
Avro技術應用_2. 使用 Avro 來儲存大量小的二進位制檔案
大資料這個概念似乎意味著處理GB級乃至更大的檔案。實際上大資料可以是大量的小檔案。比如說,日誌檔案通常增長到MB級時就會存檔。這一節中將介紹在HDFS中有效地處理小檔案的技術。
假定有一個專案akin在google上搜索圖片,並將數以百萬計的圖片分別儲存在HDFS中。很不幸的是,這樣做恰好碰上了HDFS和MapReduce的瓶頸,如下:
- Hadoop的NameNode將所有的HDFS元資料儲存在記憶體中以加快速度。Yahoo估計平均每個檔案需要600位元組記憶體。那麼10億個檔案就需要60GB記憶體。對於當下的中端伺服器來說,60GB記憶體就顯得太多了。
- 如果MapReduce的資料來源是大量的文字檔案或可分割檔案,那麼map任務個數就是這些檔案佔據的 Block 的數量。如果MapReduce的資料來源是成千上百萬的檔案,那麼作業將會消耗大量的時間在核心中建立和銷燬map任務程序上。這些時間將會比實際處理資料的時間還要長。
- 如果在一個有排程器的受控環境中執行MapReduce作業,那麼map任務的個數可能是受到限制的。由於預設每個檔案都需要至少一個map任務,這樣就有可能因為任務過多而被排程器拒絕執行。
思考如下問題:檔案的大小和HDFS塊大小相比,大概是什麼比例?50%,70%,還是90%。如果大資料專案啟動後,又突然需要成倍地擴充套件需要處理的檔案。如果擴充套件僅僅需要增加節點,而不需要重新設計Hadoop過程,遷移檔案等,是不是很美妙的事情。思考這些問題並在設計階段及早準備是很有必要的。
Problem
需要處理HDFS中的大量檔案,同時又不能超出NameNode的記憶體限制。
Solution
最簡單的方案就是將HDFS中的小檔案打包到一個大的檔案容器中
Discussion
圖1中介紹了這個技術的第一部分,如何在HDFS中建立Avro檔案。這樣做可以減少HDFS中需要建立的檔案數量,隨之減少了NameNode的記憶體消耗。

圖1. 使用 Avro來儲存小檔案可以更好的利用記憶體並提高效率
Avro是由Hadoop之父Doug Cutting發明的資料序列化和PRC庫。主要用於提高Hadoop資料交換,通用性和版本控制的能力。Avro有著很強的架構模式演化能力,相比它的競爭對手如SequenceFiles等有更明顯的競爭優勢
讓我們來看看以下的JAVA程式碼如何建立Avro檔案.[1]
圖2 : 從目錄中讀取多個小檔案並在HDFS中生成一個單一的Avro檔案
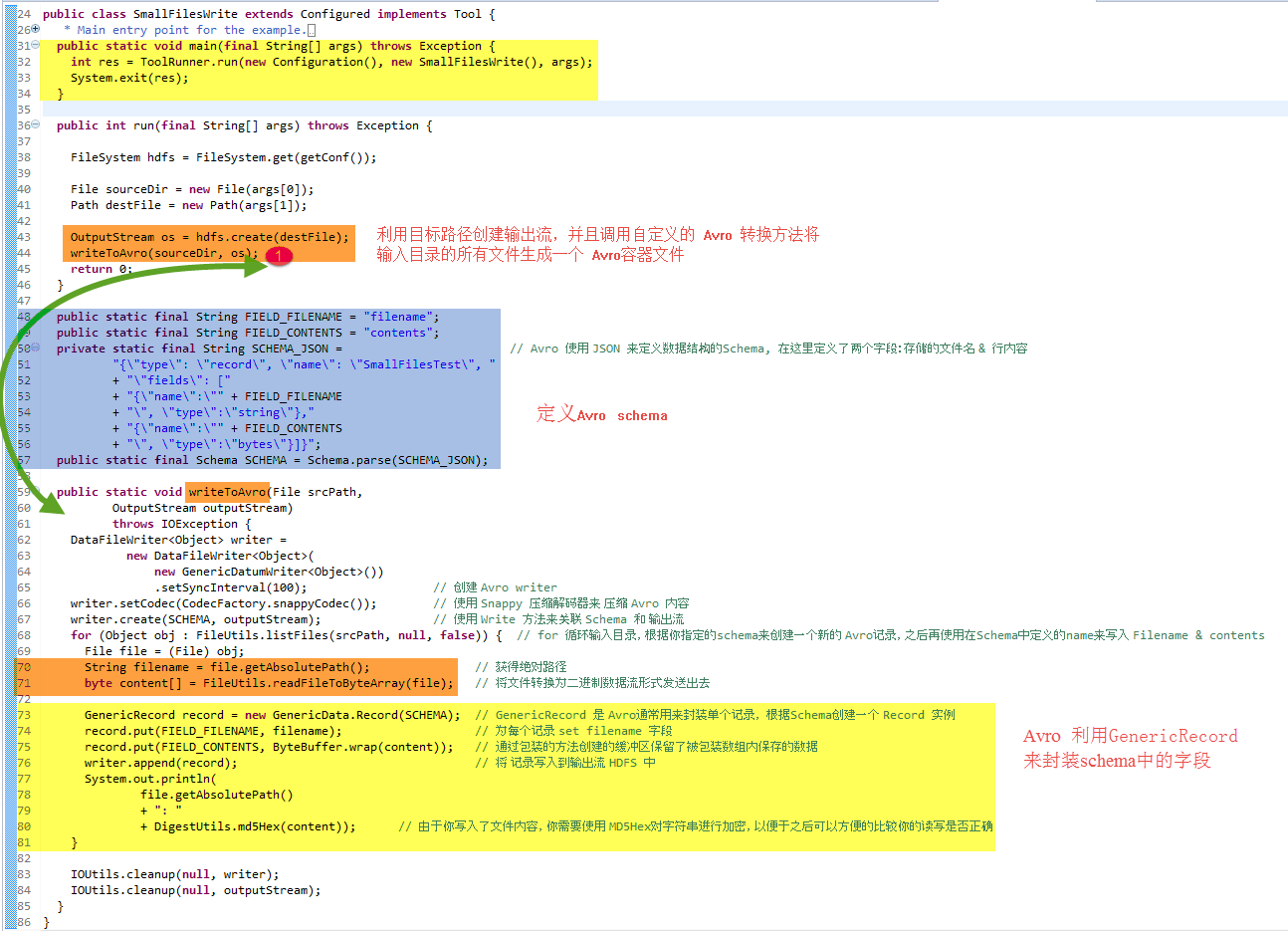
然後觀察這段程式碼以Hadoop的配置目錄作為資料來源的執行結果 (使用你當前 Hadoop 配置檔案路徑替換掉 $HADOOP_CONF_DIR 變數的值)
$ bin/run.sh \ com.manning.hip.ch5.SmallFilesWrite/etc/hadoop/conf test.avro /etc/hadoop/conf/ssl-server.xml.example: cb6f1b218... /etc/hadoop/conf/log4j.properties:6920ca49b9790cb... /etc/hadoop/conf/fair-scheduler.xml: b3e5f2bbb1d6c... ...
結果看起來還不錯。然後來確認HDFS中的輸出檔案:
$ hadoop fs -ls test.avro 2011-08-2012:38 /user/aholmes/test.avro
為了確保所有都和預期一樣,編寫程式碼讀取HDFS中的Avro檔案,並輸出每個檔案內容的MD5雜湊值。程式碼如下 : [2]
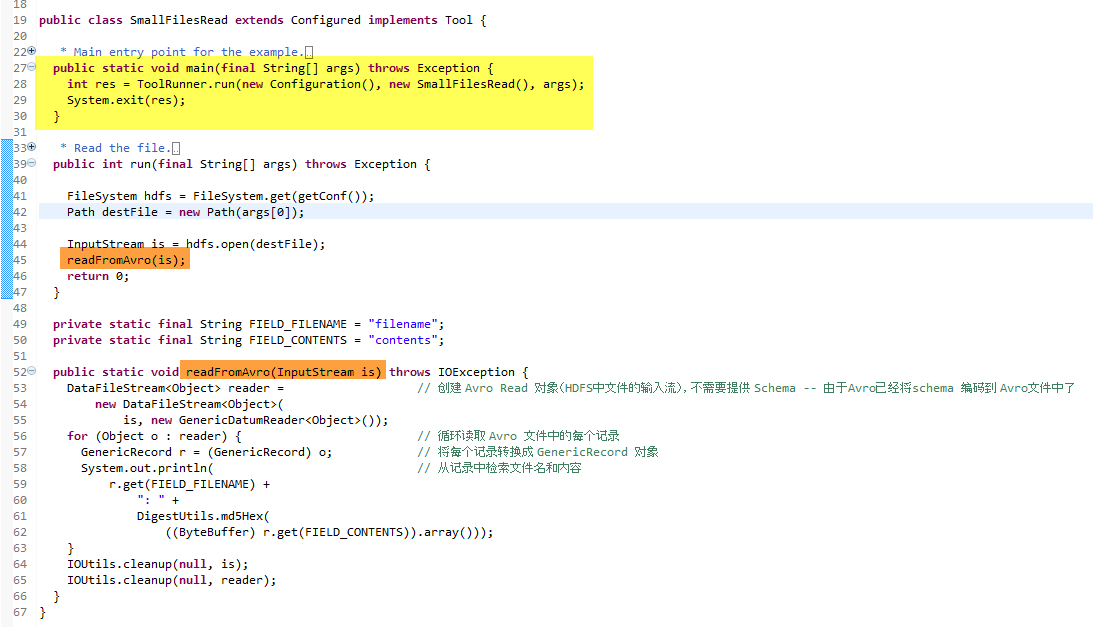
(結構模式) 寫入到每個 Avro 檔案中,在逆序列化的時候,不需要告訴Avro結構模式的資訊。現在來測試程式碼:
$ bin/run.sh com.manning.hip.ch5.SmallFilesRead test.avro /etc/hadoop/conf/ssl-server.xml.example: cb6f1b21... /etc/hadoop/conf/log4j.properties:6920ca49b9790c... /etc/hadoop/conf/fair-scheduler.xml: b3e5f2bbb1d6...

現在Avro檔案就被儲存在了HDFS中。下一步是用MapReduce處理檔案。如圖5.2所示,用一個只有Map的MapReduce作業讀取Avro記錄作為輸入,然後輸出一個包含有檔名和檔案內容的MD5雜湊值的文字檔案。如figure 4.3所示:
圖4. 利用 map job 來讀取 Avro檔案並且輸出一個 text 檔案
圖5. 一個以包含了多個小檔案的Avro檔案作為輸入源的MapReduce作業

$ bin/run.sh com.manning.hip.ch5.SmallFilesMapReduce test.avro output $ hadoop fs -cat output/part* /etc/hadoop/conf/capacity-scheduler.xml:0601a2.. /etc/hadoop/conf/taskcontroller.cfg:5c2c191420... /etc/hadoop/conf/configuration.xsl: e4e5e17b4a8... ...

總結:
也可以用Hadoop的 SequenceFile 來處理小檔案。SequenceFile是一個更成熟的技術,比Avro出現時間更長。但是SequenceFiles是JAVA專用的,相比Avro相比豐富的互動性和版本控制語義。
Google的Protocol Buffers和源自Facebook的Apache Thrift 都可以用來處理小檔案。但是缺乏相應的InputFormat來配合它們。
另外一個方法是將檔案打包成zip檔案。但其中的問題是,必須自定義InputFormat來處理zip檔案。同時zip檔案無法分塊。不過分塊問題可以通過打包成多個大小和HDFS塊相近的zip檔案。
Hadoop還提供了CombineFileInputFormat。它能夠讓一個單獨的map任務處理來自多個檔案的多個輸入塊,以極大地減少需要執行的map任務個數。
在類似的方法中,也可以在Hadoop中配置,使map任務的JVM可以處理多個任務,來減少JVM迴圈的開支。配置項mapred.job.reuse.jvm.num.tasks預設為1.這說明一個JVM只能處理一個任務。當它被配置為更大的數字的時候,一個JVM可以處理多個任務。-1則代表著處理的任務數量無上限。
此外,也可以建立一個tarball檔案來裝載所有的檔案,然後生成一個文字檔案描述HDFS中的tarball檔案的位置資訊。文字檔案將會被作為MapReduce作業的輸入源。Map任務將會直接開啟tarball。但是這種方法將會損害MapReduce的本地性。也就是說,map任務需要在包含那個文字檔案的節點上執行,然而包含tarball檔案的HDFS很可能在另外一個節點上,這就增加了網路IO的成本。
Hadoop打包檔案(HAR)是Hadoop專用於解決小檔案問題的檔案。它是基於HDFS的虛擬檔案系統。HAR的缺陷在於無法優化MapReduce的本地磁碟訪問效能,而且無法被壓縮。
Hadoop 2.x版本支援HDFS聯合機制。在HDFS聯合機制中,HDFS被分割槽成多個不同的名字空間,由不同的NameNode分別管理。然後,NameNode的快資訊快取的記憶體壓力可以由多個NameNode共同承擔。最終支援了更大數量的小檔案。Hortonworks有一片關於HDFS聯合機制的部落格:http://hortonworks.com/an-introduction-to-hdfs-federation/。
最後一個方法是MapR。MapR擁有自己的分散式檔案系統,支援大量的小檔案。但是,應用MapR作為分散式儲存系統將會帶來很大的系統變更。也就是說,幾乎不可能通過應用MapR來解決HDFS中的小檔案問題。
在Hadoop中有可能多次碰到小檔案的問題。直接使用小檔案將會使NameNode的記憶體消耗迅速增大,並拖累MapReduce的執行時間。這個技術可以幫助緩解這個問題,通過將小檔案打包到更大的容器檔案中。選擇Avro的原因是,它支援可分塊檔案,壓縮。Avro的結構模式語言有利於版本控制。
假定需要處理的不是小檔案,而是超大檔案。那麼應當如何有效地儲存資料?如何在Hadoop中壓縮資料?MapReduce中應當如何處理?這些內容將會在後續進行介紹