
C++ string實現原理
C++程式設計師編碼過程中經常會使用string(wstring)類,你是否思考過它的內部實現細節。比如這個類的迭代器是如何實現的?物件佔多少位元組的記憶體空間?內部有沒有虛擬函式?記憶體是如何分配的?構造和析構的成本有多大?筆者綜合這兩天閱讀的原始碼及個人理解簡要介紹之,錯誤的地方望讀者指出。
首先看看string和wstring類的定義:
typedef basic_string<char, char_traits<char>, allocator<char> > string; typedef basic_string<wchar_t, char_traits<wchar_t> allocator<wchar_t> > wstring;
從這個定義可以看出string和wstring分別是模板類basic_string對char和wchar_t的特化。
再看看basic_string類的繼承關係(類方法未列出):
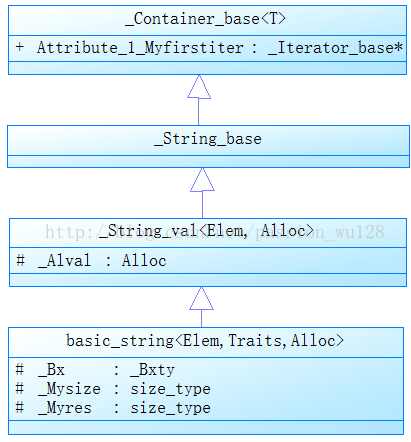
最頂層的類是_Container_base,它也是STL容器的基類,Debug下包含一個_Iterator_base*的成員,指向容器的最開始的元素,這樣就能遍歷容器了,並定義了了兩個函式
void _Orphan_all() const; // orphan all iterators void _Swap_all(_Container_base_secure&) const; // swaps all iterators
Release下_Container_base只是一個空的類。
_String_base類沒有資料成員,只定義了異常處理的三個函式:
static void _Xlen(); // report a length_error
static void _Xran(); // report an out_of_range error
static void _Xinvarg();上面三個基類都定義得很簡單,而basic_string類的實現非常複雜。不過它的設計和大多數標準庫一樣,把複雜的功能分成幾部分去實現,充分體現了模組的低耦合。
迭代器有關的操作交給_String_iterator類去實現,元素相關的操作交給char_traits類去實現,記憶體分配交給allocator類去實現。
_String_iterator類的繼承關係如下圖:

這個類實現了迭代器的通用操作,比如:
reference operator*() const;
pointer operator->() const
_String_iterator & operator++()
_String_iterator operator++(int)
_String_iterator& operator--()
_String_iterator operator--(int)
_String_iterator& operator+=(difference_type _Off)
_String_iterator operator+(difference_type _Off) const
_String_iterator& operator-=(difference_type _Off)
_String_iterator operator-(difference_type _Off) const
difference_type operator-(const _Mybase& _Right) const
reference operator[](difference_type _Off) const有了迭代器的實現,就可以很方便的使用演算法庫裡面的函數了,比如將所有字元轉換為小寫:
string s("Hello String");
transform(s.begin(), s.end(), s.begin(), tolower);
這個類定義了字元的賦值,拷貝,比較等操作,如果有特殊需求也可以重新定義這個類。
allocator類圖如下:
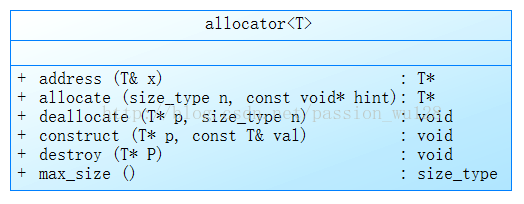
這個類使用new和delete完成記憶體的分配與釋放等操作。你也可以定義自己的allocator,msdn上有介紹哪些方法是必須定義的。
再看看basic_string類的資料成員:
_Mysize表示實際的元素個數,初始值為0;
_Myres表示當前可以儲存的最大元素個數(超過這個大小就要重新分配記憶體),初始值是_BUF_SIZE-1;
_BUF_SIZE是一個enum型別:
enum
{ // length of internal buffer, [1, 16]
_BUF_SIZE = 16 / sizeof (_Elem) < 1 ? 1: 16 / sizeof(_Elem)
};_Bxty是一個union:
union _Bxty
{ // storage for small buffer or pointer to larger one
_Elem _Buf[_BUF_SIZE];
_Elem *_Ptr;
} _Bx;為什麼要那樣定義_Bxty呢,看下面這段程式碼:
_Elem * _Myptr()
{ // determine current pointer to buffer for mutable string
return (_BUF_SIZE <= _Myres ? _Bx._Ptr : _Bx._Buf);
}所以當元素個數小於_BUF_SIZE時不用分配記憶體,直接使用_Buf陣列,_Myptr返回_Buf。否則就要分配記憶體了,_Myptr返回_Ptr。
不過記憶體分配策略又是怎樣的呢?看下面這段程式碼:
void _Copy(size_type _Newsize, size_type _Oldlen)
{ // copy _Oldlen elements to newly allocated buffer
size_type _Newres = _Newsize | _ALLOC_MASK;
if (max_size() < _Newres)
_Newres = _Newsize; // undo roundup if too big
else if (_Newres / 3 < _Myres / 2 && _Myres <= max_size() - _Myres / 2)
_Newres = _Myres + _Myres / 2; // grow exponentially if possible
//other code
}針對char和wchar_t,每次分配記憶體的臨界值分別是(超過這些值就要重新分配):
char:15,31,47,70,105,157,235,352,528,792,1188,1782。。。
wchar_t:7, 15, 23, 34, 51, 76, 114, 171, 256, 384, 576, 864, 1296, 1944。。。
重新分配後都會先將舊的元素拷貝到新的記憶體地址。所以當處理一個長度會不斷增長而又大概知道最大大小時可以先呼叫reserve函式預分配記憶體以提高效率。
string類佔多少位元組的記憶體空間呢?
_Container_base Debug下含有一個指標,4位元組,Release下是空類,0位元組。_String_val類含有一個allocator物件。string類使用預設的allocator類,這個類沒有資料成員,不過按位元組對齊的原則,它佔4位元組。basic_string類的成員加起來是24,所以總共是32位元組(Debug)或28位元組(Relase)。wstring也是32或28,至於原因文中已經分析。
綜上所述:string和wstring類藉助_String_iterator實現迭代器操作,都佔32(Debug)或28(Release)位元組的記憶體空間,沒有虛擬函式,構造和析構開銷較低,記憶體分配比較靈活。
實際使用string類時也有很多不方便的地方,筆者寫了一個擴充套件類,歡迎提出寶貴意見。