
Docker下的Kafka學習之一:製作叢集用的映象檔案
儘管之前寫過《Docker下kafka學習,三部曲》系列,但是單機版的入門練習並不滿足實際工作的需要,從本章起,我們一起來研究和探索Kafka這個優秀的非同步訊息系統,為實際工作積累更多的實戰經驗。
從映象製作開始
本章我們一起把kafka叢集用到的映象檔案做出來,後續的實踐都用這個映象來進行;
功能梳理
這個映象能提供哪些功能呢?
1. 可以ssh登入,這是為了後續操作方便;
2. jdk 1.8.0_144版本,因為zookeeper需要執行在jvm;
3. zookeeper-3.4.6;
4. kafka_2.9.2-0.8.1;
5. 把kafka_2.9.2-0.8.1/bin 加入到PATH中,這是為了後續執行kafka-topics.sh、kafka-console-producer.sh等命令時方便;
構造Dockerfile前準備的材料
本次構造Dockerfile所需的所有材料我已經上傳到github上了,地址是:[email protected]:zq2599/kafka_2.9.2-0.8.1-zookeeper-3.4.6.git,如下圖:
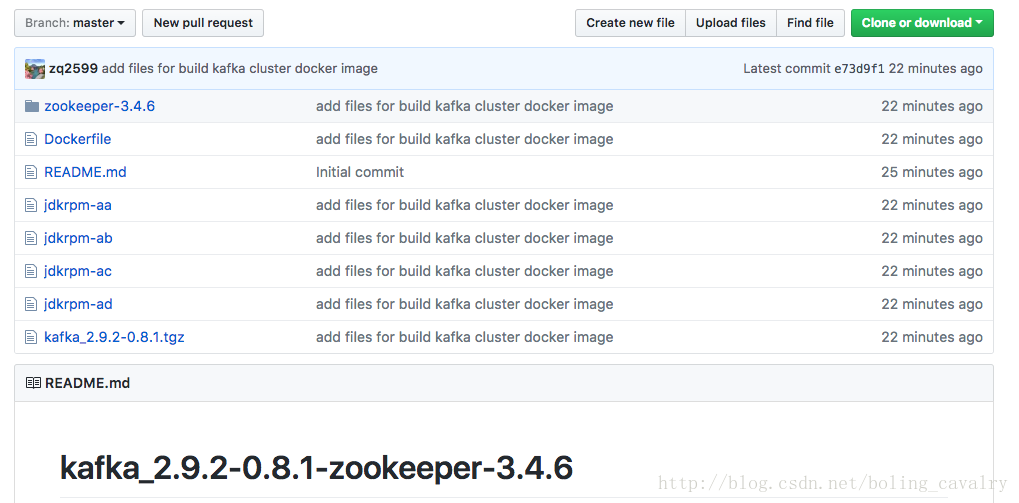
這裡簡單介紹一下這些材料:
1. jdk安裝檔案:linux版的jdk1.8檔案超過了一百兆,超過了github單個檔案50兆的限制,所以在linux或者mac上執行split -b 50m jdk-8u144-linux-x64.rpm jdkrpm-命令可以將此檔案分割成小檔案,如下圖:

如果您手裡只有windows,可以在docker上啟動一個linux容器,啟動的時候用-v建立檔案對映,這樣就能在這個linux容器裡面分割並同步到windows上了;
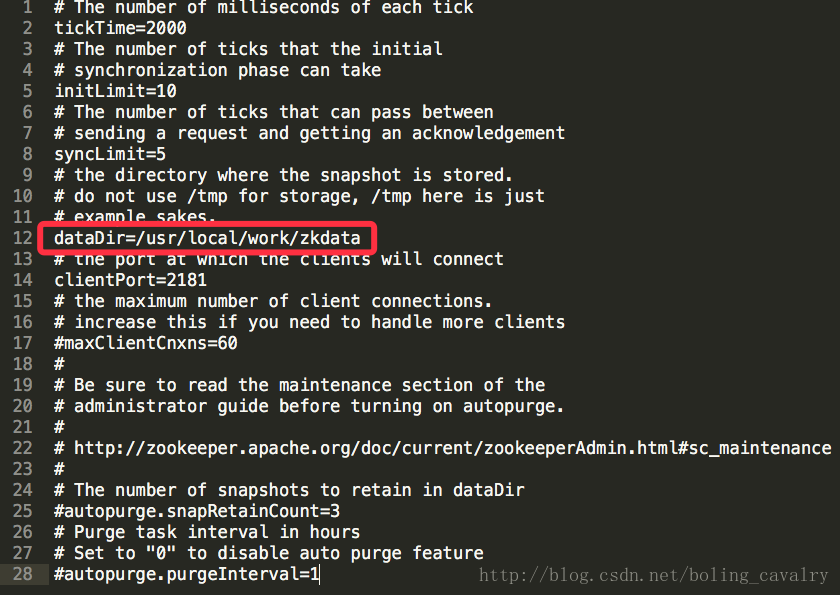
2. zookeeper-3.4.6,為了用了起來方便,我將壓縮包解壓開了,並且在conf目錄下建立了zoo.cfg檔案,裡面的內容和zoo_sample.cfg內容一樣,然後改了dataDir的配置,如下圖紅框所示:
3. kafka_2.9.2-0.8.1.tgz,官方下載的;
Dockerfile檔案內容
Dockerfile的內容如下所示,執行的是設定環境變數、安裝jdk、複製zookeeper,複製解壓kafka等,詳細說明請看每個命令的註釋部分:
# Docker image of kafka cluster
# VERSION 0.0.1
# Author: bolingcavalry
#基礎映象使用kinogmt/centos-ssh:6.7,這裡面已經裝好了ssh,密碼是password
FROM kinogmt/centos-ssh:6.7
#作者
MAINTAINER BolingCavalry <zq2599@gmail 構建映象
將之前準備好的材料和Dockerfile檔案放在同一個目錄下,如下圖:
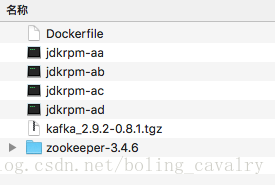
開啟命令列,進入Dockerfile所在目錄,執行如下命令:
docker build -t bolingcavalry/ssh-kafka292081-zk346:0.0.1 .ssh-kafka292081-zk346是我給這個映象起的名字,您可以按照自己想要修改,稍後執行完畢,輸入docker images命令就能看見最新構建的映象檔案了,如下圖:

在hub.docker.com上註冊過的讀者還可以執行以下命令將映象push到hub.docker.com上去,這樣其他使用者也可以用到您製作的映象了:
docker push bolingcavalry/ssh-kafka292081-zk346:0.0.1注意,如果要push到hub.docker.com上去,映象的名稱必須是您的賬號開頭加”/”,例如這裡的”bolingcavalry/ssh-kafka292081-zk346”,其中bolingcavalry就是我在hub.docker.com上的賬號;
至此,kafka叢集所需的映象檔案已經制作完畢,接下來的章節,我們會實踐在Docker下搭建kafka叢集環境;
相關推薦
Docker下的Kafka學習之一:製作叢集用的映象檔案
儘管之前寫過《Docker下kafka學習,三部曲》系列,但是單機版的入門練習並不滿足實際工作的需要,從本章起,我們一起來研究和探索Kafka這個優秀的非同步訊息系統,為實際工作積累更多的實戰經驗。 從映象製作開始 本章我們一起把kafka叢集用到的映象
Docker下RabbitMQ四部曲之一:極速體驗(單機和叢集)
從本章開始,我們一起在Docker環境實戰RabbitMQ環境部署和對應的Java開發,當前是《Docker下RabbitMQ四部曲》系列的第一篇,整個系列由以下四篇文章組成: 1. 第一篇,即本章,我們用最快的方式體驗RabbitMQ單機環境下生產和消費訊息
Docker下ELK三部曲之一:極速體驗
《Docker下ELK三部曲》一共三篇文章,為您揭示如何快速搭建ELK環境,以及如何將web應用的日誌上報到ELK用,三部曲內容簡述如下: 1. 極速體驗ELK服務,即本章的內容; 2. 細說技術詳情,例如集成了filebeat服務的映象如何製作,web應用
Docker學習之一:註冊Docker Hub賬號
現如今,Docker可謂是如日中天,使用Docker的人企業越來越多。Docker有很多優點,完美的解決了很多專案部署方面的問題。Docker主要優點: 1、Docker容器很快,啟動和停止秒級實現,對於傳統的來說可謂是致命的。 &nbs
2.docker學習筆記:製作docker映象
製作docker映象 構建映象的方式 上篇章節介紹瞭如何從docker hub上拉取映象,同時我們也可以製作映象上傳到docker hub上。 首先我們需要做一些準備工作: 2.登入docker hub: 可以選擇在官網進行登入,也可以使用
Linux學習之一:文件權限的查看和修改
span chmod 權限 文件權限 ... block img 中間 單獨 1、用戶的賬戶信息全部是放在etc文件下面。 2、文件權限 查看文件夾的權限:(ls -ld 文件夾名) 第2列:表文件的硬鏈接數(只有在Linux專有的) 第3列:表示所有者
kafka學習筆記:知識點整理
一個 eight true med 分組 pos 間接 fig ges 一、為什麽需要消息系統 1.解耦: 允許你獨立的擴展或修改兩邊的處理過程,只要確保它們遵守同樣的接口約束。 2.冗余: 消息隊列把數據進行持久化直到它們已經被完全處理,通過這一方式規避了數據
兩句話筆記--架構學習之一:並發基礎課程(2)
enc 之一 期望值 一致性 線程安全 原子性 每次 架構 地址 12,threadLocal,本身不提供所,而是在每個線程提供獨立的副本,來保證線程安全。13,volitile使用場景,使用場景,①有多線程同時操作該變量,②,這個變量是可變的。14,atomic使用時不保
C++11併發學習之一:小試牛刀
1.與C++11多執行緒相關的標頭檔案 C++11 新標準中引入了四個標頭檔案來支援多執行緒程式設計,他們分別是<atomic> ,<thread>,<mutex>,<condition_variable>和<future>。 <at
libevent學習之一:libevent原始碼的特點和結構
1.特點 Libevent是一個用於開發可擴充套件性網路伺服器的基於事件驅動(event-driven)模型的網路庫。Libevent有幾個顯著的特點: (1)事件驅動(event-driven),高效能; (2)輕量級,專注於網路,不如 ACE 那麼臃腫龐大; (3)原始碼
OpenStack學習之一:基礎環境準備
安裝Ubuntu14.04-server-amd64 (整個安裝過程如果沒有單獨截圖,則使用預設選項直接進行下一步。) 切換為中文,並回車: 選擇伺服器版,並回車: 先手工給eth0配置地址: 配置主機名為contr
大資料學習路線:Zookeeper叢集管理與選舉
大資料技術的學習,逐漸成為很多程式設計師的必修課,因為趨勢也是因為自己的職業生涯。在各個技術社群分享交流成為很多人學習的方式,今天很榮幸給我們分享一些大資料基礎知識,大家可以一起學習! 1.叢集機器監控 這通常用於那種對叢集中機器狀態,機器線上率有較高要求的場景,能夠快速對叢集中機器變化作出響
分散式快取學習之一:Memcached, Redis, MongoDB區別
Redis是一個開源(BSD許可),記憶體儲存的資料結構伺服器,可用作資料庫,快取記憶體和訊息佇列代理。 Memcached是一個自由開源的,高效能,分散式記憶體物件快取系統。 MongoDB是一個基於分散式檔案儲存的資料庫,文件型的非關係型資料庫,與上面兩者不同。 &nbs
六天搞懂“深度學習”之一:機器學習
一般來說,人工智慧、機器學習和深度學習是相互關聯的:“深度學習是一種機器學習,而機器學習是一種人工智慧。” 機器學習指的是人工智慧的特定領域,即,機器學習表示人工智慧的特定技術組成。機器學習是一種從“資料”中找出“模型”的技術。 深度學習是機器學習的一種技術。 深度學習近年來備受
虛擬機器學習之一:java記憶體區域與記憶體溢位異常
1.執行時資料區域 java虛擬機器在執行java程式的過程中會把它所管理的記憶體劃分為若干個不同的資料區域。這些區域都有各自的用途和建立、銷燬時間,有的區域伴隨虛擬機器程序的啟動而存在,有些區域則依賴使用者執行緒的啟動和結束而建立和銷燬。 1.1程式計數器 程式計數器
Kafka學習筆記:Kafka環境搭建
Kafka環境搭建 Kafka單機環境搭建 安裝必需 jdk,這裡使用的是jdk1.8 scala,需要獨立安裝scala,這裡使用的是scala 2.11.8 zookeeper,Kafka會自帶zk,但是最好使用獨立的 安裝步驟 1.將Kafka的tar包上傳
Kafka學習筆記:Kafka命令列工具
Kafka命令列工具 啟動Kafka kafka-server-start.sh /opt/software/kafka_2.11-1.1.0/config/server.properties & 檢視所有Topic列表 kafka-topics.sh --z
Docker實戰(二):容器使用和映象製作
執行容器 安裝好之後,我們就可以來開始Docker之旅了, 我們現在的Docker還是一個”裸”Docker,上面沒有容器,等一下,什麼式容器?所謂容器就是Docker中用來執行應用的,Docker的容器很輕量級,但功能卻強悍的很。也沒有映象。映象?映象簡單
Docker實戰(二):製作自己的Docker映象
製作自己的Docker映象 製作自己的Docker映象主要有如下兩種方式: 1.使用docker commit 命令來建立映象 通過docker run命令啟動容器修改docker映象內容docker commit提交修改的映象docker run新的映象 2.使用
vue學習之一:下載vue-cli專案
這幾週一直輾轉在vue官網和各大部落格搜尋關於vue專案實戰的例子。學的實在是零零碎碎的。不過總算在對於vue專案搭建有個基本認知,於是直接拿起以前做過的專案進行改版了,接下來是從怎麼搭建vue2.x+vue-router專案實戰寫的一些列文章。我的開發環境