
【圖形學與遊戲程式設計】開發筆記-基礎篇4:程式方面的補充知識
(本系列文章由pancy12138編寫,轉載請註明出處:http://blog.csdn.net/pancy12138)
上一次的教程已經講到了圖形管線的實現過程,由於之前大部分篇幅都在進行理論方面的描述,所以這篇文章主要是補充一些前面教程沒有提到過的程式方面的知識介紹,其中包括XNA庫,HLSL的語法,以及directx的圖形除錯。
首先我們先講解XNA庫,這個庫主要的作用就是在CPU中進行矩陣和向量的數學運算,也就是說這個庫其實就和C語言的<math.h>的用處差不多,但是不同的是這個庫裡的大部分運算函式都是基於矩陣和向量的,至於原因前面也提到過,因為整個圖形學的運算基礎就是矩陣和向量。注意我們之前的一篇教程已經用到了這個庫的一部分內容,比如根據程式執行的時間求那個幾何體的平移,旋轉,縮放矩陣就是靠這個庫來完成的,還有求投影矩陣也是靠這個庫完成的。在之後的求逆啊,做轉置啊,做乘法啊這些也少不了使用這個數學庫來完成。這一點相對於OpenGL來說是非常便利的,因為OpenGL是沒有這種類似的數學庫的,所以幾乎所有的數學運算都要自己寫,雖然其實也用不了多少時間但是總感覺自己寫的庫不是很放心,如果程式出了bug還得考慮考慮是不是哪個數學運算函式寫錯了啥的。以往的XNA庫是附加在directx庫裡的,現在已經歸屬於windowsAPI裡面了。所以大家其實只要在程式的開頭新增一個#include<directxmath.h>就可以了。接下來我們要講第二個非常重要的點,也就是XNA庫不僅僅負責在CPU上進行數學計算,他還得負責把計算結果每一幀告知GPU以讓GPU完成渲染工作。但是這裡有一個衝突,那就是記憶體對齊的問題,由於CPU上的記憶體對齊是比較複雜的,我記得是取結構體最大的變數的整數倍作為對齊標準。但是GPU上的記憶體一般是以一個4維向量作為一個對齊標準。也就是說同一種資料結構,很有可能在CPU上的大小和在GPU上的大小是不一樣的。因此XNA庫提供了兩種不同風格的資料結構以消除這種衝突,這也就是為什麼大家看到上一節的程式裡面,同樣是矩陣變數,有些地方使用的是XMMATRIX,有些則是XMFLOAT4X4,也就是說這個XMFLOAT4X4就屬於CPU上的變數,可以在結構體中以CPU變數的對齊方式和CPU上的其餘變數進行結合。而XMMATRIX則是屬於GPU的變數,一把只適用於像GPU傳送結果。這兩種變數是可以相互轉換的,轉換的方式如下:
XMFLOAT4X4 mat_need;
XMMATRIX rec_mat = XMLoadFloat4x4(mat_need);
XMStoreFloat4x4(&mat_need, rec_mat); ?當然,如果整個程式裡面只用其中的一種來進行設計,也有概率神馬異常都不會出現,但是..........這也就是說也有概率出現一些奇葩的錯誤啦。首先我們來看看只用GPU的型別來進行程式設計,也就是說傳引數以及設計結構體的時候都用類似於XMMATRIX啊,XMVECTOR啦這些GPU對齊的變數。這種情況下,出問題的一般就是CPU這邊,是否出問題則取決於作業系統和編譯器的版本,越新的作業系統和編譯器,就越容易出問題。出的問題呢,也很簡單,就是直接報記憶體錯誤然後程式崩潰........這就是我們玩遊戲的時候經常出現的所謂的“系統不相容”最大的原因。因為windows系統一般來說
?當然,如果整個程式裡面只用其中的一種來進行設計,也有概率神馬異常都不會出現,但是..........這也就是說也有概率出現一些奇葩的錯誤啦。首先我們來看看只用GPU的型別來進行程式設計,也就是說傳引數以及設計結構體的時候都用類似於XMMATRIX啊,XMVECTOR啦這些GPU對齊的變數。這種情況下,出問題的一般就是CPU這邊,是否出問題則取決於作業系統和編譯器的版本,越新的作業系統和編譯器,就越容易出問題。出的問題呢,也很簡單,就是直接報記憶體錯誤然後程式崩潰........這就是我們玩遊戲的時候經常出現的所謂的“系統不相容”最大的原因。因為windows系統一般來說以上就是XNA庫的一些補充知識,由於XNA庫大家以後幾乎每個程式都會用到所以這裡我把大部分可能出現的問題和bug先提前說一些,這樣大家以後寫的程式如果出現bug了也有除錯的方向。接下來我們來講HLSL的一些語法,HLSL的語法大部分和C語言是相同的,也就是說像迴圈啊,分支啊,變數定義啊這些都是沿用c語言的規則。我們這裡主要就講講他和C語言不一樣的地方,首先是外部變數,這個之前提到過,它屬於定義之後由CPU對齊進行賦值的一個變數,當然有人就有疑問了,如果CPU每一幀給幾千個執行緒都賦值這麼一個變數的話,會不會影響速度。這裡我們講一下,由於GPU是SIMD架構的,也就是單指令多資料流,CPU只會給GPU賦值一次變數,然後所有執行緒只是頂點資料不同,而這個外部變數都是共享的。所以並不會在很大程度上影響速度。其次為了方便外部變數的快速賦值,我們會把統一訪問頻率的變數歸為一類,比如每個幾何體都要變更的,每幀都要變更的等等,這樣就可以讓GPU進行資料的合併以加快更新速度:
cbuffer perframe
{
pancy_light_dir dir_light_need[10]; //方向光源
pancy_light_point point_light_need[5]; //點光源
pancy_light_spot spot_light_need[15]; //聚光燈光源
float3 position_view; //視點位置
int num_dir;
int num_point;
int num_spot;
};
cbuffer perobject
{
pancy_material material_need; //材質
float4x4 world_matrix; //世界變換
float4x4 normal_matrix; //法線變換
float4x4 final_matrix; //總變換
float4x4 shadowmap_matrix; //陰影貼圖變換
float4x4 ssao_matrix; //ssao變換
};如上圖所示,我們使用cbuffer標誌來對不同訪問頻率的外部便利呢進行歸類。接下來我們要說的一點不一樣的就是對於基礎變數(向量,矩陣)的訪問,這裡HLSL是可以非常靈活的訪問到所有打包基礎變數的內部資料的,比如color.rg就可以得到一個代表color向量的紅綠分量的二維的變數。通過這種方法我們可以輕易地對一個向量或者矩陣進行內部資料的更改或者呼叫。最後我們要提到的就是GPU的每個執行緒的運算速度以及整合度相比於CPU可以說是差之甚遠的,所以大家在寫程式的時候,能寫的簡練就寫得簡練,能不用迴圈就不用迴圈,能用內建函式解決的問題儘量用內建函式解決。這樣才能寫出最高效的程式,要知道你的程式複雜度多一點,所造成的影響就是幾千個執行緒在執行這個程式的時候都會變得很慢。像歸一化啦,求反射啦,求對數啦這些運算,儘量都用那些內建的函式來解決。這樣既寫的簡練,也能夠提升程式的執行速度。
最後我們來講一下directx的圖形除錯機制,這也是相比於OpenGL而言,directx的又一優勢所在(不得不說,微軟的大腿很粗........)。接下來我們來看對於上一片部落格的程式,我們怎麼才能夠分段進行除錯:
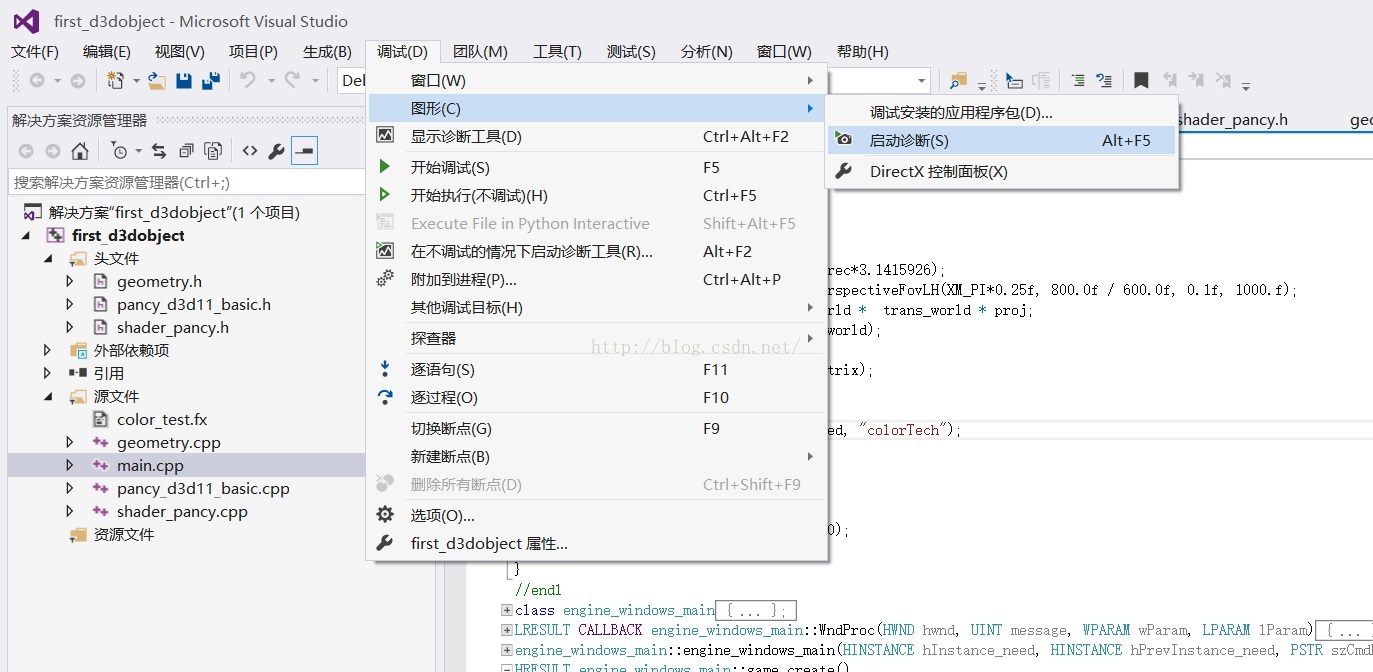
如上圖所示,在vs介面下,點選除錯->圖形->啟動診斷就可以進入圖形除錯介面:
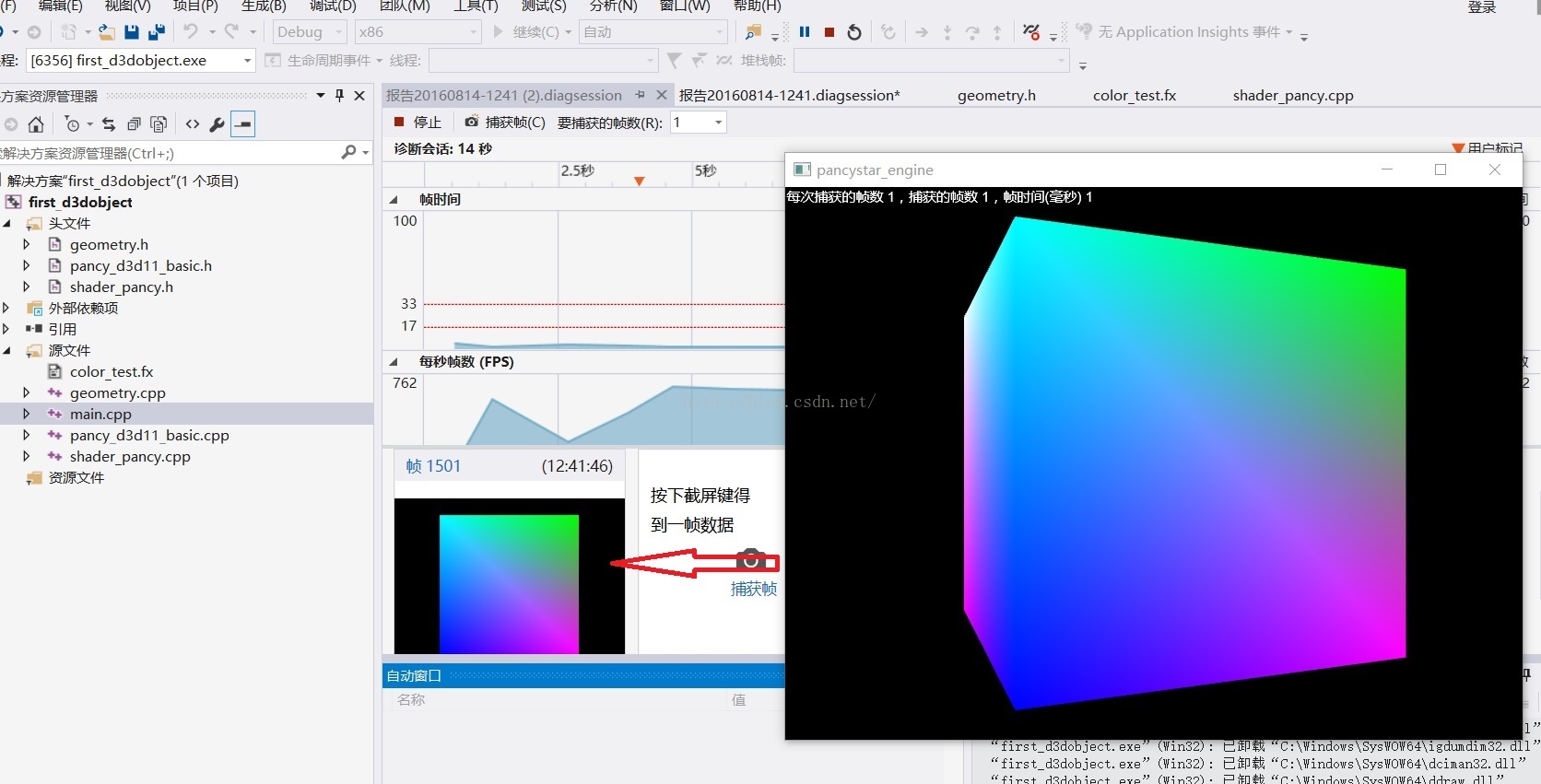
在上述介面中每按一次截圖就可以得到一幀的儲存資料,關閉程式後,點選剛才截圖得到的幀就可以開始這一幀的除錯:
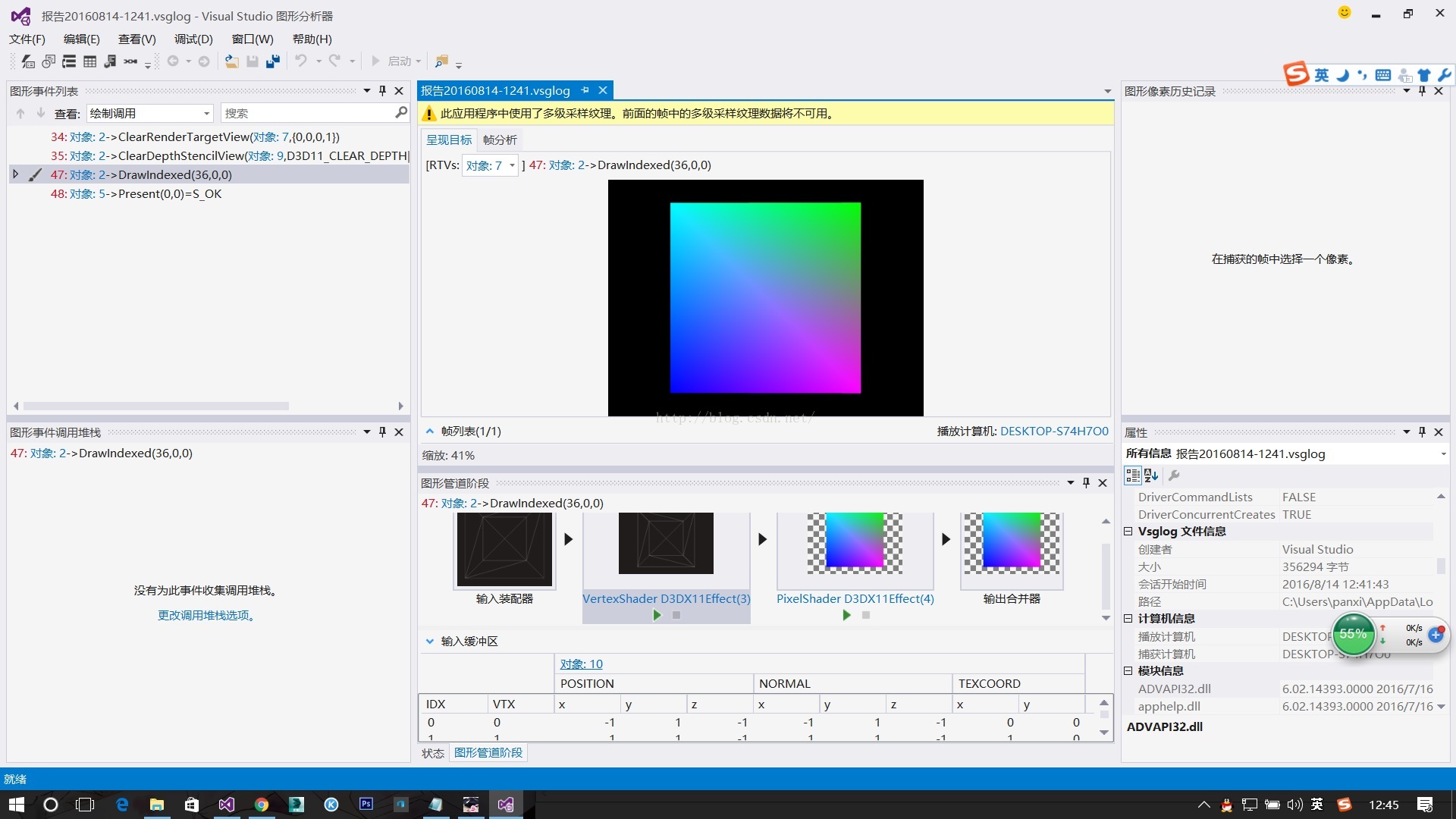
上述就是除錯的介面,對於一般的問題,大家可以在下面直接點選vertexshader或者pixelshader的執行來進行分步除錯。如果是需要針對某個畫素的話可以在圖上點選某個畫素之後,除錯它的的所有渲染過程:
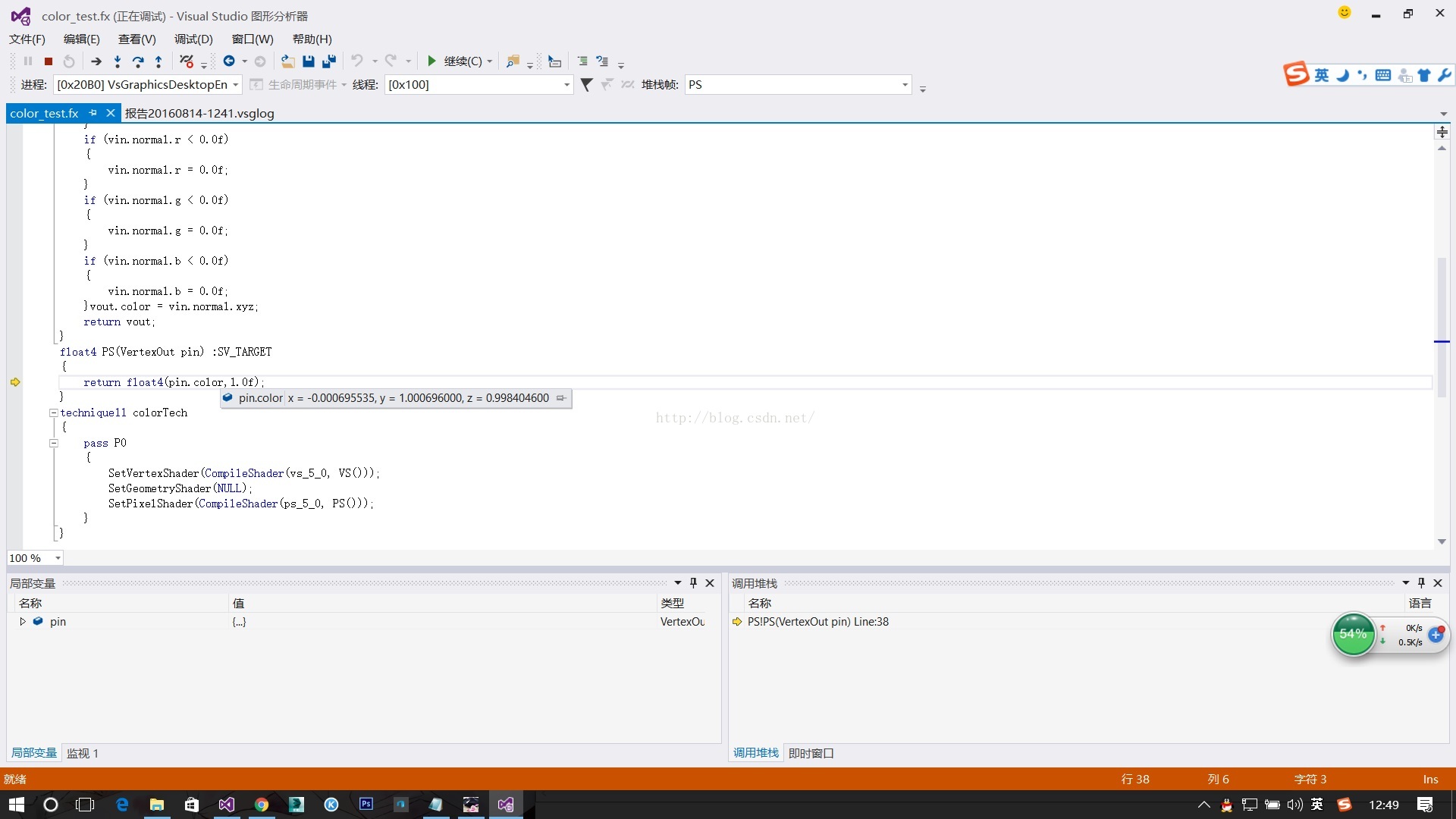
這個除錯工具極大的方便了我們來尋找GPU上程式的錯誤位置,大家以後再寫程式的時候如果遇到了一些渲染效果的錯誤就不需要再去猜測HLSL的錯誤了,直接在這個介面進行除錯就可以很快地尋找到shader的一些錯誤的地方。