
VS2012中用cout輸出float和double型別資料
今天在用C++程式設計的時候,發現用cout輸出的float和double型別精度有問題
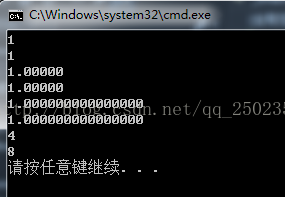
float fTest=1;
double dTest=1;
cout<<fTest<<endl;
cout<<dTest<<endl;
cout<<showpoint<<fTest<<endl<<showpoint<<dTest<<endl;
cout<<showpoint<<setprecision(16)<<fTest<<endl<<showpoint<<setprecision(16)<<dTest<<endl;
cout<<sizeof(fTest)<<endl;
cout<<sizeof(dTest)<<endl;
執行效果如下
相關推薦
VS2012中用cout輸出float和double型別資料
今天在用C++程式設計的時候,發現用cout輸出的float和double型別精度有問題 float fTest=1; double dTest=1; cout<<fTest<<endl; cout<<dTest<<endl;
java 中float和double型別資料取值詳解
1、定義標準 IEEE754 在IEEE754標準中進行了單精度浮點數(float)和雙精度數浮點數(double)的定義。 float有32bit,double有64bit。它們的構成包括符號位
C/C++ 關於float和double型別與二進位制的轉換實現。。
void FloatToString(float fNum,char *pStr) { unsigned int nData = ((unsigned int *)&fNum)[0]; for (int i = 0;i < 32;i ++) {
printf中用%d輸出float或者double
首先說一個“預設引數提升”的概念: If the expression that denotes the called function has a type that does include a prototype, the arguments are implicit
java中的float和double型別
1、float 單精度、8位有效數字、第8位四捨五入(第九位大於等於3則進一位) 2、double 雙精度、17位有效數字 ======================================
float和double型別的記憶體分佈和比較方法
C/C++的浮點資料型別有float和double兩種。 型別float大小為4位元組,即32位,記憶體中的儲存方式如下: 符號位(1 bit) 指數(8 bit) 尾數(23 bit) 型別double大小為8位元組,即64位,記憶體佈局如下: 符號位
深入理解C++浮點數(float、double)型別資料比較、相等判斷
浮點數在記憶體中的儲存機制和整型數不同,其有舍入誤差,在計算機中用近似表示任意某個實數。具體的說,這個實數由一個整數或定點數(即尾數)乘以某個基數(計算機中通常是2)的整數次冪得到,這種表示方法類似於基數為10的科學記數法。所以浮點數在運算過程中通常伴隨著因為無法精確表示
C++浮點數(float、double)型別資料比較
浮點數在記憶體中的儲存機制和整型數不同,其有舍入誤差,在計算機中用近似表示任意某個實數。具體的說,這個實數由一個整數或定點數(即尾數)乘以某個基數(計算機中通常是2)的整數次冪得到,這種表示方法類似於基數為10的科學記數法。所以浮點數在運算過程中通常伴隨著因為無法精確表示而進行
基本資料型別操作三:float和double變數的賦值
拿賦零值做舉例,給float型變數賦零值有以下幾種方式: float a; a = 0; a = 0.; a = 0.0; a = 0.f; a = 0.0f;首先這幾種賦值方式都是可行的。0是整型,0.和0.0都是double型,0.f和0.0f是fl
Java中float和double轉換的問題
leg throw exceptio int row 如何 方法 避免 stat 為什麽double轉float不會出現數據誤差,而float轉double卻誤差如此之大? double d = 3.14; float f = (float)d; Syst
分別顯示用float和double指數記數法所能代表的最大和最小數字
java中指數記數法是指用大寫的E來替代10的一種計數方式,如:1.4E-45 就表示 1.4*10^(-45),也就是1.4乘10的-45次方。 指數記數法已經瞭解了,那麼float和double所能代表的最大和最小數怎麼求呢?沒關係,在它們對應的包裝器型別中,已經定義好了對應的屬性:
float和double的數值怎麼儲存在二進位制中
稍微淺學過二進位制的人,都清楚二進位制是個什麼東西。我們都瞭解正整數是怎麼轉化成二進位制的,那麼計算機中,又是怎麼儲存folat,double型別的數值的呢? 要像弄清楚這個問題,首先得清楚二進位制是怎麼表示小數的。(這一點請注意了) 十進位制是怎麼表示小數的呢? 比如,125.456&
關於float和double計算精度缺失解決方法筆記
最近在專案中的財務管理模組遇到一個問題就是資料庫欄位建的型別是float,在計算後會引起精度缺失問題 拋開資料庫建立的不當以外,遇到這個問題的解決方法如下: 例子: public static void main(String[] args) { // TODO Auto-gene
c語言float,double型別的理解
float:1bit(符號位)+8bit(指數位,範圍-128~127)+23bit(尾數位) double:1bit + 11bit + 52bit 例:8.25(十進位制) -----> 1000.01(二進位制) //1x2^3 +1x2^(-2)=8.2
為什麼不能夠用unsigned 修飾 float和double
最近犯了一個錯誤: 定義變數型別的時候竟然定義了unsigned double的型別。由於編譯能夠通過,因此一直沒有發現這樣寫會有什麼樣的問題。 今天一次偶然的測試中發現這些變數的值都是整數。一開始覺得奇怪,明明是浮點數,怎麼變成整型了? 後來上網查了一下資料: 原
float和double的精度計算
Java浮點數的取值範圍與其精度,必須先了解浮點數的表示方法,浮點數的結構組成:由符號位,指數位,尾數位組成。 Java中浮點數採用的是IEEE 754標準。 一個float4位元組32位,分為三部分:符號位,指數位,尾數位 符號位(S):最高位(31位)為符號
深入理解C 浮點數 float double 型別資料比較 相等判斷
浮點數在記憶體中的儲存機制和整型數不同,其有舍入誤差,在計算機中用近似表示任意某個實數。具體的說,這個實數由一個整數或定點數(即尾數)乘以某個基數(計算機中通常是2)的整數次冪得到,這種表示方法類似於基數為10的科學記數法。所以浮點數在運算過程中通常伴隨著因為無法精確表示而進行
java 小心使用float和double他可能不如你所想
public static void main(String[] args) { double funds=1.00; int itemBought=0; // double price=.1; for(price=.1;funds
double型別資料做加和操作時會丟失精度問題處理
double型別的資料做加和操作 時會丟失精度,如下操作結果為: int a = 3; double b = 0.03; double c = 0.03; double d = a + b + c;
Android學習之byte陣列和double型別之間的轉換
在java中,一個byte元素佔一個位元組,一個double型別資料佔8個位元組 double 轉 byte陣列,程式碼: //double轉byte陣列 double佔8位元組 , 一個byte佔一個位元組 public static byte[] Do