
基於Alluxio,Mesos和Minio構建可擴充套件基因組資料處理流水線
本文由南京大學顧榮、姜茜翻譯整理自Alluxio公司技術部落格,由Alluxio公司授權CSDN首發(聯合),版權歸Alluxio公司所有,未經版權所有者同意請勿轉載。
Guardant Health在綜合液體活檢方面處於世界領先水平。腫瘤學家收集整理我們的血液測試結果來幫助確定他們的晚期癌症患者是否適合使用某些藥物,這些藥物只對特定的腫瘤DNA基因變異有效。每個測試產生大量的基因組資料,我們將其處理成易於解釋的測試結果。因此,我們需要一個端到端的資料處理方案:
- 在雲端和私有云上靈活部署:基因組資料是高度分佈的,涉及異構形式。我們需要靈活地將資料儲存在不同儲存系統的雲端和私有云上。Alluxio,Mesos和Minio提供靈活的部署,因為它們都是雲原生的應用,並且與許多儲存系統(如Amazon S3)相容。
- 可擴充套件性:基因組學是最大的資料生成領域之一。我們正致力於ExaByte規模的工作,因此可擴充套件性和價效比是重要的考慮因素。我們需要一種將計算與儲存分離的解決方案,這樣計算和儲存都可以獨立擴充套件。 在我們的解決方案中,Alluxio使這成為可能,下面將在文章中進一步解釋。
- 高效能:為了向醫護人員提供最及時的資訊,實現高效能的資料處理至關重要。我們以前的解決方案有一個基於磁碟的儲存系統,它無法滿足效能需求。不管我們的引擎能達到多快的速度,資料處理仍然受到底層儲存層的速度限制。即使引擎將資料彙集到本地記憶體中以克服I / O瓶頸,然而可用記憶體的總量仍然是一個限制因素。 Alluxio,Minio和Apache Spark都積極地利用分散式記憶體資源,與之前相比,我們在效能上能得到指數級的提升。
利用Alluxio,Mesos,Minio和Spark,我們建立了一個端到端的資料處理方案,它效能優異,可擴充套件,而且成本最優。 我們使用Alluxio作為統一的儲存層來連線不同的儲存系統,這帶來了記憶體上的優異表現。Minio作為Alluxio的底部儲存,以保持冷(不常訪問)資料,並將資料同步到AWS S3。 Apache Spark則作為計算引擎。
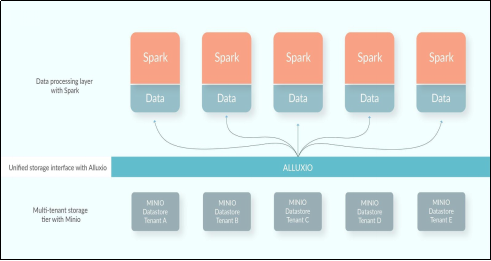
讓我們瞭解一下這些元件具體為平臺帶來了什麼。
Apache Mesos將CPU、記憶體、儲存和其他計算資源從機器(物理或虛擬)中抽取出來,使使用者能夠輕鬆有效地構建和執行能夠容錯和彈可擴充套件的分散式系統。
Minio是雲本地的AWS S3相容物件儲存伺服器。儘管儲存器一直被認為是複雜的,Minio使用了雲原生的容器友好的架構。部署Minio就像下載官方Docker Image和啟動
Minio專注於彈性、生產級的儲存,具有使用糾刪編碼、分散式模式和共享模式的位元衰減保護(bit rot protection)等功能。這將基礎架構與儲存脫鉤,使使用者能夠使用最新的容器組排技術。
現代應用需要不同的儲存系統來處理不同的資料型別。然而,隨著資料處理的發展,多儲存系統變得難以管理。要麼使用者需要將資料處理引擎與每個儲存系統整合在一起,從而將它們耦合得太緊密以進行獨立擴充套件;要麼資料需要首先被收集並傳輸到公共位置,這會增加開銷和處理時間。
Alluxio提供了一個統一檔案系統來解決此問題,它分佈在計算節點的本地儲存介質(理想情況下為RAM)。這意味著Alluxio建立了一個從儲存系統到計算節點的按需分配的流水線:使用者所有的資料都在一個名稱空間和一個介面中。
下面,我們將簡介所有元件並介紹如何配置它們。
1. 預先工作
2. 將Minio配置為Alluxio的底層儲存
要將Minio配置為Alluxio的底層儲存,開啟conf/alluxio-site.properties檔案並新增引數:
alluxio.master.hostname=localhost
alluxio.underfs.address=s3a://testbucket/test
alluxio.underfs.s3.endpoint=http://localhost:9000/
alluxio.underfs.s3.disable.dns.buckets=true
alluxio.underfs.s3a.inherit_acl=false
alluxio.underfs.s3.proxy.https.only=false請注意,使用者需要新增Minio伺服器終端,訪問金鑰和金鑰。 接下來,使用者需要格式化Alluxio日誌和從節點的儲存目錄,以備主節點和從節點啟動。 使用者可以這樣做:
./bin/alluxio format最後,啟動Alluxio:
./bin/alluxio-start.sh local3. 用Alluxio配置Spark
使用者需要使用Spark特定的配置檔案編譯Alluxio客戶端。為此,請使用以下命令從Alluxio根目錄構建整個專案:
mvn clean package -Pspark -DskipTests將以下語句新增到spark/conf/spark-defaults.conf。
spark.driver.extraClassPath /pathToAlluxio/core/client/target/alluxio-core-client-1.4.0-jar-with-dependencies.jar
spark.executor.extraClassPath /pathToAlluxio/core/client/target/alluxio-core-client-1.4.0-jar-with-dependencies.jar4. 叢集引數
上述架構已在生產中部署完畢,引數如下。
叢集大小:節點數50+,每個節點擁有約60個核和512 GB到1 TB的記憶體
Alluxio的RAM大小:>20 TB
Alluxio的HDD大小:>200 TB
Minio的資料庫儲存池 :~ 1.2 PB+(每天遞增)
5. 總結
我們的資料需求正在迅速增長,因此,高效能、可擴充套件性和成本可選性對於我們的基因組資料處理方案是至關重要的。 使用Alluxio、Mesos、Minio和Spark,我們能夠建立一個高效能、魯棒的且可擴充套件的系統,以雲原生的方式執行大規模資料處理。Minio提供了一個可擴充套件的、魯棒的多租戶儲存選項,可以在商用硬體上執行,Alluxio提供了一個統一的介面來管理所有資料,同時提供更多的效能提升,Spark利用Alluxio提供的記憶體資料來確保快速的資料處理。通過這種資料處理方案,我們有信心繼續提供解決方案來幫助醫護人員與癌症進行抗爭。
擴充套件閱讀: