
HashMap原始碼分析(基於JDK8)
HashMap簡介
HashMap基於雜湊表的 Map 介面的實現。此實現提供所有可選的對映操作,並允許使用 null 值和 null 鍵。(除了不同步和允許使用 null 之外,HashMap 類與 Hashtable 大致相同。)此類不保證對映的順序,特別是它不保證該順序恆久不變。
值得注意的是HashMap不是執行緒安全的,如果想要執行緒安全的HashMap,可以通過Collections類的靜態方法synchronizedMap獲得執行緒安全的HashMap。
Map map = Collections.synchronizedMap(new HashMap());
HashMap的資料結構
HashMap的底層主要是基於陣列和連結串列來實現的,它之所以有相當快的查詢速度主要是因為它是通過計算雜湊碼來決定儲存的位置。HashMap中主要是通過key的hashCode來計算hash值的,只要hashCode相同,計算出來的hash值就一樣。如果儲存的物件對多了,就有可能不同的物件所算出來的hash值是相同的,這就出現了所謂的hash衝突。學過資料結構的同學都知道,解決hash衝突的方法有很多,HashMap底層是通過連結串列來解決hash衝突的。 下面一幅圖,形象的反映出HashMap的資料結構:陣列加連結串列實現
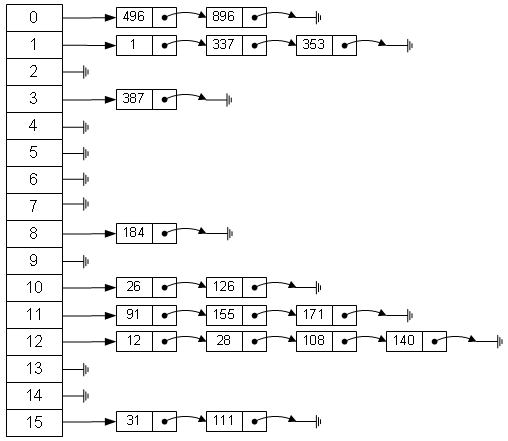
HashMap屬性
下面是一些比較重要的屬性,我們先預覽一下//樹化連結串列節點的閾值,當某個連結串列的長度大於或者等於這個長度,則擴大陣列容量,或者數化連結串列 static final int TREEIFY_THRESHOLD = 8; //初始容量,必須是2的倍數,預設是16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 //最大所能容納的key-value 個數 static final int MAXIMUM_CAPACITY = 1 << 30; //預設的載入因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; //儲存資料的Node陣列,長度是2的冪。 transient Node<K,V>[] table; //keyset 方法要返回的結果 transient Set<Map.Entry<K,V>> entrySet; //map中儲存的鍵值對的數量 transient int size; //hashmap 物件被修改的次數 transient int modCount; // 容量乘以裝在因子所得結果,如果key-value的 數量等於該值,則呼叫resize方法,擴大容量,同時修改threshold的值。 int threshold; //裝載因子 final float loadFactor;
構造方法
預設構造方法
預設構造方法將使用預設的載入因子(0.75)初始化。 public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}HashMap(int initialCapacity, float loadFactor)
使用指定的初始容量和預設的載入因子初始化HashMap,這裡需要注意的是,並不是你指定的初始容量是多少那麼初始化之後的HashMap的容量就是多大,例如new HashMap(20,0.8); 那麼實際的初始化容量是32,因為tableSizeFor()方法會嚴格要求把初始化的容量是以2的次方數成長只能是16、32、64、128... public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* 根據入參 返回2的指數 容量值
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}HashMap(int initialCapacity)
其實這個方法也是呼叫HashMap(int initialCapacity, float loadFactor) 方法實現的,我們來看看原始碼實現: public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}HashMap(Map<? extends K, ? extends V> m)
該方法是按照之前的hashMap的物件,重新深拷貝一份HashMap物件,使用的載入因子是預設的載入因子:0.75。 public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}put方法
執行邏輯: 1)根據key計算當前Node的hash值,用於定位物件在HashMap陣列的哪個節點。 2)判斷table有沒有初始化,如果沒有初始化,則呼叫resize()方法為table初始化容量,以及threshold的值。 3)根據hash值定位該key 對應的陣列索引,如果對應的陣列索引位置無值,則呼叫newNode()方法,為該索引建立Node節點 4)如果根據hash值定位的陣列索引有Node,並且Node中的key和需要新增的key相等,則將對應的value值更新。 5)如果在已有的table中根據hash找到Node,其中Node中的hash值和新增的hash相等,但是key值不相等的,那麼建立新的Node,放到當前已存在的Node的連結串列尾部。 如果當前Node的長度大於8,則呼叫treeifyBin()方法擴大table陣列的容量,或者將當前索引的所有Node節點變成TreeNode節點,變成TreeNode節點的原因是由於TreeNode節點組成的連結串列索引元素會快很多。 5)將當前的key-value 數量標識size自增,然後和threshold對比,如果大於threshold的值,則呼叫resize()方法,擴大當前HashMap物件的儲存容量。 6)返回oldValue或者null。put 方法比較經常使用的方法,主要功能是為HashMap物件新增一個Node 節點,如果Node存在則更新Node裡面的內容。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
} /**
* Implements Map.put and related methods
*
* @param key的hash值
* @param key值
* @param value值
* @param onlyIfAbsent如果是true,則不修改已存在的value值
* @param evict if false, the table is in creation mode.
* @return 返回被修改的value,或者返回null。
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//如果是第一次呼叫,則會呼叫resize 初始化table 以及threshold
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//如果對應的索引沒有Node,則新建Node放到table裡面。
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//如果hash值與已存在的hash相等,並且key相等,則準備更新對應Node的value
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果hash值一致,但是key不一致,那麼將新的key-value新增到已有的Node的最後面
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // 當某個節點的連結串列長度大於8,則擴大table 陣列的長度或者將當前節點連結串列變成樹節點連結串列
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
//hash值和key值相等的情況下,更新value值
e.value = value;
//留給LinkedHashMap實現
afterNodeAccess(e);
//返回舊的value
return oldValue;
}
}
//修改次數加1
++modCount;
//判斷table的容量是否需要擴充套件
if (++size > threshold)
resize();
//留給LinkedHashMap擴充套件
afterNodeInsertion(evict);
return null;
}上面呼叫到了一個resize方法, 我們來看看這個方法裡面做了什麼,實現邏輯如下:
1)如果當前陣列為空,則初始化當前陣列
2)如果當前table陣列不為空,則將當前的table陣列擴大兩倍,同時將閾值(threshold)擴大兩倍
陣列長度和閾值擴大成兩倍之後,將之前table陣列中的值全部放到新的table中去
/**
* 初始化,或者是擴充套件table 的容量。
* table的容量是按照2的指數增長的。
* 當擴大table 的容量的時候,元素的hash值以及位置可能發生變化。
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//當前table 陣列的長度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//當前的閾值
int oldThr = threshold;
int newCap, newThr = 0;
//如果table陣列已有值,則將其容量(size)和閾值(threshold)擴大兩倍
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // 當第一次呼叫resize的時候會執行這個程式碼,初始化table容量以及閾值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//將新的閾值儲存起來
threshold = newThr;
//重新分配table 的容量
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//將以前table中的值copy到新的table中去
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
} /**
* 如果table長度太小,則擴大table 的陣列長度
* 否則,將所有連結串列節點變成TreeNode,提高索引效率
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}get方法
根據key的hash值和key,可以唯一確定一個value,下面我們來看看get方法執行的邏輯
1)根據key計算hash值
2)根據hash值和key 確定所需要返回的結果,如果不存在,則返回空。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
} /**
* Implements Map.get and related methods
*
* @param key 的hash值
* @param key的值
* @return 返回由key和hash定位的Node,或者null
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // 如果索引到的第一個Node,key 和 hash值都和傳遞進來的引數相等,則返回該Node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) { //如果索引到的第一個Node 不符合要求,迴圈變數它的下一個節點。
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}containsKey方法
containsKey方法實際也是呼叫getNode方法實現的,如果key對應的value不存在則返回false public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}containsValue方法
containsValue方法的話需要遍歷物件所有的value,遇到value相等的,則返回true,具體實現如下
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}remove方法
執行邏輯: 1)根據key得到key的hash值 2)根據key 和hash值定位需要remove的Node 3) 將Node從對應的連結串列移除,然後再將Node 前後的節點對接起來 4)返回被移除 的Node 5)key-value的數量減一,修改次數加一 /**
* Implements Map.remove and related methods
*
* @param key的hash值
* @param key值
* @param 需要remove 的value,
* @param 為true時候,當value相等的時候才remove
* @param 如果為false 的時候,不會移動其他節點。
* @return 返回被移除的Node,或者返回null
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash && //如果定位到的第一個元素符合條件,則跳出if else
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {//定位到的第一個Node元素不符合條件,則遍歷其連結串列
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//移除符合要求的節點,將連結串列重新連線起來
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
//修改次數加1
++modCount;
//當前的key-value 對數減一
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
replace方法
replace(K key, V oldValue, V newValue)
根據key和value定位到Node,然後將Node中的value用新value 替換,返回舊的value,否則返回空。
public boolean replace(K key, V oldValue, V newValue) {
Node<K,V> e; V v;
if ((e = getNode(hash(key), key)) != null &&
((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {
e.value = newValue;
afterNodeAccess(e);
return true;
}
return false;
}replace(K key, V value)
根據key定位到Node,然後將Node中的value 替換,返回舊的value,否則返回空
public V replace(K key, V value) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) != null) {
V oldValue = e.value;
e.value = value;
afterNodeAccess(e);
return oldValue;
}
return null;
}clear方法
clear 方法將每個陣列元素置空 public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}