錄了影象中的Bounding Box(後
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Abstract SPPnet和Fast R-CNN雖然減少了演算法執行時間,但region proposal仍然是限制演算法速度的瓶頸。而Faster R-CNN提出了Region Proposal Network (RPN),該網路基於卷積特徵預測每個位置是否為物體以及
論文閱讀:You Only Look Once: Unified, Real-Time Object Detection
Preface 注:這篇今年 CVPR 2016 年的檢測文章 YOLO,我之前寫過這篇文章的解讀。但因為不小心在 Markdown 編輯器中編輯時刪除了。幸好同組的夥伴轉載了我的,我就直
【論文筆記】Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
寫在前面: 我看的paper大多為Computer Vision、Deep Learning相關的paper,現在基本也處於入門階段,一些理解可能不太正確。說到底,小女子才疏學淺,如果有錯
【筆記】Faster-R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
論文程式碼:重要:訓練檔案.prototxt說明:http://blog.csdn.net/Seven_year_Promise/article/details/60954553從RCNN到fast R
[論文學習]《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 》
faster R-CNN的主要貢獻 提出了 region proposal network(RPN),通過該網路我們可以將提取region proposal的過程也納入到深度學習的過程之中。這樣做既增加了Accuracy,由降低了耗時。之所以說增加Accura
【翻譯】Faster-R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
摘要 目前最先進的目標檢測網路需要先用區域建議演算法推測目標位置,像SPPnet[7]和Fast R-CNN[5]這些網路已經減少了檢測網路的執行時間,這時計算區域建議就成了瓶頸問題。本文中,我們介紹一種區域建議網路(Region Proposal Network, R
【目標檢測】[論文閱讀][yolo] You Only Look Once: Unified, Real-Time Object Detection
論文名稱《You Only Look Once: Unified, Real-Time Object Detection》 摘要 1、之前的目標檢測方法採用目標分類思想解決檢測問題,本文提出一個基於迴歸的框架,用於目標的定位及識別。 2、一個網路,一次預
深度學習論文翻譯解析(十三):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
論文標題:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 標題翻譯:基於區域提議(Region Proposal)網路的實時目標檢測 論文作者:Shaoqing Ren, K
YOLO前篇---Real-Time Grasp Detection Using Convolutional Neural Networks
論文地址:https://arxiv.org/abs/1412.3128 1. 摘要 比目前最好的方法提高了14%的精度,在GPU上能達到13FPS 2. 基於神經網路的抓取檢測 A 結構 使用AlexNet網路架構,5個卷積層+3個全連線層,卷積層
Train C4: Real-time pedestrian detection models——C4行人檢測演算法訓練過程
1.樣本的準備 樣本可以使用之前訓練的模型,通過OpenCV的imwrite截圖儲存然後再人工篩選,這個C4-Real-time-pedestrian-detection工程裡面我有實現。也可以自己寫一個程式,手動截圖。將正樣本都裁剪成只包
C4: Real-time pedestrian detection——C4實時行人檢測演算法
http://cs.nju.edu.cn/wujx/projects/C4/C4.htm Jianxin Wu實現的快速行人檢測方法。 Real-Time Human Detection Using Contour Cues: http://c2inet.sce.ntu.edu
faced: CPU Real Time face detection using Deep Learning
What is the problem?There are many scenarios where a single class object detection is needed. This means that we want to detect the location of all objects
Edge Computing Application: Real-Time Face Recognition Based on Cloudlet
A mobile-cloud architecture provides a practical platform for performing face recognition on a mobile device. Firstly, even though