
java中常見集合類的遍歷
一、前言
我們經常在工作當中使用到集合,java當中的集合類較多,且自帶有豐富方法可對集合中的元素進行靈活操作,我們在使用時不必考慮資料結構和演算法實現細節,只需建立集合物件直接使用即可,這給我們帶來了極大的便利。本文對日常工作中常用的集合遍歷問題進行簡單總結。
二、java集合類圖
為了便於理解,這裡貼一張 java 集合類圖。(來自網路)
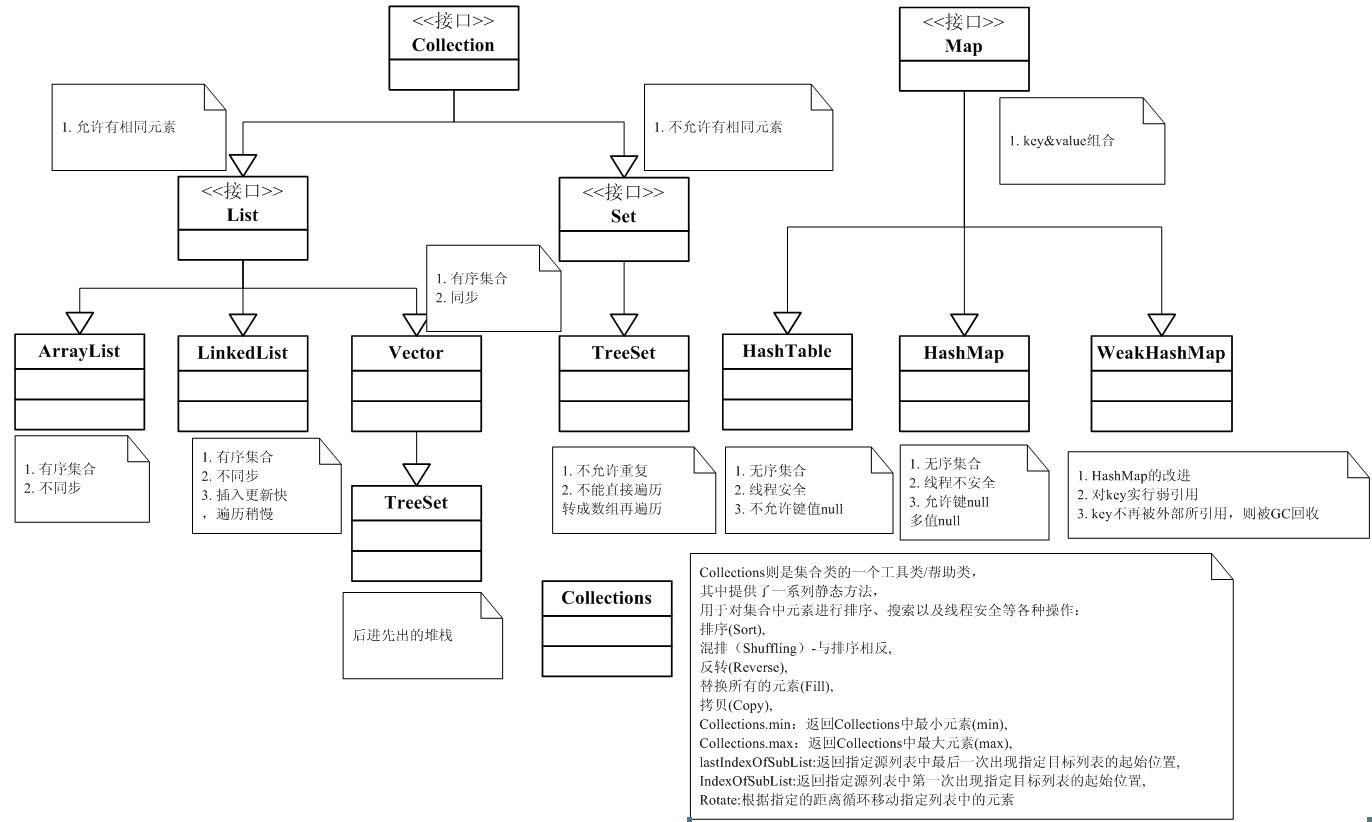
三、java常用集合遍歷
java中的集合類眾多,但我們常用的是ArrayList、HashMap、HashSet這幾個類,本文就一這3個類分別作為 List、Map、Set 這3類集合遍歷的例子。
1、ArrayList遍歷
例1:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* @desc 集合遍歷測試
*
* @author xiaojiang
*
*/
public class CollectionTest {
public static void main(String[] args) {
//初始化測試資料
List<String> dataList = new ArrayList<String>();
for 輸出:
//第1次
for迴圈遍歷,耗時(ms)->48
foreach遍歷,耗時(ms)->47
Iterator遍歷,耗時(ms)->50
//第2次
for迴圈遍歷,耗時(ms)->55
foreach遍歷,耗時(ms)->56
Iterator遍歷,耗時(ms)->55
//第3次
for迴圈遍歷,耗時(ms)->52
foreach遍歷,耗時(ms)->57
Iterator遍歷,耗時(ms)->54從上面結果可以初步發現:for迴圈方式使用方便一些,foreach方式的程式碼更簡潔一些,Iterator方式的方法更靈活一些(如:其可以在集合遍歷過程中 remove 元素);效能方面,對於 ArrayList 的遍歷,3種方式的效率差不多,其中“for迴圈”遍歷的方式略快一些。(注意:LinkedList 切勿用“for迴圈”方式,因為LinkedList資料結構決定了其獲取指定節點的元素相對較慢。)
2、HashMap遍歷
例2:
/**
* @desc 集合遍歷測試
*
* @author xiaojiang
*
*/
public class CollectionTest {
public static void main(String[] args) throws InterruptedException {
// 初始化測試資料
Map<String,Object> map = new HashMap<String, Object>();
for (int i = 0; i < 10000000; i++) {
map.put("key" + i, i);
}
//1、map.Entry()遍歷
long start_1 = System.currentTimeMillis();
for(Map.Entry<String, Object> entry : map.entrySet()){
//相關業務操作
//System.out.println(entry.getKey() + ":" + entry.getValue());
}
long end_1 = System.currentTimeMillis();
//2、Iterator遍歷
long start_2 = System.currentTimeMillis();
Iterator<Entry<String, Object>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> entry = iterator.next();
//相關業務操作
//System.out.println(entry.getKey() + ":" + entry.getValue());
}
long end_2 = System.currentTimeMillis();
//3、map.keySet()遍歷
long start_3 = System.currentTimeMillis();
for(String key:map.keySet()){
//相關業務操作
//System.out.println(key + ":" + map.get(key));
}
long end_3 = System.currentTimeMillis();
//4、map.values()遍歷獲取 value
long start_4 = System.currentTimeMillis();
for (Object value : map.values()) {
//相關業務操作
//System.out.println(":" + value);
}
long end_4 = System.currentTimeMillis();
//輸出
System.out.println("Map.Entry遍歷,耗時(ms)->" + (end_1 - start_1));
System.out.println("Iterator遍歷,耗時(ms)->" + (end_2 - start_2));
System.out.println("map.keySet()遍歷,耗時(ms)->" + (end_3 - start_3));
System.out.println("map.values()遍歷獲取 value,耗時(ms)->" + (end_4 - start_4));
}
}輸出:
//第1次
Map.Entry遍歷,耗時(ms)->195
Iterator遍歷,耗時(ms)->203
map.keySet()遍歷,耗時(ms)->236
map.values()遍歷獲取 value,耗時(ms)->237
//第2次
Map.Entry遍歷,耗時(ms)->187
Iterator遍歷,耗時(ms)->192
map.keySet()遍歷,耗時(ms)->225
map.values()遍歷獲取 value,耗時(ms)->215
//第3次
Map.Entry遍歷,耗時(ms)->182
Iterator遍歷,耗時(ms)->199
map.keySet()遍歷,耗時(ms)->214
map.values()遍歷獲取 value,耗時(ms)->213從上面結果可以初步發現:Map.Entry方式遍歷效率相對最高;Iterator方式的優點還是靈活;map.keySet()、map.values()這2種方式可分別對Map中所有的 key、value進行遍歷,其中map.keySet()方式可通過遍歷獲取的 key 再次取值獲取相應 value(這種方式獲取key、value的效率較低),這2種方式程式碼更簡潔些,適用於僅需遍歷所有 key 或所有 value 的場景。
3、HashSet遍歷
例3:
import java.util.HashSet;
import java.util.Iterator;
/**
* @desc 集合遍歷測試
*
* @author xiaojiang
*
*/
public class CollectionTest {
public static void main(String[] args) throws InterruptedException {
// 初始化測試資料
HashSet<String> set = new HashSet<String>();
for (int i = 0; i < 10000000; i++) {
set.add("data" + i);
}
// 1、foreach遍歷
long start_1 = System.currentTimeMillis();
for (String s : set) {
// 相關業務操作
String temp = s;
}
long end_1 = System.currentTimeMillis();
// 2、Iterator遍歷
long start_2 = System.currentTimeMillis();
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
// 相關業務操作
String temp = iterator.next();
}
long end_2 = System.currentTimeMillis();
// 3、先轉換成陣列,再遍歷
long start_3 = System.currentTimeMillis();
Object array[] = set.toArray();
for (int i = 0; i < array.length; i++) {
// 相關業務操作
String temp = (String)array[i];
}
long end_3 = System.currentTimeMillis();
// 輸出
System.out.println("foreach遍歷,耗時(ms)->" + (end_1 - start_1));
System.out.println("Iterator遍歷,耗時(ms)->" + (end_2 - start_2));
System.out.println("先轉換成陣列,再遍歷,耗時(ms)->" + (end_3 - start_3));
}
}輸出:
//第1次
foreach遍歷,耗時(ms)->171
Iterator遍歷,耗時(ms)->201
先轉換成陣列,再遍歷,耗時(ms)->279
//第2次
foreach遍歷,耗時(ms)->191
Iterator遍歷,耗時(ms)->194
先轉換成陣列,再遍歷,耗時(ms)->284
//第3次
foreach遍歷,耗時(ms)->197
Iterator遍歷,耗時(ms)->194
先轉換成陣列,再遍歷,耗時(ms)->287由以上可知 HashSet 的的遍歷和 ArrayList 的遍歷方法相近(ArrayList 其實也可以先轉成陣列再遍歷),均可通過 foreach 遍歷、Iterator遍歷,但 HashSet 不可通過“for迴圈”的方式遍歷,因為其沒有根據索引號獲取元素的方法。
四、總結
1、遍歷集合前需檢查集合是否為空,若為空會拋 java.lang.NullPointerException 異常。
2、在集合遍歷時,經常會涉及的一個問題是執行緒安全問題,如:
a、Vector和ArrayList相比,兩者功能類似,都繼承了AbstractList類,但Vector效率沒有ArrayList高,所以通常我們都使用ArrayList,而感覺Vector較陌生,不過,Vector是執行緒安全的而ArrayList是非執行緒安全的,所以,當多執行緒需要執行緒安全時,我們可以用Vector。
b、Hashtable 和 HashMap 也是功能相似,但Hashtable 是執行緒安全的而HashMap是非執行緒安全的,所以當需要執行緒安全時,可以用Hashtable 。
當然,ArrayList、HashMap也是可以通過Collections類中的Collections.synchronizedList(list)、Collections.synchronizedMap(m) 方法操作來達到執行緒安全的目的。
3、List、Map、Set等集合類的功能豐富,使用也常見,且靈活運用可給開發帶來較大的便利。
4、雖然理論上集合可以儲存大量資料(只要記憶體夠),但是也需儘量避免集合中的資料量過大,以避免JVM發生長時間GC的問題。