
【Transact-SQL】SQL Server自動把left join自動轉化為inner join、以及關聯時的資料重複問題
阿新 • • 發佈:2019-01-29
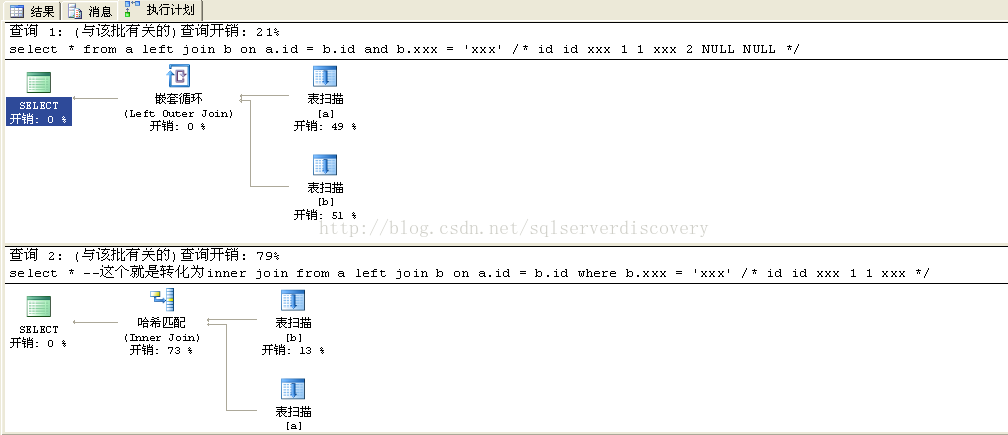
1、SQL Server自動把left join自動轉化為inner join的問題:
下面的兩個語句都是left join的,但是一個卻轉化成了 inner join
drop table a,B go create table a(id int) insert into a select 1 union all select 2 create table b(id int,xxx varchar(10)) insert into b select 1,'xxx' union all select 2,'xx' go --這個還是left join select * from a left join b on a.id = b.id and b.xxx = 'xxx' /* id id xxx 1 1 xxx 2 NULL NULL */ select * --這個就是轉化為inner join from a left join b on a.id = b.id where b.xxx = 'xxx' /* id id xxx 1 1 xxx */
下面的圖是執行計劃:
2、下面的語句,執行後會出來幾條記錄呢?
select*
from
(
select 1 as id
)a
left join
(
select 1 as id
union all
select 1
)b
on a.id = b.id
left join
(
select 1 as id
union all
select 1
)c
on a.id = c.id
之所以會想到這個問題,是因為發現最近寫的報表總是執行結果不對,數字偏大,報表的邏輯要比上面的語句複雜,但問題是一樣的。
首先,查詢結果要求出來明細資料,由於表a關聯了表b,
看上去和笛卡爾積一樣2*2 = 4,但其實是由於表b和表c都有重複記錄,導致關聯以後出現大量的重複資料,這個問題在寫SQL語句的時候,一定要非常注意。
如果來解決這個問題呢?
一般可以先單獨對有重複資料表進行去重,或者group by並按照需求進行聚合計算,然後再進行關聯,這樣就不會導致數字偏大。