HDFS無法高效儲存大量小檔案,如何處理好小檔案?
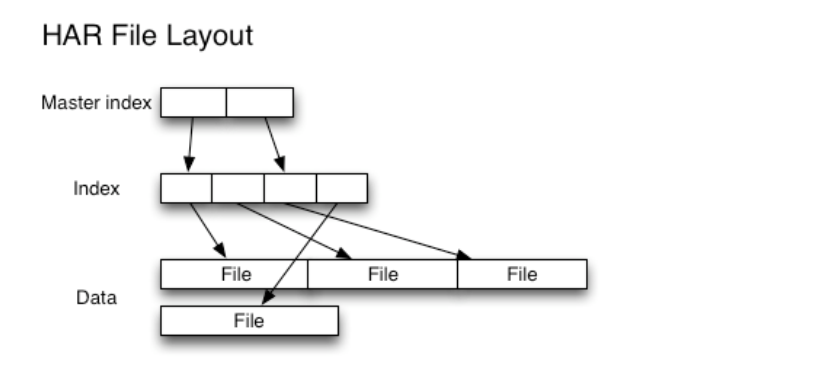
一、HAR檔案方案
為了緩解大量小檔案帶給namenode記憶體的壓力,Hadoop 0.18.0引入了Hadoop Archives(HAR files),其本質就是在HDFS之上構建一個分層檔案系統。通過執行hadoop archive 命令就可以建立一個HAR檔案。在命令列下,使用者可使用一個以har://開頭的URL就可以訪問HAR檔案中的小檔案。使用HAR files可以減少HDFS中的檔案數量。
下圖為HAR檔案的檔案結構,可以看出來訪問一個指定的小檔案需要訪問兩層索引檔案才能獲取小檔案在HAR檔案中的儲存位置,因此,訪問一個HAR檔案的效率可能會比直接訪問HDFS檔案要低。對於一個mapreduce任務來說,如果使用HAR檔案作為其輸入,仍舊是其中每個小檔案對應一個map task,效率低下。所以,HAR files最好是用於檔案歸檔。
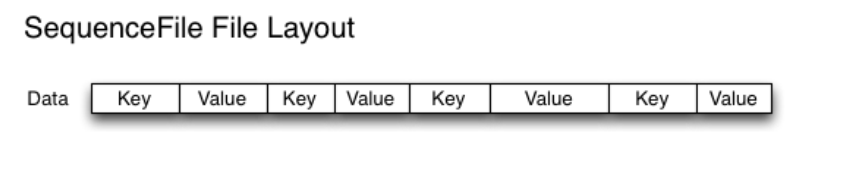
二、Sequence Files方案
除了HAR files,另一種可選是SequenceFile,其核心是以檔名為key,檔案內容為value組織小檔案。10000個100KBde 小檔案,可以編寫程式將這些檔案放到一個SequenceFile檔案,然後就以資料流的方式處理這些檔案,也可以使用MapReduce進行處理。一個SequenceFile是可分割的,所以MapReduce可將檔案切分成塊,每一塊獨立操作。不像HAR,SequenceFile支援壓縮。在大多數情況下,以block為單位進行壓縮是最好的選擇,因為一個block包含多條記錄,壓縮作用在block智商,比reduce壓縮方式(一條一條記錄進行壓縮)的壓縮比高。
把已有的資料轉存為SequenceFile比較慢。比起先寫小檔案,再將小檔案寫入SequenceFile,一個更好的選擇是直接將資料寫入一個SequenceFile檔案,省去小檔案作為中間媒介。
下圖為SequenceFile的檔案結構。HAR files可以列出所有keys,但是SequenceFile是做不到的,因此,在訪問時,只能從檔案頭順序訪問